用Python进行网页抓取
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python进行网页抓取相关的知识,希望对你有一定的参考价值。
引言
从网页中提取信息的需求日益剧增,其重要性也越来越明显。每隔几周,我自己就想要到网页上提取一些信息。比如上周我们考虑建立一个有关各种数据科学在线课程的欢迎程度和意见的索引。我们不仅需要找出新的课程,还要抓取对课程的评论,对它们进行总结后建立一些衡量指标。这是一个问题或产品,其功效更多地取决于网页抓取和信息提取(数据集)的技术,而非以往我们使用的数据汇总技术。
网页信息提取的方式
从网页中提取信息有一些方法。使用API可能被认为是从网站提取信息的最佳方法。几乎所有的大型网站,像Twitter、Facebook、Google、Twitter、StackOverflow都提供API以更为结构化的方式访问该网站的数据。如果可以直接通过API得到所需要的信息,那么这个方法几乎总是优于网页抓取方法。因为如果可以从数据提供方得到结构化的数据,为什么还要自己建立一个引擎来提取同样的数据?
不幸的是,并不是所有的网站都提供API。一些网站是不愿意让读者通过结构化的方式抓取大量的信息,另一些网站是因为缺乏相关的技术知识而不能提供API。在这样的情况下,该怎么做?好吧,我们需要通过网页抓取来获得数据。
当然还有一些像RSS订阅等的其它方式,但是由于使用上的限制,因此我将不在这里讨论它们。
什么是网页抓取?
网页抓取是一种从网站中获取信息的计算机软件技术。这种技术主要聚焦于把网络中的非结构化数据(HTML 格式)转变成结构化数据(数据库或电子表格)。
可以用不同的方式实施网页抓取,包括从Google Docs到几乎所有的编程语言。由于Python的易用性和丰富的生态系统,我会选择使用Python。
Python中的BeautifulSoup库可以协助完成这一任务。在本文中,我将会利用Python编程语言给你看学习网页抓取最简单的方式。
对于需要借助非编程方式提取网页数据的读者,可以去import.io上看看。那上面有基于图形用户界面的驱动来运行网页抓取的基础操作,计算机迷们可以继续看本文!
网页抓取所需要的库
我们都知道Python是一门开源编程语言。你也许能找到很多库来实施一个功能。因此,找出最好的库是非常必要的。我倾向于使用BeautifulSoup (Python库),因为它的使用简单直观。准确地说,我会用到两个Python模块来抓取数据:
?Urllib2:它是一个Python模块,用来获取URL。它定义函数和类,实现URL操作(基本、摘要式身份验证、重定向、cookies等)欲了解更多详情,请参阅文档页面。
?BeautifulSoup:它是一个神奇的工具,用来从网页中提取信息。可以用它从网页中提取表格、列表、段落,也可以加上过滤器。
在本文中,我们将会用最新版本,BeautifulSoup 4。可以在它的文档页面查看安装指南。
BeautifulSoup不帮我们获取网页,这是我将urllib2和BeautifulSoup 库一起使用的原因。除了BeautifulSoup之外,Python还有其它一些方法用于HTML的抓取。如:
?mechanize
?scrapemark
?scrapy
基础-熟悉HTML(标签)
在进行网页抓取时,我们需要处理html标签。因此,我们必须先好好理解一下标签。如果已经了解HTML的基础知识,可以跳过这一节。以下是HTML的基本语法:
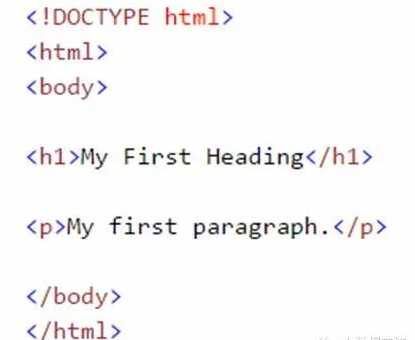
该语法的各种标签的解释如下:
1.<!DOCTYPE html>:html文档必须以类型声明开始
2.html文档写在<html> 和</html>标签之间
3.html文档的可见部分写在<body> 和</body>标签之间
4.html头使用<h1> 到<h6> 标签定义
5.html段落使用<p>标签定义
其它有用的HTML标签是:
1.html链接使用<a>标签定义,“<a href=“http://www.test.com”>这是一个测试链接.com</a>”
2.html表格使用<Table>定义,行用<tr>表示,行用<td>分为数据

3.html列表以<ul>(无序)和<ol>(有序)开始,列表中的每个元素以<li>开始
如果不熟悉这些HTML标签,我建议到W3schools上学习HTML教程。这样对HTML标签会有个清楚的理解。
使用BeautifulSoup抓取网页
在这里,我将从维基百科页面上抓取数据。我们的最终目的是抓取印度的邦、联邦首府的列表,以及一些基本细节,如成立信息、前首府和其它组成这个维基百科页面的信息。让我们一步一步做这个项目来学习:
1.导入必要的库
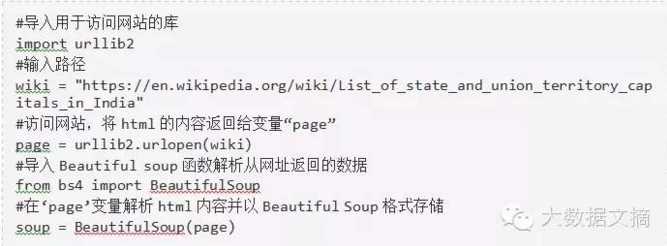
2.使用“prettify”函数来看HTML页面的嵌套结构
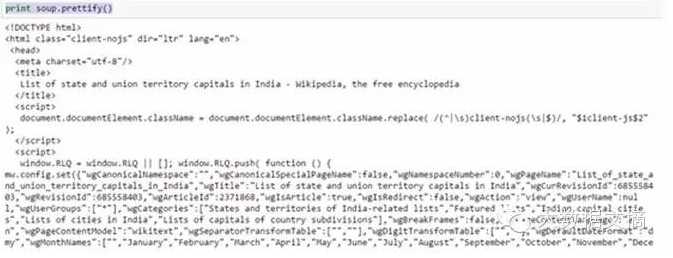
如上所示,可以看到HTML标签的结构。这将有助于了解不同的可用标签,从而明白如何使用它们来抓取信息。
3.处理HTML标签
a.soup.<tag>:返回在开始和结束标签之间的内容,包括标签在内。

b.soup.<tag>.string: 返回给定标签内的字符串

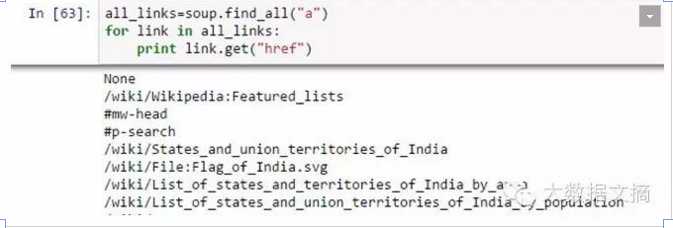
c.找出在标签<a>内的链接:我们知道,我们可以用标签<a>标记一个链接。因此,我们应该利用soup.a 选项,它应该返回在网页内可用的链接。我们来做一下。

如上所示,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取<a>中的所有链接。
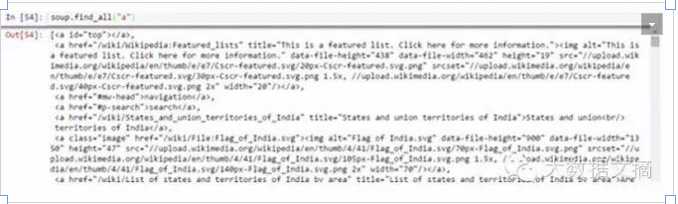
上面显示了所有的链接,包括标题、链接和其它信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每一个标签,然后再返回链接。
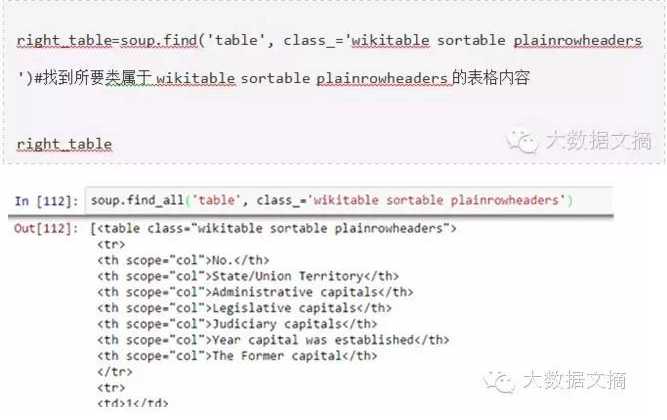
4.找到正确的表:当我们在找一个表以抓取邦首府的信息时,我们应该首先找出正确的表。让我们写指令来抓取所有表标签中的信息。

现在为了找出正确的表,我们将使用表的属性“class(类)”,并用它来筛选出正确的表。在chrome浏览器中,可以通过在所需的网页表格上单击右键来查询其类名–>检查元素–>复制该类名或通过上述命令的输出找到正确的表的类名。
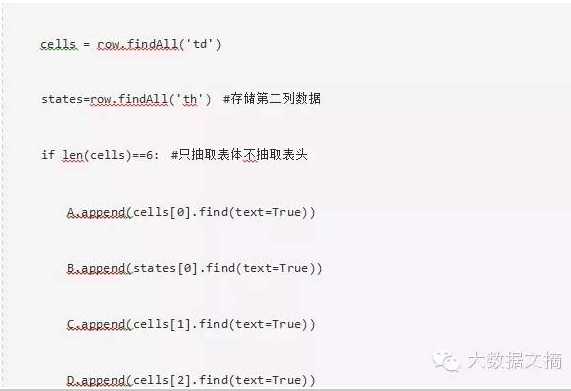
5.提取信息放入DataFrame:在这里,我们要遍历每一行(tr),然后将tr的每个元素(td)赋给一个变量,将它添加到列表中。让我们先看看表格的HTML结构(我不想抓取表格标题的信息<th>)
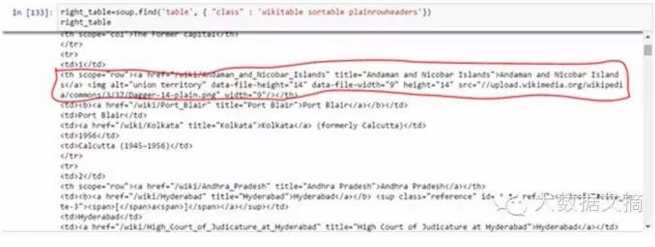
如上所示,你会注意到<tr>的第二个元素在< th >标签内,而不在<td>标签内。因此,对这一点我们需要小心。现在要访问每个元素的值,我们会使用每个元素的“find(text=True)”选项。让我们看一下代码:
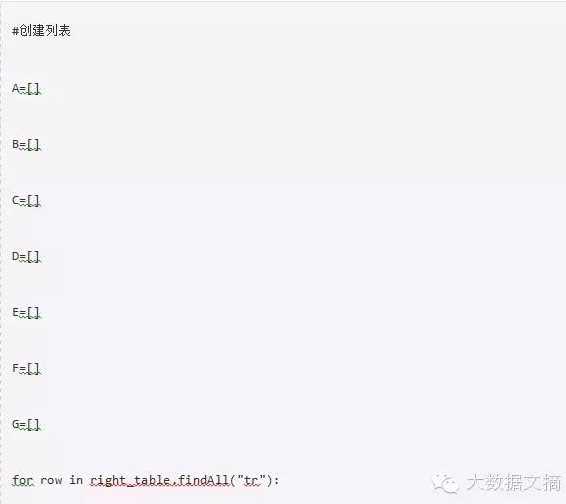


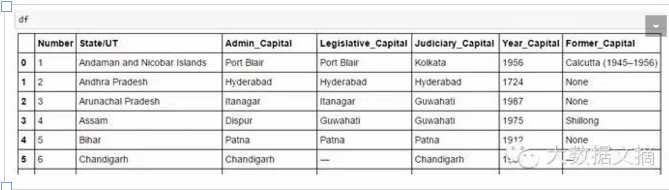
最后,我们在dataframe内的数据如下:
类似地,可以用BeautifulSoup实施各种其它类型的网页抓取。这将减轻从网页上手工收集数据的工作。也可以看下其它属性,如.parent,.contents,.descendants 和.next_sibling,.prev_sibling以及各种用于标签名称浏览的属性。这些将有助于您有效地抓取网页。
但是,为什么我不能只使用正则表达式(Regular Expressions)?
现在,如果知道正则表达式,你可能会认为可以用它来编写代码做同样的事情。当然,我也有过这个问题。我曾使用BeautifulSoup和正则表达式来做同样的事情,结果发现:
BeautifulSoup里的代码比用正则表达式写的更强大。用正则表达式编写的代码得随着页面中的变动而进行更改。即使BeautifulSoup在一些情况下需要调整,但相对来讲,BeautifulSoup较好一些。
正则表达式比BeautifulSoup快得多,对于相同的结果,正则表达式比BeautifulSoup快100倍。
因此,它归结为速度与代码的鲁棒性之间的比较,这里没有万能的赢家。如果正在寻找的信息可以用简单的正则表达式语句抓取,那么应该选择使用它们。对于几乎所有复杂的工作,我通常更多地建议使用BeautifulSoup,而不是正则表达式。
结语
本文中,我们使用了Python的两个库BeautifulSoup和urllib2。我们也了解了HTML的基础知识,并通过解决一个问题,一步一步地实施网页抓取。我建议你练习一下并用它来从网页中搜集
以上是关于用Python进行网页抓取的主要内容,如果未能解决你的问题,请参考以下文章