理解图形化执行计划 -- 第3部分:分析执行计划
Posted dreamw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解图形化执行计划 -- 第3部分:分析执行计划相关的知识,希望对你有一定的参考价值。
英文原文:
http://www.sqlservercentral.com/articles/Execution+Plans/105810/
对于SQL Server数据库管理员和开发来说,能够理解和分析执行计划是一项非常重要且有益的技能。执行计划将查询的预估花销、索引使用和执行的操作文档化输出。所有的信息对于试着加速一个慢查询来说都是极其重要的。
这篇文章是关于图形化执行计划的三部分系列文章之一。第1部分解释了执行计划是什么,并讨论了预估和实际执行计划的不同。第2部分显示了如何创建预估和实际执行计划。最后,第3部分深入一个简单的图形化执行计划,并讨论了一些最普遍的查询中的操作。
阅读执行计划
让我们看下如何从执行情况和执行计划中获得信息。
基础
图1从[AdventureWorks2012].[Person].[Address]表上的一个简单查询显示预估的执行计划。如你所见,它由表明操作和关联不同操作的箭头的图标组成。箭头都指向左边,表明执行计划从右边开始并向左运行。按时间顺序阅读执行计划,从最右边的操作开始并向左运行。箭头的相对层次也表明了多少数据正被从一个操作传递到另一个。

图1 一个简单的预估执行计划
在图2中,顶部操作的箭头比它下面的两个操作更瘦。顶部操作因此也输出更少的行。
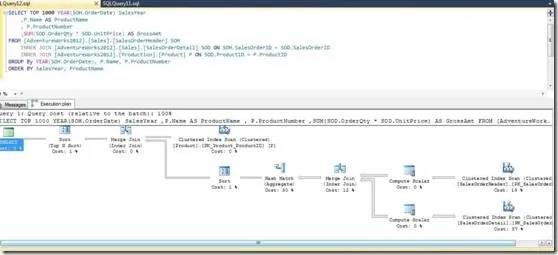
图2 一个稍微复杂的执行计划
在创建了执行计划后,就有地方可以看到查询的总消耗。总消耗位于最后的操作。这就是最左边图标的上层,在这里,就是Select操作。将鼠标放在Select图标的上面会给你一个关于操作信息的提示框(图3)。
我们对Estimated Subtree Cost感兴趣。总的消耗是一个查询是否执行很快的更好判断的相对值。它由I/O消耗和CPU消耗组成。Operator Cost是I/O Cost和CPU Cost之和。在这里我们的查询很好的低于1。它有可能执行相对较快。另一方面,一个查询总消耗上千可能需要相当长时间完成。一些因素影响着预估消耗。不仅是相关表和视图的行和索引的数量,而且环境因素例如CPU数量和磁盘都被用于计算消耗。
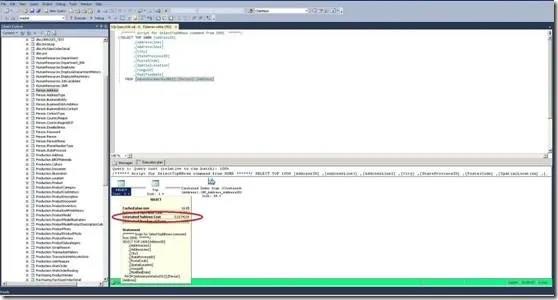
图3 查看执行计划总消耗
在检查了总消耗并得到一个运行时间的相对感觉后,接下来,从右到左快速查看执行的操作。在图1,首先,有一个聚集索引扫描。一个扫描表名查询不是非常可选择性(看Frequent Plan Operations下的Index/Table Scan查看更多细节)。在这个特定情况下,它是一个没有where从句的产物。我们也有TOP操作,从查询返回前1000行。最后,有一个在select语句中返回指定列的select操作。
一旦你有一个查询正在做什么的整体感受,我们将专注在最高消耗的操作上。在每个图标的最下面对每个操作执行计划列出了总消耗的百分比。从图1到图2,我们看到聚集索引扫描占比总消耗的99%。我们想专注在这个操作上。
我们看下这个图标的提示框(看图4),你会注意到有四个消耗列出。对于每个操作消耗分为CPU和IO消耗。Operator Cost是CPU和I/O Cost之和。Sub Tree Cost是当前的Operator Cost加上在它之前的操作的整个操作消耗。如果你从最右边的操作开始并跟随箭头向左,你会看到对每个完成的操作Sub Tree Cost累加。如我们之前查看到的,在左边最上层的操作的Sub Tree Cost包含了整个查询的预估的消耗。
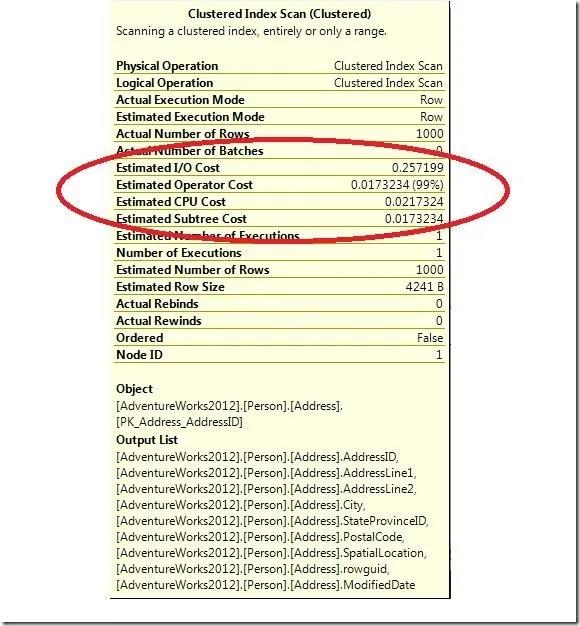
图4 执行计划消耗
常见的执行计划操作
下面是一些出现在查询计划里的最常用的操作。
Index/Table Seek -- 当执行seek,SQL Server可以在索引里有效查找特定值或值的一个可选择范围。使用图书馆类比,你使用图书馆的电脑查找一本书的位置,并获得这本书的位置。
Index/Table Scan -- 在scan操作中,SQL Server通读整个表或索引。再次使用图书馆类比,相当于查找图书馆中的每一本知道找到你想要的书。试着在大型的大学图书馆这么做!Scan表明了搜索标准没有达到足够的使用seek操作的选择性。如果在列上没有索引被查找或者返回的值的数量在索引中占百分比很大(低选择性),查看所有的值会更有效。如果你感觉有指定一个WHERE从句或JOIN足够保证使用索引,确保列上被索引。
Seek/Scan with Bmk谓词 -- 当在一个索引查找或扫描的提示框的Seek Predicates部分查看,你有时会看到一个谓词像Bmknnnn这里nnnn是数字。这表明SQL Server会创建一个书签用于Index或RID Lookup。当书签出现,index seek/scan是一个两步过程的部分,优化器会在使用书签创建了一个数据集后,执行聚集索引查找(或表查找,如果没有聚集索引)。查看关于Key/RID Lookup部分的更多信息。
Joins
SQL Server使用了三种join操作:
Hash Match/Join -- Hash Match或者Join可以用于Join(Hash Join)和Group by的(Hash Match)。在这个操作中,查询优化器从被关联的两个表(如图形化执行计划中所见)的上层表构建一个哈希表。这被称为构造表。低层表(被称为探测表)的每行然后搜索构造表匹配数据。在一个Group By的情况下,之前操作的结果被用于构造表和探测表。这类Join效率的关键是构造表的大小和服务器的可用内存数量。如果足够小,优化器将在内存中创建构造表。如果可能,Hash Match将会相当快。另一方面,如果构造表相当大,处理过程编程一个嵌套循环并且非常慢。当这发生的时候,Hash Match的消耗是执行计划的重要的百分比,你应该使得查询更具选择性或者考虑增加一个索引。Hash Join和Match会在执行前等待有足够的内存。
Merge Join -- 当上层表(如图形化执行计划中所示)在Join中很大,Merge Join将会是最快的Join类型。这个Join的消耗与两个表的行数总和相关(#上层表的行数 + #下层表的行数)。Merge Join的效率的关键是关联的两个表必须在关联列上已排序。如果表还没有排序,优化器将会首先排序表。在这里,你会在Merge Join操作器之前直接看到一个排序操作器。排序操作是非常消耗性能的,因此如果一个执行计划在Merge Join之前显示了一个有高消耗排序操作器,你可能想在关联列添加索引。
Nested Loop -- 嵌套循环关联的消耗和两个表行数(#上层表的行数 * #下层表的行数)的乘积有关。虽然这个Join没有Merge Join有效率,当表没有排序时它的整体消耗比Merge Join低,当上层表很大时它的整体消耗比比Hash Join低。再则,如果操作的消耗在执行计划中占很高百分比,那么让你的查询更具选择性或者添加一个索引。
Key/RID Lookup -- 当在一个非聚集索引上执行seek或scan时发生lookup,并且所有的数据不包含在索引中。当这种情况发生时,如果存在聚集索引,在聚集索引上发生Key Lookup,否则如果没有聚集索引,执行行标识符(RID)Lookup。Lookup是昂贵的操作,如果可能应该避免。为了消除Lookup,将Select语句中的列添加包含在非聚集索引中的include从句中,如果可能。要是你有很多列在Select语句中,不可能将所有都包含进去,又怎样呢?接下来最应该做的事是使得非聚集索引比当前正使用的索引更具选择性。那就是说,如果你不能移除Lookup,试着减少传递给Lookup的行数。
Compute Scalar -- 该操作执行计算处理一个单一值。通常是标量函数、算术计算或字符串联接的结果。警告,优化器不能预估标量或多语句表值函数的执行计划。当这些函数之一出现了性能低下,尝试将它转换为一个内联表值函数。
Concatenation -- 对字符串联接不操作;而是对于数据集合的联接。最常用于在UNION ALL操作中国联接数据。
Sort -- sort操作只将非排序数据作为输入并输出一个排序集合。排序在大型数据集合上是非常消耗性能的。排序也需要在执行前等待内存足够多。有高排序消耗的执行计划应该被检查用于优化。
Parallelism -- 如果SQL Server所在的机器上有不止一个处理器,可选的在多个处理器之间拆分操作。事实上,如果有多个处理器,优化器会创建两个执行计划,一个用于并行而一个没有。SQL Server然后决定哪个最后可能消耗最短的时间。Parallelism致力于将数据分割在多个处理器间覆盖操作并合并结果。如果并行操作消耗很高,你可以在查询上使用MAXDOP查询提示[OPTION (MAXDOP 1) ]强制使用一个处理器。
对于操作的完整列表,查看TechNet文章 Showplan逻辑和物理操作参考。
总结
在查询优化中阅读图形化执行计划是一个非常有用的技能。该系列文章介绍了这个主题。我欢迎你对后续文章的评论。如果你也想阅读更多这个主题的内容,Grant Fritchey的书SQL Server执行计划提供了最好的最广泛的涵盖内容。
参考
.分析查询,TechNet Library -- http://technet.microsoft.com/en-us/library/ms191227(v=SQL.105).aspx
.分析慢查询的清单,TechNet Library -- http://technet.microsoft.com/en-us/library/ms177500(v=sql.105).aspx
.Fritchey,Grant(2008), SQL Server执行计划,Simple Talk出版(本文使用2008版,2013年出版了第2版)
.Showplan逻辑和物理操作参考,TechNet Library -- http://technet.microsoft.com/en-us/library/ms191158.aspx
译者补充:
浅谈SQL Server中的三种物理连接操作
https://msdn.microsoft.com/zh-cn/library/dn144699.aspx
表值函数
表值函数提供强大的结果集生成能力。它可以在查询内部表或视图允许的任何地方使用。表值函数在使用上比返回一个结果集的存储过程更灵活,因为函数的结果集可以联接到查询中的其他表。
SQL Server中有两种表值函数。内联表值函数在概念上与带参数的视图类似。多语句表值函数允许多条语句在表变量中创建结果集来返回。
1. 内联表值函数
创建内联表值函数很简单。内联表值函数的内容是一条带参数的SELECT语句。返回数据类型永远是表,不过返回表的结构由SELECT语句的结构来定义。下面是内联表值函数的一个例子,检索给定CustomerID的商品销售总量。
USE AdventureWorks2008; GO CREATE FUNCTION Sales.ufnSalesByCustomer (@CustomerID int) RETURNS TABLE AS RETURN ( SELECT P.ProductID, P.Name, SUM(SD.LineTotal) AS Total FROM Production.Product AS P JOIN Sales.SalesOrderDetail AS SD ON SD.ProductID = P.ProductID JOIN Sales.SalesOrderHeader AS SH ON SH.SalesOrderID = SD.SalesOrderID WHERE SH.CustomerID = @CustomerID GROUP BY P.ProductID, P.Name ); GO
注意,函数体由一条RETURN语句组成。使用这个函数的一个例子如下所示:
SELECT * FROM Sales.ufnSalesByCustomer(30052);
1.
内联表值函数功能强大,在要求参数化查询的情况下值得考虑。它们在结果集如何使用上提供更多的灵活性。
2. 多语句表值函数
多语句表值函数允许多条语句来创建表的内容。多语句表值函数可以用来替换使用多个步骤来构建结果集的存储过程。
多语句表值函数允许开发人员使用多个步骤动态地填充表,这一点与存储过程类似,不过它们可以在SELECT语句中像表那样被引用。
使用多语句表值函数时,表的结构必须在函数头定义。要为表使用一个变量名,并且所有修改数据的操作只能引用表变量。
下面的例子是一个函数,类似上一节中创建的ufnSalesByCustomer。首先创建表变量,然后使用刚才创建的标量函数来更新表变量,让它包含总的存货清单。创建函数的语句如下所示:
USE AdventureWorks2008; GO CREATE FUNCTION Sales.ufnSalesByCustomerMS (@CustomerID int) RETURNS @table TABLE ( ProductID int PRIMARY KEY NOT NULL, ProductName nvarchar(50) NOT NULL, TotalSales numeric(38,6) NOT NULL, TotalInventory int NOT NULL ) AS BEGIN INSERT INTO @table SELECT P.ProductID, P.Name, SUM(SD.LineTotal) AS Total, 0 FROM Production.Product AS P JOIN Sales.SalesOrderDetail SD ON SD.ProductID = P.ProductID JOIN Sales.SalesOrderHeader SH ON SH.SalesOrderID = SD.SalesOrderID WHERE SH.CustomerID = @CustomerID GROUP BY P.ProductID, P.Name; UPDATE @table SET TotalInventory = dbo.ufnGetTotalInventoryStock(ProductID); RETURN; END;
执行这个函数与执行前面的内联函数一样:
SELECT * FROM Sales. ufnSalesByCustomerMS (30052);
-------------------------------------------------------------------------------------
表值函数和标量值函数的不同是 表值函数是返回一个Table类型 Table类型相当与一张存储在内存中的一张虚拟表.
-----------------------------------
理解图形化执行计划 -- 第3部分:分析执行计划
https://blog.51cto.com/ultrasql/1735019
以上是关于理解图形化执行计划 -- 第3部分:分析执行计划的主要内容,如果未能解决你的问题,请参考以下文章