Prometheus&Grafana基本使用
Posted 微笑刺客D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus&Grafana基本使用相关的知识,希望对你有一定的参考价值。
Prometheus介绍
Prometheus 是一套开源的系统监控与报警框架,以便于我们能够监控生产环境下的应用与服务。启发于 Google 的 BorgMon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入CNCF(Cloud Native Computing Foundation),成为受欢迎度仅次于 Kubernetes 的项目。

Prometheus特点
作为新一代的监控框架,Prometheus 具有以下特点:
- 多维度数据模型:
- 时间序列数据通过 metric 名和键值对来区分。
- 所有的 metrics 都可以设置任意的多维标签。
- 数据模型更随意,不需要刻意设置为以点分隔的字符串。
- 可以对数据模型进行聚合,切割和切片操作。
- 支持双精度浮点类型,标签可以设为全 unicode。
- 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
- 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
- 高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
- 使用 pull 模式采集时序数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
- 可以采用 push gateway 的方式把时序数据推送至 Prometheus server 端。
- 可以通过服务发现或者静态配置去获取监控的 targets。
- 支持多种可视化图形界面,比如Grafana等。
Prometheus组件
Prometheus server
主要负责数据采集和存储,提供PromQL查询语言的支持。包含了三个组件:
- Retrieval: 获取监控数据
- TSDB: 时间序列数据库(Time Series Database),我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。具备以下特点:大部分时间都是顺序写入操作,很少涉及修改数据删除操作都是删除一段时间的数据,而不涉及到删除无规律数据读操作一般都是升序或者降序
- HTTP Server: 为告警和出图提供查询接口
Metrics collection
主要负责指标的采集,其次将指标主动或被动交付给Prometheus Server
- Job/Exporters: 数据采集组件,负责从目标处(主机/数据库/服务/容器/...)搜集数据,并将其转化为Prometheus支持的格式。已有一系列可用,面向各基础设施的采集工具可直接使用。组件完成数据采集后,等待Prometheus Server拉取。
- Short-lived Jobs&Pushgateway: 支持临时Job主动推送指标到中间网关,进而等待Prometheus Server拉取。
Service discovery
- Kubernetes: 支持从Kubernetes中自动发现服务和采集信息。
- file_sd: 通过配置文件来实现服务的自动发现。
Alerting
通过相关的告警配置,对触发阈值的告警通过页面展示、短信和邮件通知的方式告知运维人员。
Visualization
通过PromQL语句查询指标信息,并在页面展示。可使用Prometheus自带UI界面,或是使用内容展示更加丰富的Grafana。也可调用API来获取监控指标。
Prometheus部署
准备好了两台服务器,用来模拟指标采集,其中一台服务器用来指标数据的收集,另一台用来部署Prometheus Server。

指标数据收集
从三个角度去收集指标数据,从主机指标,容器指标以及容器服务指标分别收集。

主机指标
为收集服务器指标数据,使用node_exporter,此处为了简便,使用容器安装,但最好是直接安装在主机上,以避免指标数据收集不准确。
docker run -d \\
--name StarCityNodeExporter \\
--restart=always \\
--net="host" \\
--pid="host" \\
-v "/proc:/host/proc:ro" \\
-v "/sys:/host/sys:ro" \\
-v "/:/rootfs:ro" \\
-e TZ=Asia/Shanghai \\
-v /etc/localtime:/etc/localtime \\
prom/node-exporter \\
--path.procfs=/host/proc \\
--path.rootfs=/rootfs \\
--path.sysfs=/host/sys \\
--collector.filesystem.ignored-mount-points=\'^/(sys|proc|dev|host|etc)($$|/)\'
可访问http://host:9100/metrics,查看指标数据

容器指标
再安装一个针对主机上所有容器的指标收集器cAdvisor,能够收集所有容器的CPU,内存,网络等使用情况。
docker run \\
--volume=/:/rootfs:ro \\
--volume=/var/run:/var/run:ro \\
--volume=/sys:/sys:ro \\
--volume=/var/lib/docker/:/var/lib/docker:ro \\
--volume=/dev/disk/:/dev/disk:ro \\
--publish=58080:8080 \\
--detach=true \\
--name=StarCityCAdvisor \\
--privileged \\
--device=/dev/kmsg \\
google/cadvisor
可访问http://host:58080/containers,查看指标数据

容器服务指标
以及收集RabbitMQ指标的收集器RabbitMQ_exporter,--net=container:RabbitMQ容器名(此处我本地RabbitMQ容器名为StarCityRabbitMQ),需要注意,在创建RabbitMQ时候容器开放9419端口。
docker run --name StarCityRabbitMQExporter -d --net=container:StarCityRabbitMQ kbudde/rabbitmq-exporter
可访问http://host:9419/metrics,查看指标数据

Prometheus Server
配置文件挂载目录
mkdir -p /opt/prometheus/data
chmod -R 777 /opt/prometheus/data
配置Prometheus文件
cd /opt/prometheus/
touch prometheus.yml
此处为了方便,直接用winscp编辑了prometheus.yml文件
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- \'Prometheus Server Host:9090\'
labels:
appname: Prometheus
- job_name: node
scrape_interval: 10s
static_configs:
- targets:
- \'Metrics Host:9100\'
labels:
appname: node
- job_name: cadvisor
static_configs:
- targets:
- \'Metrics Host:58080\'
- job_name: rabbitmq
scrape_interval: 10s
static_configs:
- targets:
- \'Metrics Host:9419\'
labels:
appname: rabbitmq
搭建Prometheus容器
docker run -d \\
--name StarCityPrometheus \\
--restart=always \\
-p 9090:9090 \\
-v /opt/prometheus/data:/prometheus \\
-e TZ=Asia/Shanghai \\
-v /etc/localtime:/etc/localtime \\
-v /opt/prometheus:/etc/prometheus \\
prom/prometheus
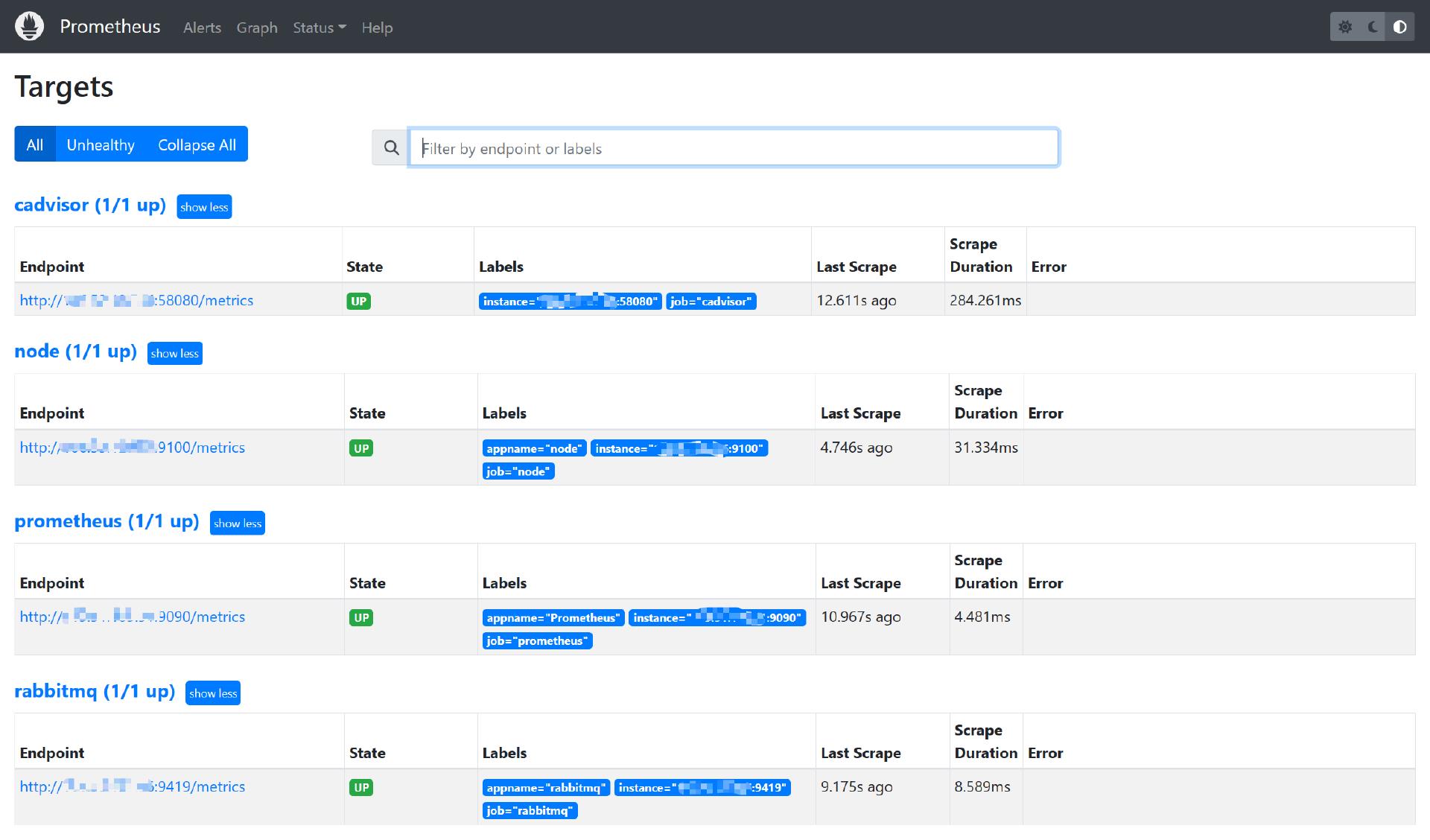
可通过http://host:9090/targets,访问Prometheus的UI页面查看prometheus.yml中配置的指标采集组件信息及情况。
Grafana
介绍
Grafana使你能够把来自不同数据源比如Elasticsearch, Prometheus, Graphite, influxDB等多维度的数据以绚丽的图表展示出来。它也能基于你的metrics数据发出告警。当一个告警状态改变时,它能通过email,slack或者其他途径发出通知。

搭建Grafana
docker run -d --name StarCityGrafana --restart=always -p 3000:3000 grafana/grafan
可访问http://host:3000,初始化用户名密码:admin/admin(首次进入后可改密码或跳过)。
设置数据源

选择Prometheus作为数据源,从其中读取数据,用于图表展示。

设置Prometheus地址与其他参数

导入仪表
已有许多设置好的,图表丰富的模板我们可以直接从模板库中导入使用。

对于主机层面的node_exporter指标收集器,此处使用id 8919

对于容器层面的cadvisor指标收集器,此处使用id 13112
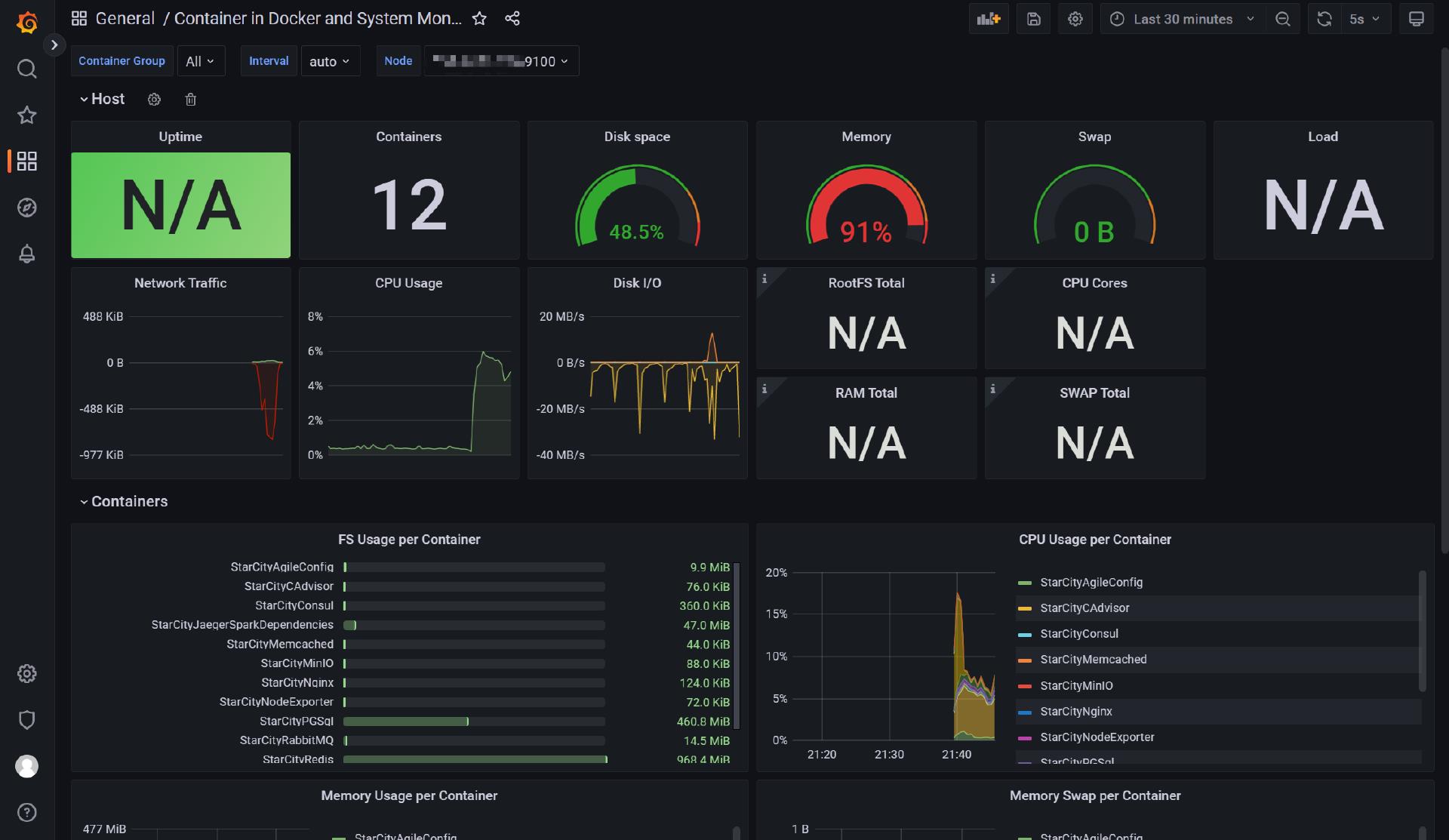
对于容器服务层面的rabbitmq的指标收集器,此处使用id 4279

2023-01-31,望技术有成后能回来看见自己的脚步
以上是关于Prometheus&Grafana基本使用的主要内容,如果未能解决你的问题,请参考以下文章