商品零售购物篮分析
Posted Carpe diem
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了商品零售购物篮分析相关的知识,希望对你有一定的参考价值。
二、分析方法与过程
主要步骤
购物篮关联规则挖掘主要步骤如下:
- 对原始数据进行数据探索性分析,分析商品的热销情况与商品结构。
- 对原始数据进行数据预处理,转换数据形式,使之符合Apriori关联规则算法要求。
- 在步骤2得到的建模数据基础上,采用Apriori关联规则算法,调整模型输入参数,完成商品关联性分析。
- 结合实际业务,对模型结果进行分析,根据分析结果给出销售建议,最后输出关联规则结果。
总体流程
数据挖掘建模的总体流程:

数据分析探索
探索数据特征是了解数据的第一步。分析商品热销情况和商品结构,是为了更好地实现企业的经营目标。商品管理应坚持商品齐全和商品优选的原则,产品销售基本满足“二八定律”即80%的销售额是由20%的商品创造的,这些商品是企业主要盈利商品,要作为商品管理的重中之重。商品热销情况分析和商品结构分析也是商品管理不可或缺的一部分,其中商品结构分析能够帮助保证商品的齐全性,热销情况分析可以助力于商品优选。
某商品零售企业共收集了9835个购物篮的数据,购物篮数据主要包括3个属性:id、Goods和Types。属性的具体说明如表所示。

第一步:数据特征
探索数据的特征,查看每列属性、最大值、最小值,是了解数据的第一步。
import numpy as np import pandas as pd inputfile = \'../chap8/GoodsOrder.csv\' # 输入的数据文件 data = pd.read_csv(inputfile,encoding = \'gbk\') # 读取数据 data .info() # 查看数据属性 data = data[\'id\'] description = [data.count(),data.min(), data.max()] # 依次计算总数、最小值、最大值 description = pd.DataFrame(description, index = [\'Count\',\'Min\', \'Max\']).T # 将结果存入数据框 print(\'描述性统计结果by number35任:\\n\',np.round(description)) # 输出结果

第二步:分析热销商品
商品热销情况分析是商品管理不可或缺的一部分,热销情况分析可以助力于商品优选。计算销量排行前10商品的销量及占比,并绘制条形图显示销量前10商品的销量情况。
# 销量排行前10商品的销量及其占比 import pandas as pd inputfile = \'../chap8/GoodsOrder.csv\' # 输入的数据文件 data = pd.read_csv(inputfile,encoding = \'gbk\') # 读取数据 group = data.groupby([\'Goods\']).count().reset_index() # 对商品进行分类汇总 sorted=group.sort_values(\'id\',ascending=False) print(\'销量排行前10商品的销量by number35任:\\n\', sorted[:10]) # 排序并查看前10位热销商品 # 画条形图展示出销量排行前10商品的销量 import matplotlib.pyplot as plt x=sorted[:10][\'Goods\'] y=sorted[:10][\'id\'] plt.figure(figsize = (8, 4)) # 设置画布大小 plt.barh(x,y) plt.rcParams[\'font.sans-serif\'] = \'SimHei\' plt.xlabel(\'销量\') # 设置x轴标题 plt.ylabel(\'商品类别\') # 设置y轴标题 plt.title(\'商品的销量TOP10_by number35任\') # 设置标题 plt.savefig(\'../chap8/top10.png\') # 把图片以.png格式保存 plt.show() # 展示图片 # 销量排行前10商品的销量占比 data_nums = data.shape[0] for idnex, row in sorted[:10].iterrows(): print(row[\'Goods\'],row[\'id\'],row[\'id\']/data_nums)
为了使bar图更好看,我设置了颜色
import random colors = [[random.random() for _ in range(3)] for _ in range(len(data))] plt.barh(x,y,color=colors)



通过分析热销商品的结果可知,全脂牛奶销售量最高,销量为2513件,占比5.795%;其次是其他蔬菜、面包卷和苏打,占比分别为4.388%、4.171%、3.955%。
第三步:分析商品结构
对每一类商品的热销程度进行分析,有利于商家制定商品在货架的摆放策略和位置,若是某类商品较为热销,商场可以把此类商品摆放到商场的中心位置,方便顾客选购。或者放在商场深处位置,使顾客在购买热销商品前经过非热销商品,增加在非热销商品处的停留时间,促进非热销产品的销量。
原始数据中的商品本身已经过归类处理,但是部分商品还是存在一定的重叠,故再次对其进行归类处理。分析归类后各类别商品的销量及其占比,并绘制饼图显示各类商品的销量占比情况。
import pandas as pd inputfile1 = \'../chap8/GoodsOrder.csv\' inputfile2 = \'../chap8/GoodsTypes.csv\' data = pd.read_csv(inputfile1,encoding = \'gbk\') types = pd.read_csv(inputfile2,encoding = \'gbk\') # 读入数据 group = data.groupby([\'Goods\']).count().reset_index() sort = group.sort_values(\'id\',ascending = False).reset_index() data_nums = data.shape[0] # 总量 del sort[\'index\'] sort_links = pd.merge(sort,types) # 合并两个dataframe 根据type # 根据类别求和,每个商品类别的总量,并排序 sort_link = sort_links.groupby([\'Types\']).sum().reset_index() sort_link = sort_link.sort_values(\'id\',ascending = False).reset_index() del sort_link[\'index\'] # 删除“index”列 # 求百分比,然后更换列名,最后输出到文件 sort_link[\'count\'] = sort_link.apply(lambda line: line[\'id\']/data_nums,axis=1) sort_link.rename(columns = \'count\':\'percent\',inplace = True) print(\'各类别商品的销量及其占比:\\n\',sort_link) outfile1 = \'../chap8/percent.csv\' sort_link.to_csv(outfile1,index = False,header = True,encoding=\'gbk\') # 保存结果

画饼图展示每类商品销量占比:
# 画饼图展示每类商品销量占比 import matplotlib.pyplot as plt data = sort_link[\'percent\'] labels = sort_link[\'Types\'] plt.figure(figsize=(8, 6)) # 设置画布大小 plt.pie(data,labels=labels,autopct=\'%1.2f%%\') plt.rcParams[\'font.sans-serif\'] = \'SimHei\' plt.title(\'每类商品销量占比_by number35任\') # 设置标题 plt.savefig(\'../chap8/persent.png\') # 把图片以.png格式保存 plt.show()

通过分析各类别商品的销量及其占比情况可知,非酒精饮料、西点、果蔬三类商品销量差距不大,占总销量的50%左右,同时,根据大类划分发现和食品相关的类的销量总和接近90%,说明了顾客倾向于购买此类产品,而其余商品仅为商场满足顾客的其余需求而设定,并非销售的主力军。
查看销量第一的非酒精饮料类商品的内部商品结构,并绘制饼图显示其销量占比情况:
# 先筛选“非酒精饮料”类型的商品,然后求百分比,然后输出结果到文件。 selected = sort_links.loc[sort_links[\'Types\'] == \'非酒精饮料\'] # 挑选商品类别为“非酒精饮料”并排序 child_nums = selected[\'id\'].sum() # 对所有的“非酒精饮料”求和 selected[\'child_percent\'] = selected.apply(lambda line: line[\'id\']/child_nums,axis = 1) # 求百分比 selected.rename(columns = \'id\':\'count\',inplace = True) print(\'非酒精饮料内部商品的销量及其占比:\\n\',selected) outfile2 = \'../chap8/child_percent.csv\' sort_link.to_csv(outfile2,index = False,header = True,encoding=\'gbk\') # 输出结果

# 画饼图展示非酒精饮品内部各商品的销量占比 import matplotlib.pyplot as plt data = selected[\'child_percent\'] labels = selected[\'Goods\'] plt.figure(figsize = (8,6)) # 设置画布大小 explode = (0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3) # 设置每一块分割出的间隙大小 plt.pie(data,explode = explode,labels = labels,autopct = \'%1.2f%%\', pctdistance = 1.1,labeldistance = 1.2) plt.rcParams[\'font.sans-serif\'] = \'SimHei\' plt.title("非酒精饮料内部各商品的销量占比_by number35任") # 设置标题 plt.axis(\'equal\') plt.savefig(\'../chap8/child_persent.png\') # 保存图形 plt.show() # 展示图形

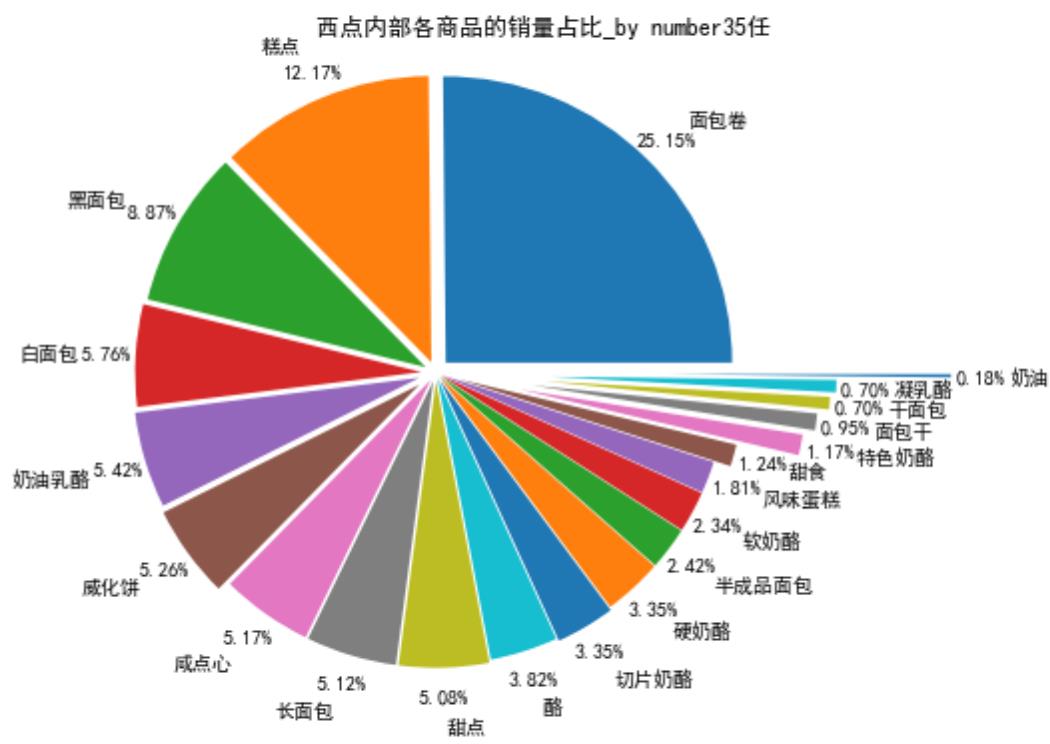
查看销量第二的西点类商品的内部商品结构,并绘制饼图显示其销量占比情况:
# 先筛选“西点”类型的商品,然后求百分比,然后输出结果到文件。 selected = sort_links.loc[sort_links[\'Types\'] == \'西点\'] # 挑选商品类别为“西点”并排序 child_nums = selected[\'id\'].sum() # 对所有的“非酒精饮料”求和 selected[\'child_percent_xidian\'] = selected.apply(lambda line: line[\'id\']/child_nums,axis = 1) # 求百分比 selected.rename(columns = \'id\':\'count\',inplace = True) print(\'西点内部商品的销量及其占比_by number35任:\\n\',selected) outfile2 = \'../chap8/child_percent_xidian.csv\' sort_link.to_csv(outfile2,index = False,header = True,encoding=\'gbk\') # 输出结果

# 画饼图展示西点内部各商品的销量占比 import matplotlib.pyplot as plt data = selected[\'child_percent_xidian\'] labels = selected[\'Goods\'] plt.figure(figsize = (8,6)) # 设置画布大小 explode = (0.05,0.04,0.04,0.05,0.06,0.07,0.03,0.03,0.03,0.02,0.03,0.02,0.02,0.02,0.02,0.08,0.3,0.34,0.38,0.4,0.8) # 设置每一块分割出的间隙大小 plt.pie(data,explode = explode,labels = labels,autopct = \'%1.2f%%\', pctdistance = 1.1,labeldistance = 1.2) plt.rcParams[\'font.sans-serif\'] = \'SimHei\' plt.title("西点内部各商品的销量占比_by number35任") # 设置标题 plt.axis(\'equal\') plt.savefig(\'../chap8/child_persent_xidian.png\') # 保存图形 plt.show() # 展示图形
以上是关于商品零售购物篮分析的主要内容,如果未能解决你的问题,请参考以下文章