图示详解BERT模型的输入与输出
Posted gczr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图示详解BERT模型的输入与输出相关的知识,希望对你有一定的参考价值。
一、BERT整体结构
BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务。整体架构如下图:
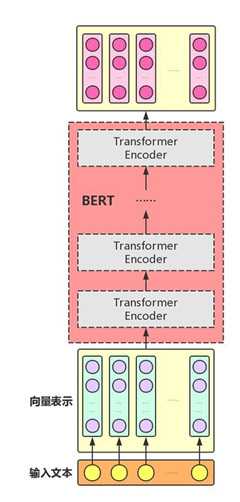
多个Transformer Encoder一层一层地堆叠起来,就组装成了BERT了,在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
二、再次理解Transformer中的Attention机制。
Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表示这一角度来理解一下Attention机制。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,我们可能会觉得很陌生(甚至连读音是什么都不记得吧),而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重(最终形成每个目标字与其上下文的字的权重关系,权重和为1),加权融合目标字的Value向量和各个上下文字的Value向量(其实就是做了点乘),作为Attention的输出,即:目标字的增强语义向量表示。
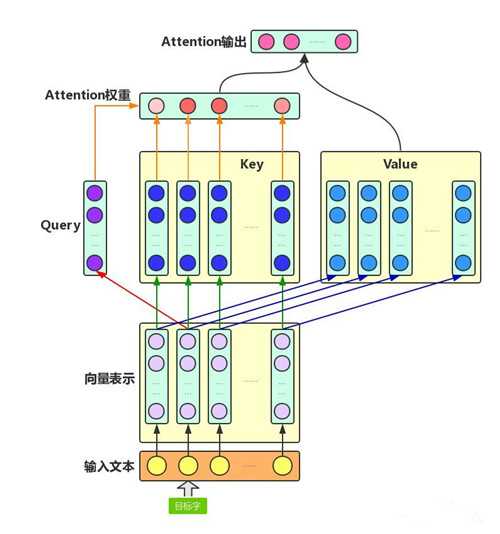
图示展示了第二个字,即目标字的整个Attention计算流程。
三、BERT的预训练结构
BERT实际上是一个语言模型。语言模型通常采用大规模、与特定NLP任务无关的文本语料进行训练,其目标是学习语言本身应该是什么样的。BERT模型其预训练过程就是逐渐调整模型参数,使得模型输出的文本语义表示能够刻画语言的本质,便于后续针对具体NLP任务作微调。
1、Masked LM
Masked LM的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示
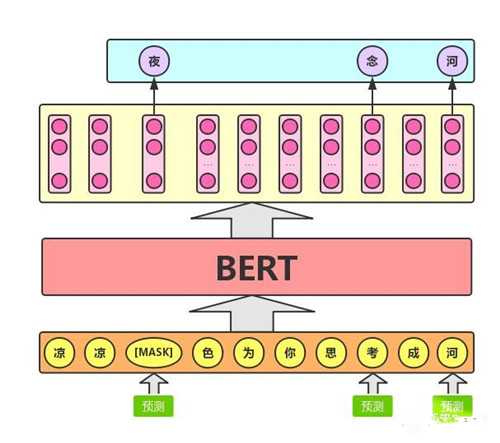
具体来说,文章作者在一句话中随机选择15%的词汇用于预测。对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
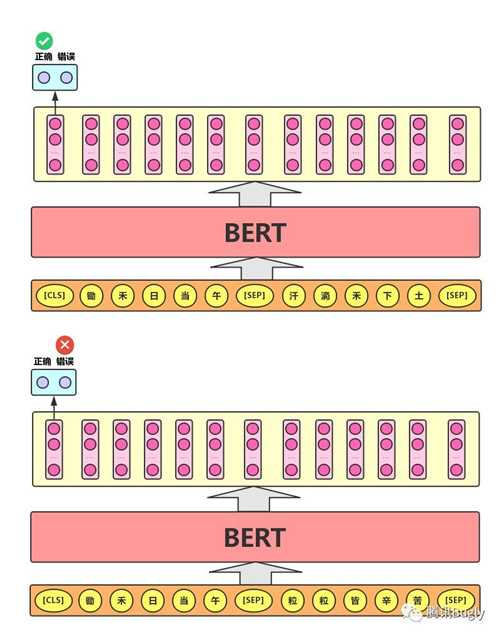
2、NextSentence Prediction
任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示:
四、BERT的整体输入/输出
BERT模型预训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
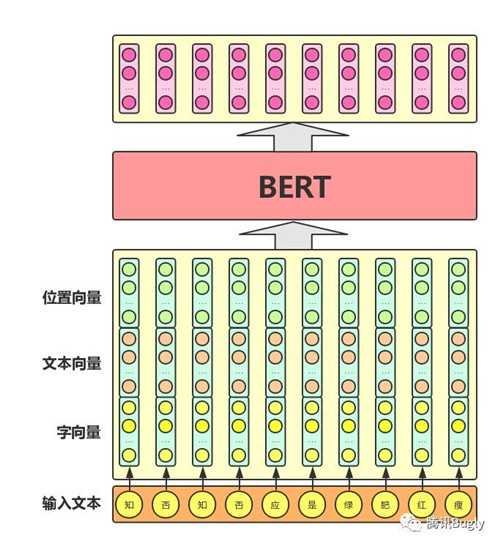
从上图中可以看出,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:
1. 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
2. 位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和##ing;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
五、具体NLP任务上的fine-tune
在具体的NLP任务上,BERT模型的输入输出会有细微的差别。
1)文本分类任务
2)语句对分类任务
3)序列标注任务
以上是关于图示详解BERT模型的输入与输出的主要内容,如果未能解决你的问题,请参考以下文章