分布式架构-可观测性-事件日志
Posted 只会一点java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构-可观测性-事件日志相关的知识,希望对你有一定的参考价值。
一、原理概览
日志用来记录系统运行期间发生过的离散事件。日志就像阳光与空气,无可或缺却不太被重视。打印日志简单,也并不简单,尤其是复杂的分布式系统,就很难只依靠 tail、grep、awk 来从日志中挖掘信息了,往往还要有专门的全局查询和可视化功能。此时,从打印日志到分析查询之间,还隔着收集、缓冲、聚合、加工、索引、存储等若干个步骤,如下图所示。

1.1 ELK
提到日志收集,大家最熟悉的套件莫过于ELK了,ELK 到底是什么呢? “ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是一个搜索和分析引擎。
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
1.2 Elastic Stack
Elastic Stack 是 ELK Stack 的更新换代产品(加入了Beats轻量级数据采集组件)。为什么是Elastic Stack呢?www.elastic.co官网的UED是真的很有趣~,不信看官网介绍图(官网链接):

接下来以Elastic Stack为例,详细讲解每个步骤的目的与方法。
二、详细步骤
2.1 输出
好的日志应该能做到像“流水账”一样,无有遗漏地记录信息,格式统一,内容恰当。恰当是指日志中不该出现的内容不要有,该有的不要少。
不要有:
- 避免打印敏感信息。任何程序员肯定都知道不该将密码,银行账号,身份证件这些敏感信息打到日志里。但一般没人管就不管了。一般安全部门或者架构师应该规范要求。
- 避免引用慢操作。日志中打印的信息应该是常量,如果需要调用远程服务,或者通过大量计算才能取到的话,那应该先考虑这项信息放到日志中是不是必要且恰当的。这个是比较危险的,可能导致日志打印延迟甚至丢失。
- 避免打印追踪诊断信息。日志中不要打印方法输入参数、输出结果、方法执行时长之类、整个实体对象的调试信息。日志的职责是记录事件,追踪诊断应由追踪系统去处理。
- 避免误导他人。日志中给日后调试除错的人挖坑是十分恶劣却又常见的行为。
要有:
- 处理请求时的 TraceID。请求没有附带 TraceID,应该自动生成。TraceID 是链路追踪里的概念,类似的还有用于标识进程内调用状况的 SpanID,在 Java 程序中这些都可以用 Spring Cloud Sleuth 来自动生成。
- 系统运行过程中的关键事件。日志的职责就是记录事件,原则上只要有价值就应该去记录,但应判断清楚事件的重要程度,选定相匹配的日志的级别。
- 启动时输出配置信息。系统启动时或者配置中心变化时更新的配置,应将非敏感的配置信息输出到日志中,譬如连接的数据库、临时目录的路径等等,初始化配置的逻辑一般只会执行一次,不便于诊断时复现,所以应该输出到日志中。
2.2 收集与缓冲
分布式系统处理一个请求要跨越多个服务节点,为了能看到跨节点的全部日志,就要有能覆盖整个链路的全局日志系统。这个需求决定了每个节点输出日志到文件后,必须将日志文件统一收集起来集中存储、索引,由此便催生了专门的日志收集器。最初,ELK 中日志收集与加工聚合的职责都是由 Logstash 来承担的。后来,Elastic.co 公司将所有需要在服务节点中处理的工作整理成以Libbeat为核心的Beats 框架,并使用 Golang 重写了一个功能较少,却更轻量高效的日志收集器,这就是今天流行的Filebeat。
日志收集器不仅要保证能覆盖全部数据来源,还要尽力保证日志数据的连续性,这其实并不容易做到。日志不应该追求绝对的完整精确,只追求在代价可承受的范围内保证尽可能地保证较高的数据质量。一种最常用的缓解压力的做法是将日志接收者从 Logstash 和 Elasticsearch 转移至抗压能力更强的队列缓存,譬如在 Logstash 之前架设一个 Kafka 或者 Redis 作为缓冲层,面对突发流量,Logstash 或 Elasticsearch 处理能力出现瓶颈时自动削峰填谷,甚至当它们短时间停顿,也不会丢失日志数据。
2.3 加工与聚合
将日志集中收集之后,存入 Elasticsearch 之前,一般还要对它们进行加工转换和聚合处理。
- Logstash 的基本职能是把日志行中的非结构化数据,通过 Grok 表达式语法转换为上面表格那样的结构化数据,进行结构化的同时,还可能会根据需要,调用其他插件来完成时间处理(统一时间格式)、类型转换(如字符串、数值的转换)、查询归类(譬如将 IP 地址根据地理信息库按省市归类)等额外处理工作,然后以 JSON 格式输出到 Elasticsearch 中。
- 聚合是 Logstash 的另一个常见职能。在收集日志后自动生成某些常用的、固定的聚合指标,这种聚合就会在 Logstash 中通过聚合插件来完成。
2.4 存储与查询
2.4.1 存储与查询
经过收集、缓冲、加工、聚合的日志数据,终于可以放入 Elasticsearch 中索引存储了。Elasticsearch 是整个Elastic Stack技术栈的核心,其他步骤的工具,如 Filebeat、Logstash、Kibana 都有替代品,唯独 Elasticsearch 在日志分析这方面完全没有什么值得一提的竞争者,几乎就是解决此问题的唯一答案。Elasticsearch 的优势正好与日志分析的需求完美契合:
- 从数据特征的角度看,日志是典型的基于时间的数据流,日志虽然增长速度很快,但已写入的数据几乎没有再发生变动的可能。日志的数据特征决定了所有用于日志分析的 Elasticsearch 都会使用时间范围作为索引,全部索引都可以预先创建,这免去了动态创建的寻找节点、创建分片、在集群中广播变动信息等开销。
- 从数据价值的角度看,日志基本上只会以最近的数据为检索目标,早期的数据将逐渐失去价值。这点决定了可以很容易区分出冷数据和热数据,进而对不同数据采用不一样的硬件策略。譬如为热数据配备 SSD 磁盘和更好的处理器,为冷数据配备 HDD 磁盘和较弱的处理器,甚至可以放到更为廉价的对象存储(如阿里云的 OSS,腾讯云的 COS,AWS 的 S3)中归档。
注意,本节的主题是日志在可观测性方面的作用,另外还有一些基于日志的其他类型应用,譬如从日志记录的事件中去挖掘业务热点,分析用户习惯等等,这属于真正大数据挖掘的范畴,并不在我们讨论“价值”的范围之内,事实上它们更可能采用的技术栈是 HBase 与 Spark 的组合,而不是 Elastic Stack。
-
从数据使用的角度看,分析日志很依赖全文检索和即席查询,对实时性的要求是处于实时与离线两者之间的“近实时”,这些检索能力和近实时性,也正好都是 Elasticsearch 的强项。
2.4.2 UI展示
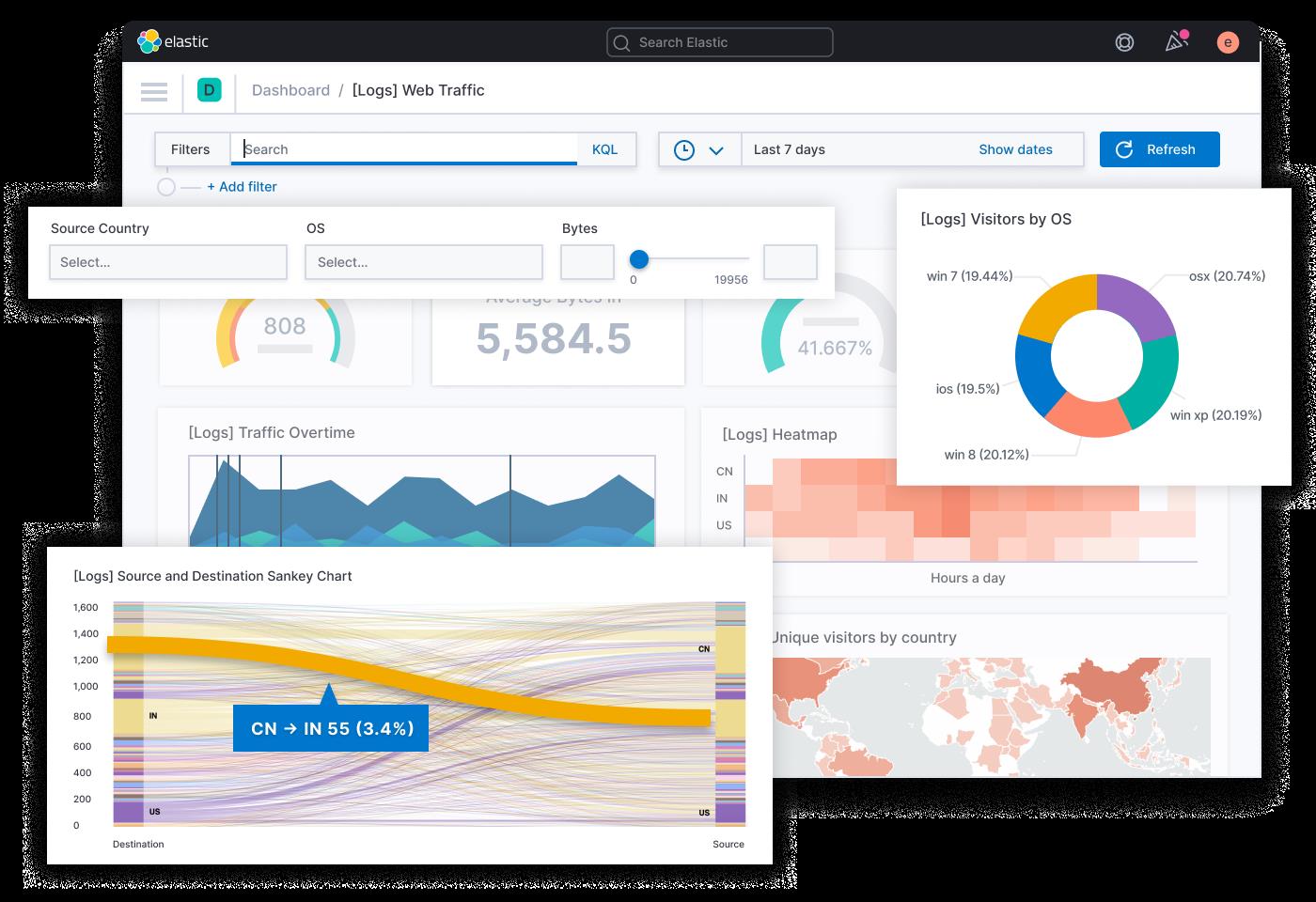
Elasticsearch 只提供了 API 层面的查询能力,通常搭配 Kibana 一起使用,Kibana 负责图形界面和展示。Kibana 宣传的核心能力是“探索数据并可视化”,即把存储在 Elasticsearch 中的数据被检索、聚合、统计后,定制形成各种图形、表格、指标、统计,以此观察系统的运行状态,找出日志事件中潜藏的规律和隐患。按 Kibana 官方的宣传语来说就是“一张图片胜过千万行日志”。如下图(图片来自Kibana 官网):
=========参考====================
学习整理自凤凰架构:http://icyfenix.cn/distribution/observability/
如果你觉得本文对你有点帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
以上是关于分布式架构-可观测性-事件日志的主要内容,如果未能解决你的问题,请参考以下文章