使用前缀树实现敏感词过滤(字符串的匹配)
Posted 风车菊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用前缀树实现敏感词过滤(字符串的匹配)相关的知识,希望对你有一定的参考价值。
概述
记录一下,学习使用前缀树,来实现从一传字符串中找出敏感词,并替换掉。起始就是一个字符串匹配算法,但是要清楚,铭感词可以有很多个,我们从数据库或者文件中加载我们的敏感词,并且加入到树中,组成一个铭感词树,下面就是当我们传递过来一个字符串时,我们使用这个树过滤,得出我们想要的结果
树的结构
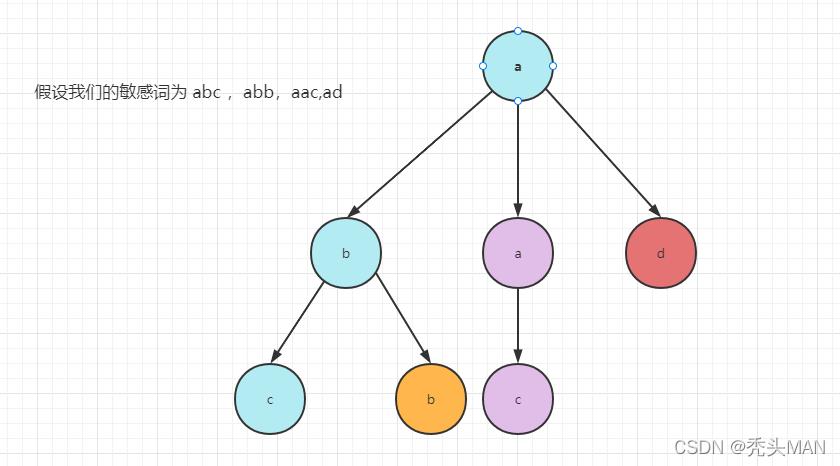
假设我们的敏感词为 abc,abb,aac,ad,那我们期望得到一颗如下的树,按照我们字符前缀组成的一颗树,此外我们还需要对该串的结束字符做一个标识,即叶子节点就是结束字符。
代码设计如下
/**
* 前缀树
*/
private class PrefixTreeNode
/**
* val
*/
private char val;
/**
* 标识当前字符是否为结束字符
*/
private boolean isEndKeyWord = false;
/**
* 当前节点的下一个节点
*/
private Map<Character, PrefixTreeNode> subRoot = new HashMap<>();
整体代码如下
public class SensitiveWordFilter
private final PrefixTreeNode prefixTreeRoot = new PrefixTreeNode();
private final String REPLACE_SYMBOL = "***";
// 初始化前缀树
// 加载文件
InputStream inputStream = SensitiveWordFilter.class.getClassLoader().getResourceAsStream("sensitive_word.txt");
// 字节流转换为字符流
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String data = null;
while (true)
try
if ((data = reader.readLine()) == null) break;
this.addKeyWord(data);
catch (IOException e)
e.printStackTrace();
/**
* 添加前缀树关键词
*
* @param data
*/
public void addKeyWord(String data)
// node 为当前节点
PrefixTreeNode node = prefixTreeRoot;
for (int i = 0; i < data.length(); i++)
char val = data.charAt(i);
// 获取一下node节点的子节点val
PrefixTreeNode subNode = node.getSubNodeByKey(val);
if (subNode == null)
// 当前节点不存在该子节点,需要初始化,添加一下
subNode = new PrefixTreeNode(val);
// 该节点为最终节点的话,设置一下
if (data.length() == (i + 1)) subNode.setEndKeyWord(true);
// 添加到我们的当前节点的子节点下
node.addSubNode(val, subNode);
// 当前节点存在该字节点,修改node节点为该字节点,进入下一次循环
node = subNode;
/**
* 对我们的字符串进行敏感词检查
*
* @param data
* @return
*/
public String doFilter(String data)
if (data == null || data.length() == 0) return null;
StringBuilder result = new StringBuilder();
PrefixTreeNode curNode;
for (int i = 0; i < data.length(); i++)
curNode = prefixTreeRoot;
char val = data.charAt(i);
// 检查当前节点是否有该字符节点
PrefixTreeNode subNode = curNode.getSubNodeByKey(val);
if (subNode == null)
result.append(val);
else
// 设置当前节点为该子节点
curNode = subNode;
// 存在的话
int startIndex = i;
for (int j = startIndex + 1; j < data.length(); j++)
char target = data.charAt(j);
PrefixTreeNode curSubNode = curNode.getSubNodeByKey(target);
// 该字符不是当前节点的子节点
if (curSubNode == null)
// 回到原来的地方
startIndex = j;
break;
else if (curSubNode.isEndKeyWord())
// 当前节点不存该子几点时或者当前节点对应的该字符节点为结束字符时
result.append(REPLACE_SYMBOL);
startIndex = j + 1;
break;
else
curNode = curSubNode;
i = startIndex - 1;
return result.toString();
/**
* 前缀树
*/
private class PrefixTreeNode
/**
* val
*/
private char val;
/**
* 标识当前字符是否为结束字符
*/
private boolean isEndKeyWord = false;
public boolean isEndKeyWord()
return isEndKeyWord;
public void setEndKeyWord(boolean endKeyWord)
isEndKeyWord = endKeyWord;
/**
* 当前节点的下一个节点
*/
private Map<Character, PrefixTreeNode> subRoot = new HashMap<>();
public PrefixTreeNode(char val, Map<Character, PrefixTreeNode> subRoot)
this.val = val;
this.subRoot = subRoot;
public PrefixTreeNode(char val)
this.val = val;
/**
* 根据key获取当前节点的字节点
*
* @param val
* @return
*/
public PrefixTreeNode getSubNodeByKey(char val)
return subRoot.get(val);
/**
* 增加一个子节点
*
* @param val
* @param node
*/
public void addSubNode(char val, PrefixTreeNode node)
subRoot.put(val, node);
public PrefixTreeNode()
public Character getVal()
return val;
public void setVal(Character val)
this.val = val;
public Map<Character, PrefixTreeNode> getSubRoot()
return subRoot;
public void setSubRoot(Map<Character, PrefixTreeNode> subRoot)
this.subRoot = subRoot;
代码解读,设计思路
首先这个树是一个内部类,因为只有敏感词过滤类使用该类,是一个特有的数据结构,设计思想可以参考JDK,好多类的设计,都是高内聚,对类的操作,高内聚,外部类,仅仅只是要调用而已。
每次创建对象时,都会从类路径下加载一个文件,存储我们铭感词的文件,然后,加入到我们的敏感词树中。
一开始我们就创建一个根节点,不存储数据,他的子节点才开始存储数据,为了和后面的设计保持一致。
以上是关于使用前缀树实现敏感词过滤(字符串的匹配)的主要内容,如果未能解决你的问题,请参考以下文章