京东消息中间件JMQ(转)
Posted perfei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东消息中间件JMQ(转)相关的知识,希望对你有一定的参考价值。
http://blog.csdn.net/javahongxi/article/details/54411464
[京东技术]京东的MQ经历了JQ->AMQ->JMQ的发展,其中JQ的基于关系数据库,严格意义上讲称不上消息中间件,JMQ的存储是JFS和HBase,AMQ即ActiveMQ,本文说说JMQ。
JMQ是京东自主研发的一款消息中间件系统,具有高可用、数据高可靠等特性。广泛应用于公司内部系统,包括订单、支付、库房等场景。
整体结构
系统包括服务端、客户端、管理端与其他支撑模块。
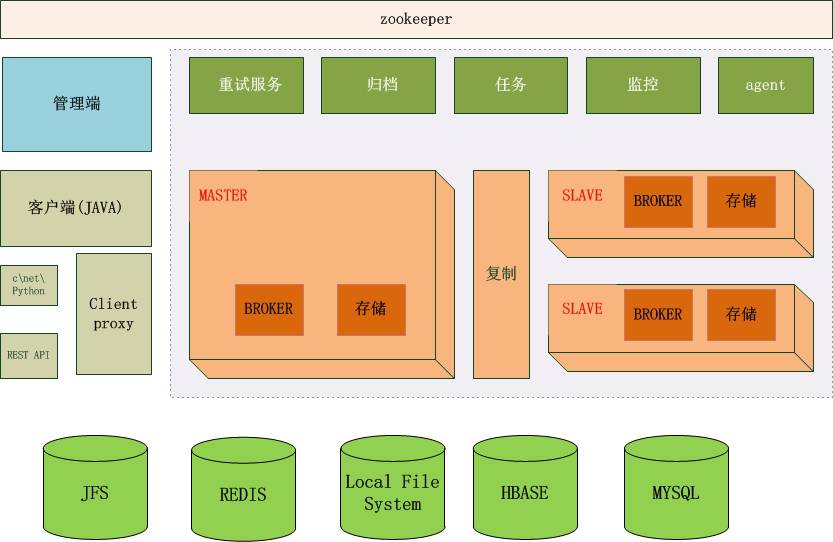
详细架构

AMQ

JMQ
服务端
服务端提供了配置信息分发、重试消息管理和消息存储与分发这三大类功能。每个服务端实例都具备这三类功能的服务能力,但是在实际部署上这三类功能对应三个不同的集群,对应每一个实例功能不叠加。在测试环境和库房等资源有限的环境下,这三类功能由同一个服务端实例提供服务。
配置信息分发:负责客户端参数变更时与消息分配的服务端实例变更时通知客户端。
重试消息管理:主要用于对业务系统临时处理不了的消息进行存放,然后再按照一定的策略投递给客户端处理。可以提供错误原因、错误处理次数等查询。
消息存储与分发:接收生产者投递的消息,把消息存放在本地磁盘上,消费者从该服务上拉取消息进行消费。
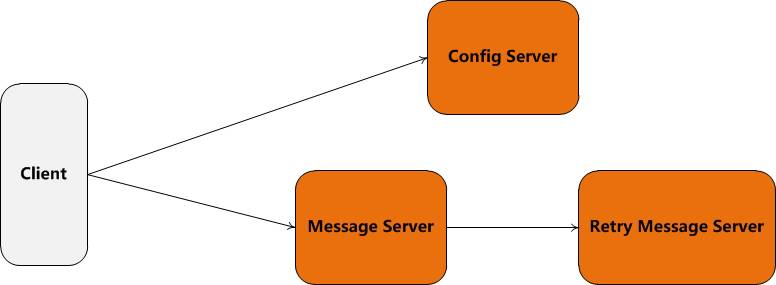
客户端
目前只提供了JAVA语言的SDK和支持HTTP协议的proxy,非JAVA语言通过proxy接入。
管理端
主要功能有:接入申请、消息元数据管理、重试消息信息查询、消息发送和消费日志查询、服务端状态信息管理查看、客户端连接信息管理查看等。
支撑模块
主要有报警模块、任务模块、归档模块、信息采集模块等。
数据可靠性
针对公司的业务特点,消息服务主要应用于订单、支付、物流等环节。服务端采用MASTER-SLAVE结构,消息在正常情况下会同时存放两份,其中一份会强制持久化到磁盘,磁盘做RAID-5。默认情况下客户端采用同步发送,每条消息到达服务端MASTER后会强制刷入磁盘同时并行推送一份到SLAVE上,SLAVE写入文件系统后不等待强制刷盘就反馈给MASTER。根据不同的场景为了提高服务的可用性,普通级别的消息SLAVE断开后,该组服务可以正常使用,当SLAVE连接上后又会自动切换为保存两份。当然对数据可靠级别高的消息是强制要求数据必须写两份才算成功的。
服务高可用
每类消息一般都会分配3组及以上的服务组,每组服务包括一个MASTER和一个SLAVE,当然如果有需要也可以挂载多个SLAVE。
客户端发送消息时,如果其中一组出现故障会重试发送给其他的组。
虽然MASTER-SLAVE支持切换,提高服务的可用性,但是在实际生产中MASTER出现故障时会优先采用通过其他服务组自动接替生产服务的方式,本组服务只提供从SLAVE读取的方式,而不是让SLAVE接替MASTER的写入,避免临界状态下丢失消息。
对要求严格顺序的消息,不能通过简单的切换服务组实现,具体实现方式参考《高可用保证消息绝对顺序消费的BROKER设计方案》(http://wely.iteye.com/blog/2347823)。
消费模型
由于公司以前有使用基于ACTIVEMQ二次开发的服务,服务端会存放客户端的消费位置,因此在自主研发JMQ时也延续了这种方式(可以兼容ACTIVEMQ的客户端)。但是ACTIVEMQ生产和消费都会操作索引文件,影响性能,JMQ吸取了这个经验教训。消费者在消费时按照索引分区顺序的消费,消费确认时只需要变更最后确认位置的值,不需要操作索引文件,而且多个消费者共用一个索引文件,各自保存自己的消费偏移位置就可以了。
当然在实践过程中,由于一些特殊场景需要,会允许一定范围内不完全按照顺序消费,但是服务端会记录已经消费的索引区间。
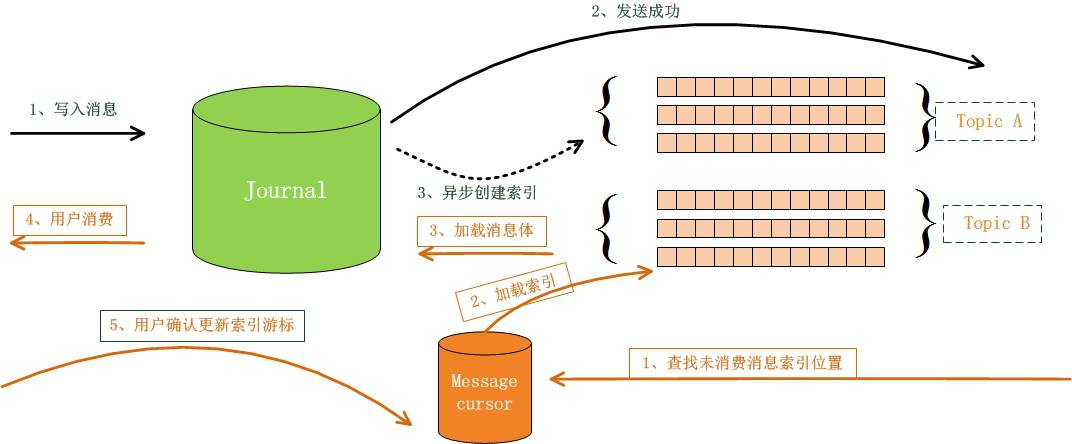
与KAFKA的对比
JMQ在服务端存储设计上与KAFKA有一些相似的地方,借鉴了文件按照偏移位置管理、顺序追加等特点。不过JMQ的存储和消费模型有自己的特点:
消息存放
JMQ每个存储系统只有一个分段存储的日志文件,不同类的消息按照服务端接收的顺序存放在日志文件中,通过索引程序按照不同的消息(主题)分类名异步创建各自的索引,方便消费端获取消息时快速定位该客户端所关心的(主题)分类消息。每个(主题)分类的索引划分了多个分区,同一(主题)分类的消息分配在多组服务器上的分区数是相同的。每个索引分区都是以链表按照时间序存放消息引用信息。
消费
JMQ也采用客户端主动拉取的方式,但是客户端不需要协调自己应该从哪个服务器上获取消息,服务端会控制好每个索引分区里对应的消息在同一时刻只会被一个客户端线程取走,直到客户端反馈消费成功或者消费异常,消费异常会被重试程序转移到重试服务中。如果客户端长时间没有反馈信息,达到了超时时间,那么锁定的消息可以被其他的线程拉取走。
由于服务端储存了每个消费者消费的位置,因此服务器可以随时把已经消费的消息移除走。
主要特性与场景
发布与订阅
目前公司接入的消息绝大部分都采用这种方式,不同类的消息通过主题名进行区分,多个消费者分组之间各自消费一份完整的消息内容,他们看到的消费视图一模一样,唯一的区别就是各自消费进度不同。
同一个消费分组内的消费实例只会消费到其中一部分消息,各自连接服务端,通过抢占的方式进行消费。
场景:
以订单消息为例,订单系统在订单的生命周期里的每一次变更都会发送消息,订单查询系统、结算系统、库房生产系统等都会订阅该类型的消息,每个系统拿到一份完整的消息,各自进行处理。
广播
由于发布订阅型的主题消息,如果要获取一份完整的消息就需要命名一个消费组,如果一类消息每个消费者实例都需要获取一份完整的消息,如果还按照主题消息管理那么就需要为每一个实例命名一个唯一的标识,使用时非常不方便,这时可以使用广播类型的消息,每个消费广播消息的实例都会拿到一份完整消息。
场景:
分布式数据库接入层对应的服务端拓扑信息需要调整,客户端可以订阅一个拓扑变更的广播消息,提前把需要变更的拓扑信息下发给每个客户端备用,当捕捉到拓扑变更的异常后就启用备用拓扑信息。
顺序消费
消息的消费会根据服务端接收到的顺序,依次推送给客户端消费,消息如果乱序可能会引起最终结果不正常。
场景:
数据库binglog日志基于消息系统进行复制,接收到消息的客户端可以更新ElasticSearch中的索引信息,可以修改Redis中的值,同时也可以基于日志重放同步数据到一个全量的数据库中。如果有一条记录的更新和删除操作乱序到达消费端,那么各个系统的状态将会不一致。
索引分区并行消费
默认情况下,每个索引分区的消息只能够按照顺序依次进行消费,如果索引分区内有一条消息处理比较慢,就会阻塞后面消息的处理,导致消息积压,影响消息的实时性。为了解决这个问题,可以增大索引分区数,但是每个索引分区对应独立的文件夹,增大会导致文件夹数目扩大,而且不能根本解决,只是一定程度缓解积压的消息数目。如果让单个索引分区内的消息可以并行的把不同区间的消息发送给客户端处理,这样如果有某条消息处理慢,服务端可以把后面的消息交给空闲的客户端线程去处理,当连续多个区间的消息都消费后再统一合并为一个大的消费区间,减少服务端需要记录的已消费区间数。
场景:
有一个通过消息派发任务的应用,每个任务执行时间长短不一,消费端获取到消息后,根据消息构建任务执行,任务完成后反馈给服务端消费成功。由于任务执行时间长短不一样,因此客户端的超时时间只能以最长的时间为参考进行设置,避免任务在执行过程中由于超时被其他线程重复处理。但是当一个时间相对长的任务在执行时,它会占用该消息所在索引分区被锁定,后面的任务不能及时派发给空闲的客户端处理。这时服务端如果启用索引分区并行消费的特性,就可以及时的把后面的任务派发给其他的客户端去执行,同时也不需要调整索引的分区数。
事务消息
事务消息具有回滚的特点,当消息发送给服务端未提交前,如果关联的其他业务操作失败,客户端可以主动发起回滚,当回滚或者提交事务消息时网络故障,消息系统会主动调用客户端的事务状态查询接口,根据客户端查询到的事务状态决定消息是否提交或回滚。这样就能够保证消息系统和业务系统数据状态最终完全一致。利用消息系统会主动查询不确定状态消息的特点,可以做为多个资源的事务协调器使用。
场景:
变更缺货商品的库存信息时,需要更新下单系统中的库存数,需要通知搜索系统修改商品索引,需要通知网页缓存系统刷新。各个系统之间由于各种网络或服务等原因造成状态不一致。可能出现库存变更了,其他系统的商品可销售状态没有修改正确,或者出现库存数据修改失败,但是其他系统的商品状态发生了变更。只能通过一些核对系统定期的把各个系统中的不一致状态变更为一致,加大了开发工作量,而且定期扫描可能引发性能问题。
通过事务消息,可以很好的解决这类场景,不会因为网络不可用等原因出现系统之间状态不一致。
当更新任何一个服务出现故障时就抛出异常,事务消息不会被提交或回滚,消息服务器会回调发送端的事务查询接口,确定事务状态,发送端程序可以根据消息的内容对未做完的任务重新执行,然后告诉消息服务器该事务的状态。

以上是关于京东消息中间件JMQ(转)的主要内容,如果未能解决你的问题,请参考以下文章
转:KafkaRabbitMQRocketMQ消息中间件的对比 —— 消息发送性能 (阿里中间件团队博客)