损失函数
Posted dctwan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了损失函数相关的知识,希望对你有一定的参考价值。
损失函数
参考:
“损失函数”是如何设计出来的?直观理解“最小二乘法”和“极大似然估计法”_哔哩哔哩_bilibili
“交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”_哔哩哔哩_bilibili
最小二乘法
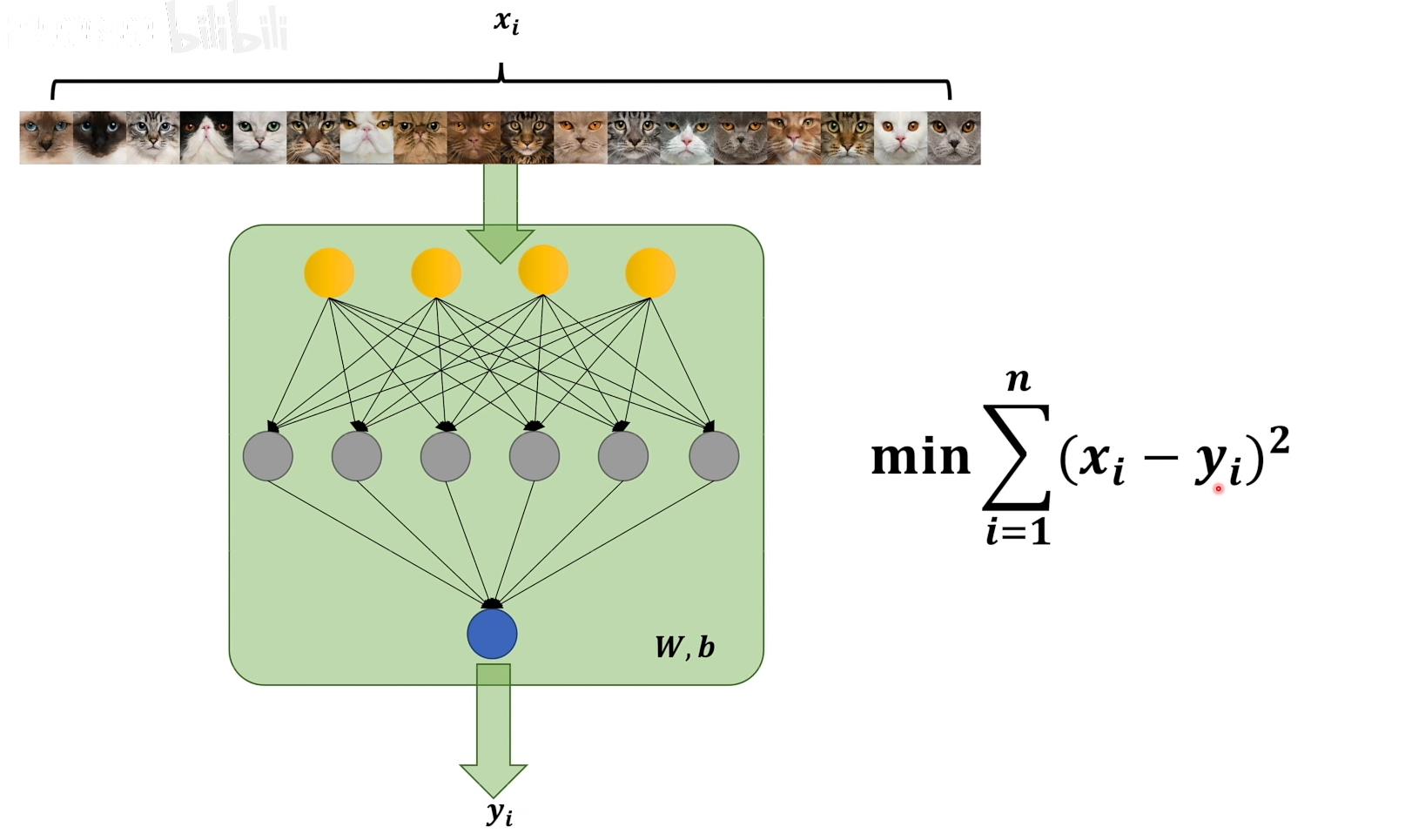
所谓最小即梯度下降要找到使得损失函数最小的参数W和b
所谓二乘法即使用了真实值与预测值差的平方,目的是方便求导
极大似然估计法
根据样本实际的情况,估计样本服从某种分布的概率,找到最大可能的一种概率模型
计算神经网络概率模型的似然值,找到极大似然值,这个就应该是最接近真实情况的概率模型
其实就是给定一种模型,在神经网络中这个模型由其权重参数W和偏置b决定,计算在这个模型上出现输入情况的概率,然后我们需要最大化这个概率,用于逼近真实模型
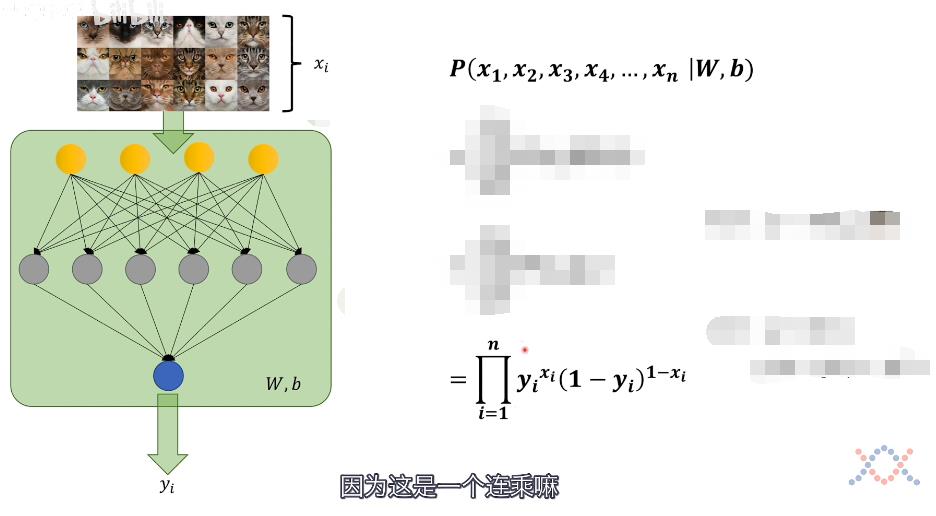
此处直接理解概率会清晰一点,现在的目标是计算在参数为(W,b)的模型下,得出输入情况(x1...xn)的概率
其中yi为在当前模型下预测输入图片是猫的概率
- 当xi = 1,即输入是猫,输出是猫的概率为yi
- 当xi = 0,即输入不是猫,输出不是猫的概率为(1 - yi)
将所有情况连乘即为所求概率,连乘形式不方便,使用log变为求和,如下所示
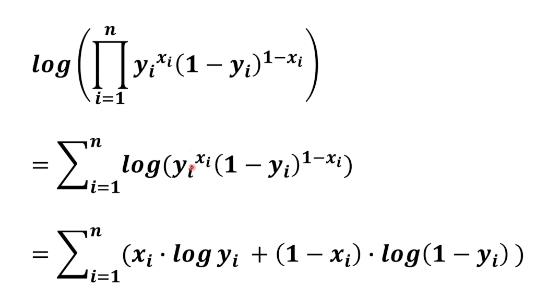
目标是最大化这个概率,而梯度下降是最小化损失函数,因此添加负号,即为损失函数
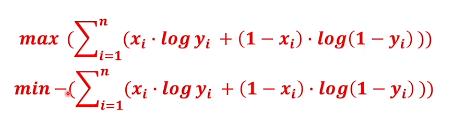
交叉熵
信息量
指一个事件从不确定到确定的难度有多大,信息量比较大说明难度比较高
看能带来确定性的多少。8支球队,比赛前每队夺冠的概率是1/8
- 如果获取信息1得知A队进决赛了,则夺冠概率从1/8变到了1/2
- 如果获取信息2得知A队夺冠了,则夺冠概率从1/8变到了1,
信息2提供的信息量更大,不同信息含有的信息量是不同的
定量计算信息量,以8支球队的比赛作为例子
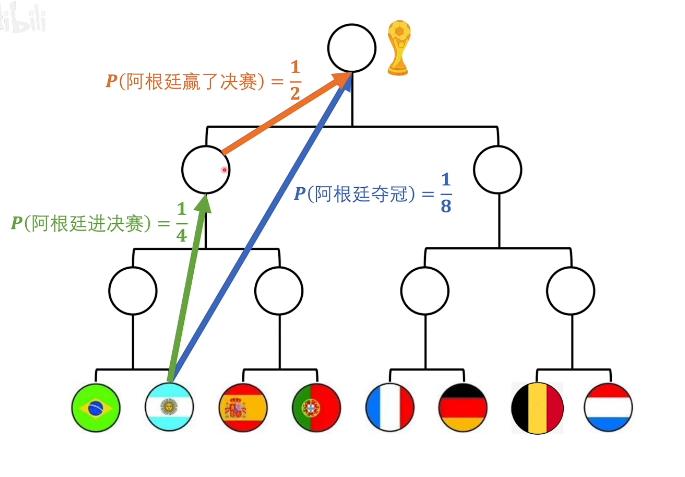
比赛之前每支球队夺冠的概率是1/8,则信息1:球队A夺冠,其提供的信息量与信息2:球队A进入决赛+信息3:球队A赢得决赛提供的信息量是相同的

-
这里可以理解成x1 = P(阿根廷进决赛),x2 = P(阿根廷赢了决赛)
则f(1/8) = f(x1*x2),f(1/4) = f(x1),f(1/2) = f(x2)
-
于是f(x1 * x2) = f(x1) + f(x2),根据公式确定对数运算
-
结合自变量x为概率,一开始概率越小,这个事件发生提供的信息量越多,因此应为单调递减函数,添负号
-
再确定底数为2,可以直接和计算机中的比特相结合
综上得信息量计算公式\\(\\ f(x) = -log_2^x\\)
熵
一个系统从原来的不确定到确定难度有多大
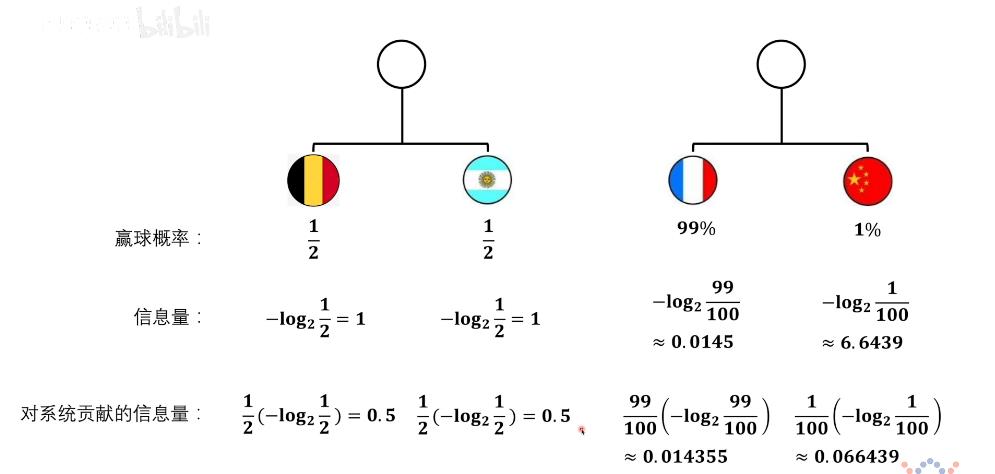
左边这场比赛对系统贡献的信息量(熵)为0.5+0.5=1,右边这场比赛对系统贡献的信息量(熵)为0.8,左系统的熵更大,不确定性更大
通过具体的例子,熵 := 系统提供信息量的期望
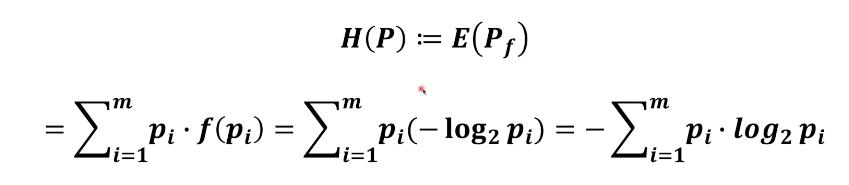
相对熵(KL散度)
两个概率系统P和Q,P || Q,P在前,以P为基准
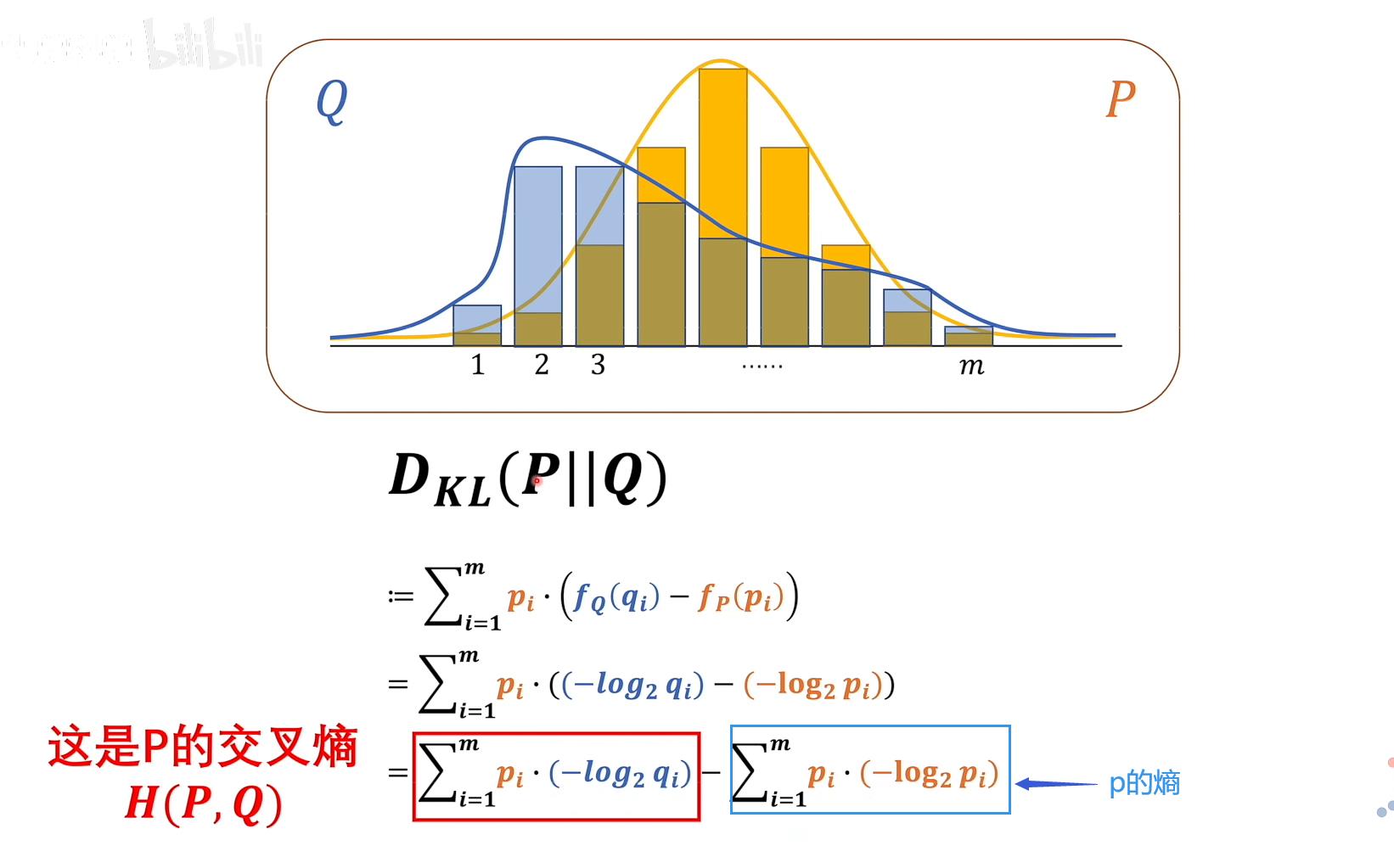
根据吉布斯不等式,KL散度必定是大于0的,也就是要最小化相对熵,只需最小化交叉熵即可,交叉熵越小表示两个概率模型越相近
交叉熵应用到神经网络
xi是标签,输入的图片是猫,其为1,否则为0
yi是输出预测为猫的概率,(W,b)是权重和偏置参数
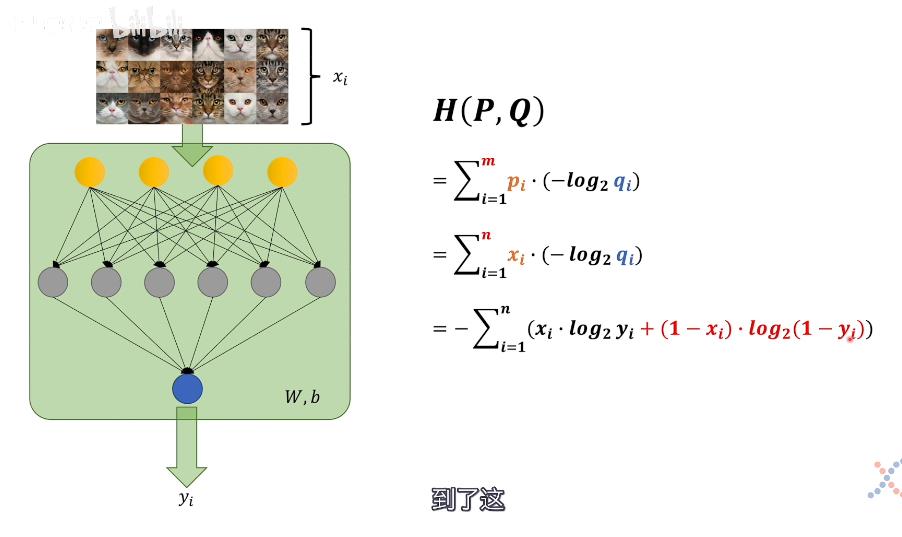
交叉熵公式中pi为基准,即正确的模型的概率,也就是xi,而qi这里要做一下变换,使得其能与定义相统一
- 当输入图片是猫时,即xi为1时,qi应为预测是猫的概率,即为yi
- 当输入图片不是猫时,即xi为0时,qi应为预测不是猫的概率,即为1-yi
综上得出交叉熵损失函数
以上是关于损失函数的主要内容,如果未能解决你的问题,请参考以下文章