Numpy基本使用方法
Posted Thank CAT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Numpy基本使用方法相关的知识,希望对你有一定的参考价值。
Numpy基本使用方法
第一节
创建数组
import numpy as np
import random
# 创建数组
a = [1, 2, 3, 4, 5]
a1 = np.array(a)
print(a1) # [1 2 3 4 5]
b = range(10)
b1 = np.array(b)
print(b1) # [0 1 2 3 4 5 6 7 8 9]
数组的类名
# 数组的类名
print(type(a1)) # <class \'numpy.ndarray\'>
print(type(b1)) # <class \'numpy.ndarray\'>
数据的类型
# 数据的类型
print(a1.dtype) # int32
c1 = np.array([random.random() for i in range(10)])
print(c1)
# [0.65076793 0.78410146 0.94405112 0.58741766 0.23018049 0.80708392 0.5297858 0.14736833 0.53402873 0.21310533]
print(c1.dtype) # float64
d1 = np.array([True, False, False, True])
print(d1.dtype) # bool
指定数组类型
# 指定数组类型
a2 = np.array(a, dtype=float)
print(a2.dtype) # float64
a3 = np.array(a, dtype="float")
print(a2.dtype) # float64
修改数组类型
# 修改数组类型
d2 = d1.astype(int)
print(d2) # [1 0 0 1]
print(d2.dtype) # int32
a4 = a1.astype(dtype="float")
print(a4) # [1. 2. 3. 4. 5.]
print(a4.dtype) # float64
修改浮点型小数位
# 修改浮点型小数位
print(c1)
# 156 0.41847005 0.27127742 0.59553829 0.40378794 0.90308214 0.86897877 0.20906481 0.1832515]
c2 = c1.round(2) # 保留两位小数
print(c2)
# [0.35 0.78 0.93 0.63 0.81 0.15 0.95 0.21 0.29 0.48]
完整代码
import numpy as np
import random
# 创建数组
a = [1, 2, 3, 4, 5]
a1 = np.array(a)
print(a1) # [1 2 3 4 5]
b = range(10)
b1 = np.array(b)
print(b1) # [0 1 2 3 4 5 6 7 8 9]
# 数组的类名
print(type(a1)) # <class \'numpy.ndarray\'>
print(type(b1)) # <class \'numpy.ndarray\'>
# 数据的类型
print(a1.dtype) # int32
c1 = np.array([random.random() for i in range(10)])
print(c1)
# [0.65076793 0.78410146 0.94405112 0.58741766 0.23018049 0.80708392 0.5297858 0.14736833 0.53402873 0.21310533]
print(c1.dtype) # float64
d1 = np.array([True, False, False, True])
print(d1.dtype) # bool
# 指定数组类型
a2 = np.array(a, dtype=float)
print(a2.dtype) # float64
a3 = np.array(a, dtype="float")
print(a2.dtype) # float64
# 修改数组类型
d2 = d1.astype(int)
print(d2) # [1 0 0 1]
print(d2.dtype) # int32
a4 = a1.astype(dtype="float")
print(a4) # [1. 2. 3. 4. 5.]
print(a4.dtype) # float64
# 修改浮点型小数位
print(c1)
# 156 0.41847005 0.27127742 0.59553829 0.40378794 0.90308214 0.86897877 0.20906481 0.1832515]
c2 = c1.round(2) # 保留两位小数
print(c2)
# [0.35 0.78 0.93 0.63 0.81 0.15 0.95 0.21 0.29 0.48]
第二节
数组的形状
import numpy as np
# 数组的形状
a = np.array([[3, 4, 5, 6, 7, 8], [4, 5, 6, 7, 8, 9]])
print(a.shape) # (2, 6) 2行6列
修改数组的形状
# 修改数组的形状
a1 = a.reshape(3, 4) # 修改为3行4列
print(a1.shape) # (3, 4) 3行4列
print(a1)
"""
[[3 4 5 6]
[7 8 4 5]
[6 7 8 9]]
"""
print(a.shape) # (2, 6) 修改数组形状会指向新的对象,不会修改原数组本身
把数据转换成一维数组
# 把数据转换成一维数组
a2 = a.flatten()
print(a2) # [3 4 5 6 7 8 4 5 6 7 8 9]
数组的计算/广播机制,在运算过程中加减乘除的值被广播到所有元素上
# 数组的计算/广播机制,在运算过程中加减乘除的值被广播到所有元素上
b = a*10
print(b) # [[30 40 50 60 70 80][40 50 60 70 80 90]]
c = np.arange(20)
print(c) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
c1 = c.reshape(4, 5)
print(c1)
"""
[[0 1 2 3 4]
[5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
"""
d = np.array([1, 1, 1, 1, 1])
d1 = d.reshape(1, 5)
print(d1) # [[1 1 1 1 1]] (1, 5)
print(c1 - d1)
"""
所有元素全部 -1,即所有行全部减d1这个1行5列的数组
[[-1 0 1 2 3]
[4 5 6 7 8]
[9 10 11 12 13]
[14 15 16 17 18]]
"""
# 广播的原则:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
完整代码
import numpy as np
# 数组的形状
a = np.array([[3, 4, 5, 6, 7, 8], [4, 5, 6, 7, 8, 9]])
print(a.shape) # (2, 6) 2行6列
# 修改数组的形状
a1 = a.reshape(3, 4) # 修改为3行4列
print(a1.shape) # (3, 4) 3行4列
print(a1)
"""
[[3 4 5 6]
[7 8 4 5]
[6 7 8 9]]
"""
print(a.shape) # (2, 6) 修改数组形状会指向新的对象,不会修改原数组本身
# 把数据转换成一维数组
a2 = a.flatten()
print(a2) # [3 4 5 6 7 8 4 5 6 7 8 9]
# 数组的计算/广播机制,在运算过程中加减乘除的值被广播到所有元素上
b = a*10
print(b) # [[30 40 50 60 70 80][40 50 60 70 80 90]]
c = np.arange(20)
print(c) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
c1 = c.reshape(4, 5)
print(c1)
"""
[[0 1 2 3 4]
[5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
"""
d = np.array([1, 1, 1, 1, 1])
d1 = d.reshape(1, 5)
print(d1) # [[1 1 1 1 1]] (1, 5)
print(c1 - d1)
"""
所有元素全部 -1,即所有行全部减d1这个1行5列的数组
[[-1 0 1 2 3]
[4 5 6 7 8]
[9 10 11 12 13]
[14 15 16 17 18]]
"""
# 广播的原则:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
第三节
读取CSV文件
import numpy as np
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
# 将文件对象通过numpy.loadtxt方法 实例化
t2 = np.loadtxt(us_file_path, delimiter=",", dtype="int")
print(t2)
print(t2.shape) # (1688, 4)
索引
# 取行
print(t2[2]) # 取索引为2的行,即第三行
""" [5845909 576597 39774 170708] """
# 取连续的多行
print(t2[2:]) # 取索引为2开始的所有行
"""[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
"""
# 取不连续的多行
print(t2[[2, 3, 4]]) # 取索引为2,3,4的行
""""
[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]]
"""
# t2[2] = t2[2,] = t2[2, :] 效果是一样的,都是取索引为2的行
# 取列
print(t2[:, 0]) # 取索引为0的所有元素,即第一列
""" [4394029 7860119 5845909 ... 142463 2162240 515000] """
# 取连续多列
print(t2[:, 2:]) # 取索引为2的列开始往后所有的列
""" [[ 5931 46245]
[ 26679 0]
[ 39774 170708]
...
[ 148 279]
[ 1384 4737]
[ 195 4722]] """
# 取不连续的多行
print(t2[:, [2, 3]]) # 取索引为2,3的列
""" [[ 5931 46245]
[ 26679 0]
[ 39774 170708]
...
[ 148 279]
[ 1384 4737]
[ 195 4722]] """
# 取行和列交叉的值
print(t2[2, 3]) # 取第二行和第三列交叉的值
""" 170708 """
# 取多个不相邻的点
# 取出来的结果是(0,0) (2,1) (2,3)(行,列)
print(t2[[0, 2, 2], [0, 1, 3]])
""" [4394029 576597 170708] """
完整代码
import numpy as np
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
# 将文件对象通过numpy.loadtxt方法 实例化
t2 = np.loadtxt(us_file_path, delimiter=",", dtype="int")
print(t2)
print(t2.shape) # (1688, 4)
# 取行
print(t2[2]) # 取索引为2的行,即第三行
""" [5845909 576597 39774 170708] """
# 取连续的多行
print(t2[2:]) # 取索引为2开始的所有行
"""[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
"""
# 取不连续的多行
print(t2[[2, 3, 4]]) # 取索引为2,3,4的行
""""
[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]]
"""
# t2[2] = t2[2,] = t2[2, :] 效果是一样的,都是取索引为2的行
# 取列
print(t2[:, 0]) # 取索引为0的所有元素,即第一列
""" [4394029 7860119 5845909 ... 142463 2162240 515000] """
# 取连续多列
print(t2[:, 2:]) # 取索引为2的列开始往后所有的列
""" [[ 5931 46245]
[ 26679 0]
[ 39774 170708]
...
[ 148 279]
[ 1384 4737]
[ 195 4722]] """
# 取不连续的多行
print(t2[:, [2, 3]]) # 取索引为2,3的列
""" [[ 5931 46245]
[ 26679 0]
[ 39774 170708]
...
[ 148 279]
[ 1384 4737]
[ 195 4722]] """
# 取行和列交叉的值
print(t2[2, 3]) # 取第二行和第三列交叉的值
""" 170708 """
# 取多个不相邻的点
# 取出来的结果是(0,0) (2,1) (2,3)(行,列)
print(t2[[0, 2, 2], [0, 1, 3]])
""" [4394029 576597 170708] """
第四节
将数组中的nan更换为对应列的均值
import numpy as np
t = np.arange(24)
t1 = t.reshape(4, 6).astype("float")
t1[1, 2:] = np.nan
print(t1)
print("*"*100)
for i in range(t1.shape[1]):
temp_col = t1[:, i]
# nan == nan -> Ture
# np.count_nonzero(temp_col != temp_col)返回的是对布尔类型的统计True=1,False=0、
nan_num = np.count_nonzero(temp_col != temp_col)
# print(temp_col != temp_col)
"""
[False False False False] 0
[False False False False] 0
[False False False False] 0
[True False False False] 1
[True False False False] 1
[True False False False] 1
"""
if nan_num != 0: # 不为零则说明这一列里面有nan
# 将有nan的列中的不为nan的元素赋值给temp_not_nan_col
temp_not_nan_col = temp_col[temp_col == temp_col]
# 选中当前为nan的位置,把值赋值为不为nan的均值
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
print(t1)
"""
result
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. nan nan nan nan]
[12. 13. 14. 15. 16. 17.]
[18. 19. 20. 21. 22. 23.]]
****************************************************************************************************
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 12. 13. 14. 15.]
[12. 13. 14. 15. 16. 17.]
[18. 19. 20. 21. 22. 23.]]
"""
第五节
numpy与matplotlib结合
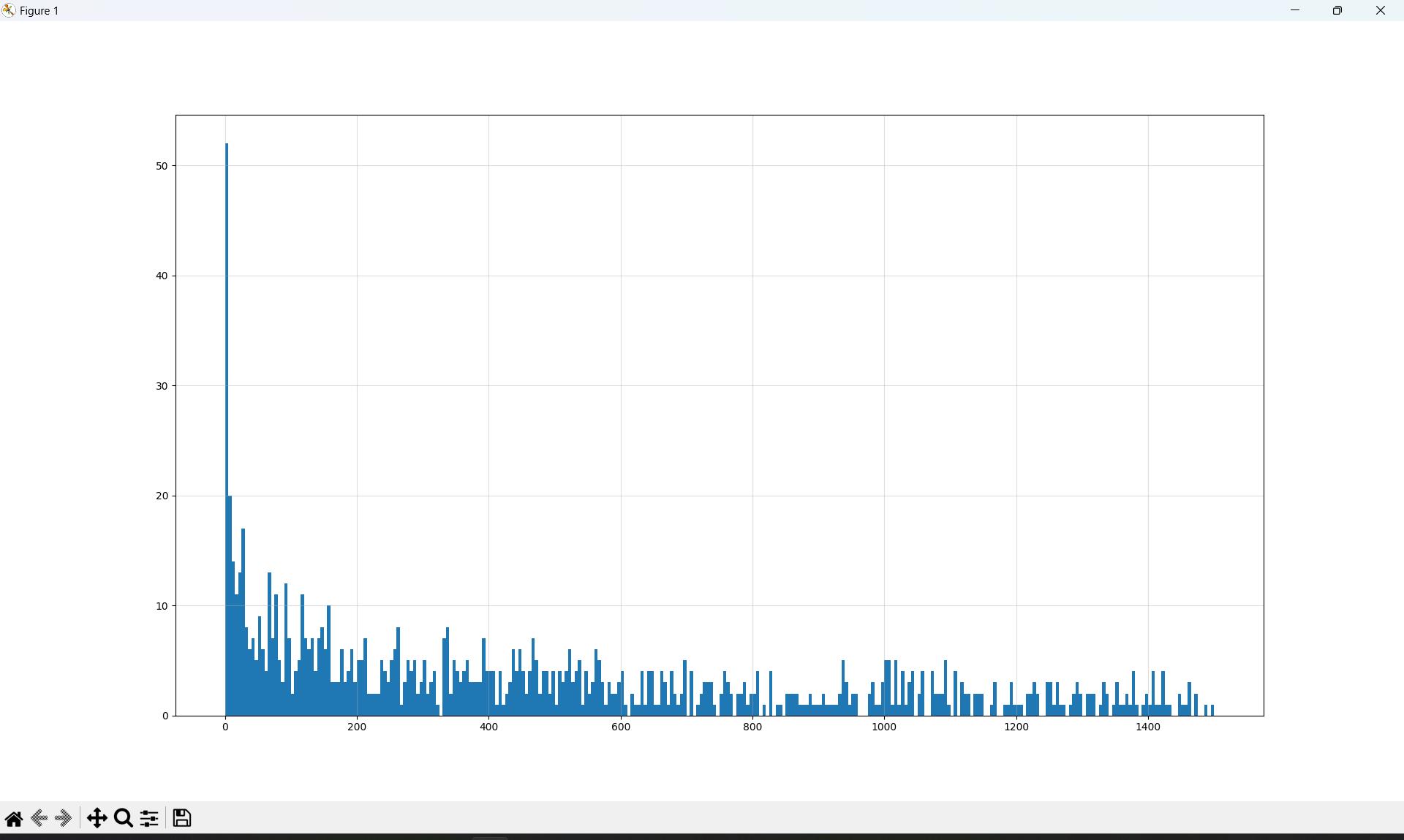
美国YTB视频评论的直方图
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
t_us = np.loadtxt(us_file_path, delimiter=",", dtype=int)
# 取评论的数据
t_us_comments = t_us[:, -1]
# 选择比5000小的数据
t_us_comments = t_us_comments[t_us_comments <= 1511]
# 组距
d = 50
# 组数 = (max-min)//组距
bin_nums = (t_us_comments.max() - t_us_comments.min()) // 5
print(bin_nums)
# 绘图
plt.figure(figsize=(20, 8), dpi=80)
plt.hist(t_us_comments, bin_nums)
plt.grid(alpha=0.4)
plt.show()
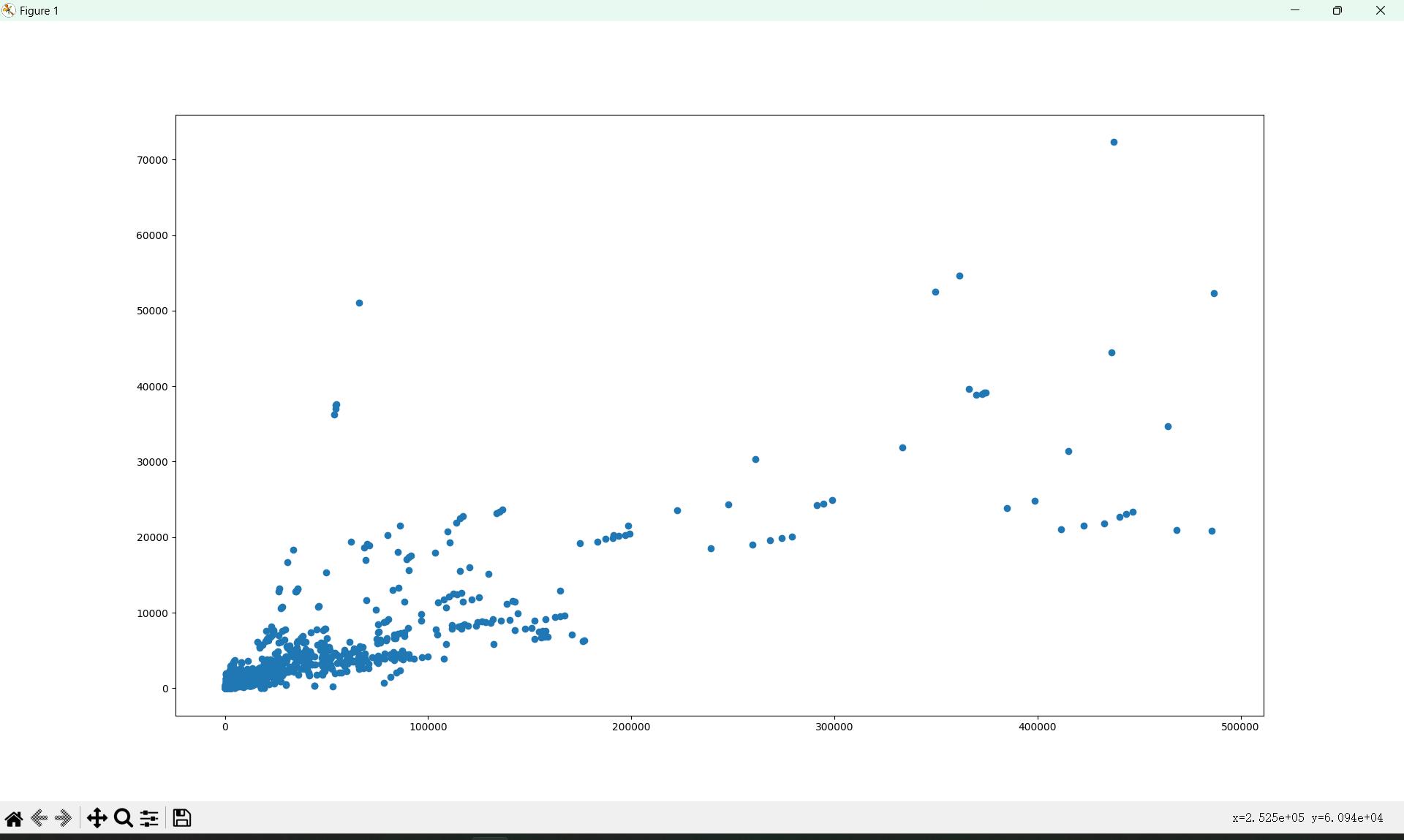
英国YTB视频评论和喜欢的散点图
import numpy as np
from matplotlib import pyplot as plt
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
t_uk = np.loadtxt(uk_file_path, delimiter=",", dtype=int)
# 选择喜欢的书比50万小的数据
t_uk = t_uk[t_uk[:, 1] <= 500000]
# 错误写法t_uk = t_uk[: , 1] <= 500000 这种写法反馈的是bool类型
# 分别取出喜欢的列,和评论的列
t_uk_comment = t_uk[:, -1]
t_uk_like = t_uk[:, 1]
# 绘图展示
plt.figure(figsize=(20, 8), dpi=80)
plt.scatter(t_uk_like, t_uk_comment)
plt.show()
以上是关于Numpy基本使用方法的主要内容,如果未能解决你的问题,请参考以下文章