Python对中国电信消费者特征预测:随机森林朴素贝叶斯神经网络最近邻分类逻辑回归支持向量回归(SVR)
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python对中国电信消费者特征预测:随机森林朴素贝叶斯神经网络最近邻分类逻辑回归支持向量回归(SVR)相关的知识,希望对你有一定的参考价值。
全文链接:http://tecdat.cn/?p=31868
原文出处:拓端数据部落公众号
分析师:Chang Gao
随着大数据概念的兴起,以数据为基础的商业模式越来越流行,用所收集到的因素去预测用户的可能产生的行为,并根据预测做出相应反应成为商业竞争的核心要素之一。单纯从机器学习的角度来说,做到精准预测很容易,但是结合具体业务信息并做出相应反应并不容易。预测精确性是核心痛点。
解决方案
任务/目标
根据所收集到的用户特征用机器学习方法对特定的属性做预测。
数据源准备
数据质量低或者缺失,会影响模型预测效果。在建立的一个合理的模型之前,对数据要进行清理。对于数据中的连续变量和离散变量进行标准化和因子化处理,以使后面的预测更加准确。
因子化标准化处理
首先将数据进行属性分类,分为名义变量(\'性别\', \'归属地\', \'换机频率\', \'终端品牌\', \'终端类型\', \'最近使用操作系统偏好\',\'渠道类型描述\', \'是否欠费\', \'产品大类\', \'产品分类\')和间隔变量(\'年龄\',\'在网时长\',\'上网流量使用\',\'漫游流量使用\', \'总收入\',\'增值收入\',\'流量收入\',\'短信收入\',\'彩信收入\',\'语音收入\')。
将数据处理成算法容易处理模式:
- 朴素贝叶斯数据集
朴素贝叶斯方法需要离散化数据,于是按照分为点对于连续数据进行离散化处理。然后将所有的离散变量进行因子化。
- 神经网络,支持向量机与最近邻所需数据:处理以保证在一个数量级
为方便起见,用one-hot编码因子变量。对于连续变量,将数据映射到0,1之间 且不改变分布。
- 随机森林与回归所需数据:直接使用因子化的原始数据。
划分训练集和测试集
考虑到最终模型会在已知某些变量的同时,预测一些未知的特征,为了更真实的测试模型效果,将数据集分为分训练集和测试集。
建模
用其他用户特征,用训练集进行调参,预测用户“收否欠费”这个属性。
1. 随机森林
用随机的方式建立一个森林,森林由很多决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
两个主要参数:n_estimators: 多少树 max_features: 每个树随机选择多少特征
比较不同参数预测结果的neg_log_loss,选择最优的参数(score最大的)
2. 朴素贝叶斯
3. 神经网络
在PyTorch框架下面进行网络的搭建及运算
需要调节的参数:batch_size=[200,500,1000], 神经元个数=[16,32,64,128]
学习率=[0.01,0.005,0.001,0.0005,0.0001,0.00005,0.00001] 再微调,epoch=[10,20,30,40,50,60]
调参策略,第一调到最优后选择下一个进行调参,并不进行网格搜索
(a) 数据形式调整并进行小批次数据训练(批训练):每次选择1000数据集进行拟合,避免局部最优。
(b) 模型建立:我们采用了输入层+两层隐藏层+输出层,的三层神经网络,确定三层隐藏层的个数:我们比较32,64 逐一变化,择取最优。
(c) 训练网络:优化器:采用了Adam而不是简单的SGD,主要也是避免局部最优的问题。分类问题我们采用了普遍使用的交叉熵损失损失,但是与普遍的交叉熵相比,由于数据过于不平衡,因此我们增加了占比较少的数据的损失权重
4. 最近邻分类
最近邻分类:主要需要确定n_neighbors,我们比较n_neighbors=3,5,7,9情况下neg_log_loss
5. 逻辑回归:这里主要也是需要对变量进行筛选
由于数据非常不平衡,因此我们使用AUC作为标准进行衡量。逐个遍历自变量并将自变量名连接起来,升序排序accuracy值,最新的分数等于最好的分数。
6. 支持向量回归(SVR):使用网格搜索法最佳C值和核函数
模型准确性判定:
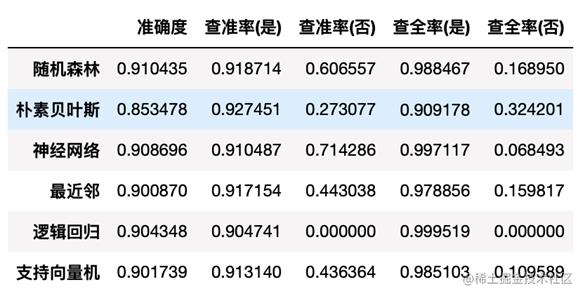
准确度/查准率/查全率
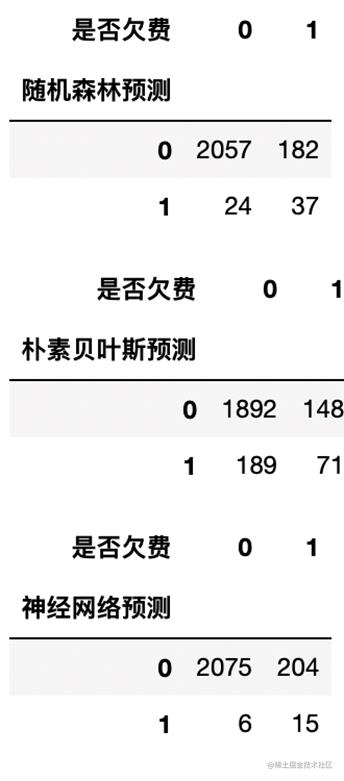
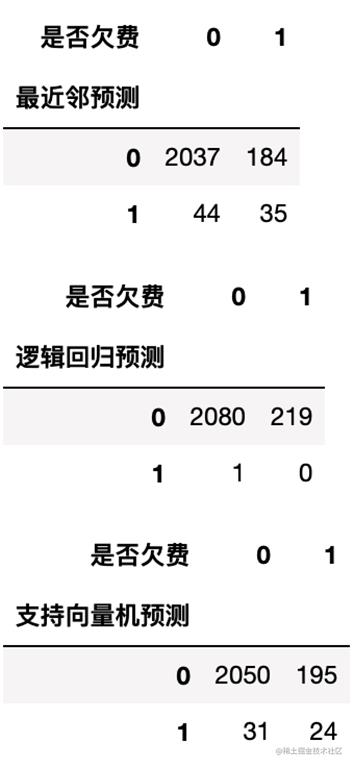
混淆矩阵
ROC曲线
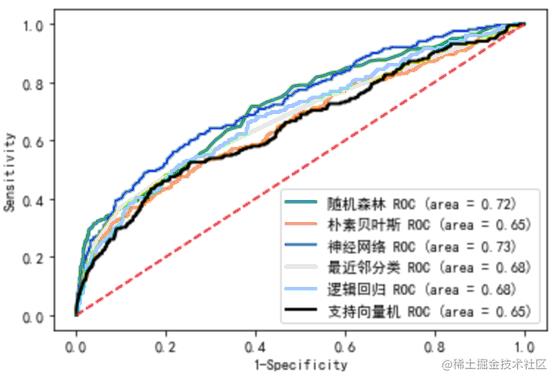 在此案例中,从准确度来看,随机森林模型的分类最好。从查准率来看,神经网络模型的分类最好。从查全率来看,逻辑回归模型的分类效果最好。同理,由上图可知,在ROC曲线下对于“是否欠费”这个因变量,神经网络模型的分类效果最好,模型的ROC曲线下面积最高,拟合最优。其余模型的拟合效果显著。
在此案例中,从准确度来看,随机森林模型的分类最好。从查准率来看,神经网络模型的分类最好。从查全率来看,逻辑回归模型的分类效果最好。同理,由上图可知,在ROC曲线下对于“是否欠费”这个因变量,神经网络模型的分类效果最好,模型的ROC曲线下面积最高,拟合最优。其余模型的拟合效果显著。
但事实上,评估效果不能只看统计数据,要综合考虑现实情况,预测精度,模型可解释性和客户偏好等因素综合考虑。预测结果仅作为参考一个权重值,还需要专家意见,按照一定的权重来计算。

关于分析师

在此对Chang Gao对本文所作的贡献表示诚挚感谢,她在复旦大学完成了统计学学位,擅长数据挖掘、机器学习、数据采集。
最受欢迎的见解
1.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像
3.python中使用scikit-learn和pandas决策树
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
以上是关于Python对中国电信消费者特征预测:随机森林朴素贝叶斯神经网络最近邻分类逻辑回归支持向量回归(SVR)的主要内容,如果未能解决你的问题,请参考以下文章