高效阅读源码的关键:构建核心抽象模型
Posted IvanEye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高效阅读源码的关键:构建核心抽象模型相关的知识,希望对你有一定的参考价值。
上一篇我们通过模块间的依赖关系确定了核心模块。
本篇是《如何高效阅读源码》专题的第七篇,我们来确定核心模块中的抽象模型
本节内容如下:
-
什么是抽象模型?
-
为什么要构建抽象模型?
-
如何构建抽象模型?
-
通过JUnit4演示如何构建抽象模型
什么是抽象模型?
我们都知道,主流编程范式有三种:过程式、面向对象和函数式。无论哪种编程范式,都是对现实世界的抽象,只是抽象方式不同而已:
-
面向过程编程将现实世界抽象为数据结构+方法(过程),通过方法的组合来解决问题
-
面向对象编程将现实世界抽象为一个个的对象,通过对象间的组合通信来解决问题
-
函数式编程将现实世界抽象为一个个的函数,通过函数间的组合来解决问题
抽象方式的不同导致了优缺点的不同。比如:面向对象可以很方便的增加类型,却很难在不修改已定义代码的前提下,为既有具体类实现一套既有的抽象方法(称为表达式问题);而函数式编程可以很方便的增加操作,但很难新增一个适应各种既有操作的类型。
PS:关于各种编程范式的优缺点不在此专题讨论范畴内,有兴趣的可自行了解
无论是哪种抽象方式,都是通过对现实问题进行建模,然后对这个模型的操作来解决问题。以面向对象为例,我们需要针对现实问题,创建一个个的对象,通过这些对象之间的通信来解决问题。这些对象所构成的模型,就称为「抽象模型」。当然,在面向对象里,也可以称为「对象模型」!
为什么要构建抽象模型?
在前文中,我们找到了核心模块,虽然只有两个,但是里面还是有很多类。我们将其展开(选中对应的包,然后按下E),剔除掉一些不重要的类,还是有几十个类。要梳理这些类关系及其之间的执行流程也不是一件简单的事情。当然,你也可以就这么硬撸!不过很明显,这不符合我们专栏的初衷,不够高效。
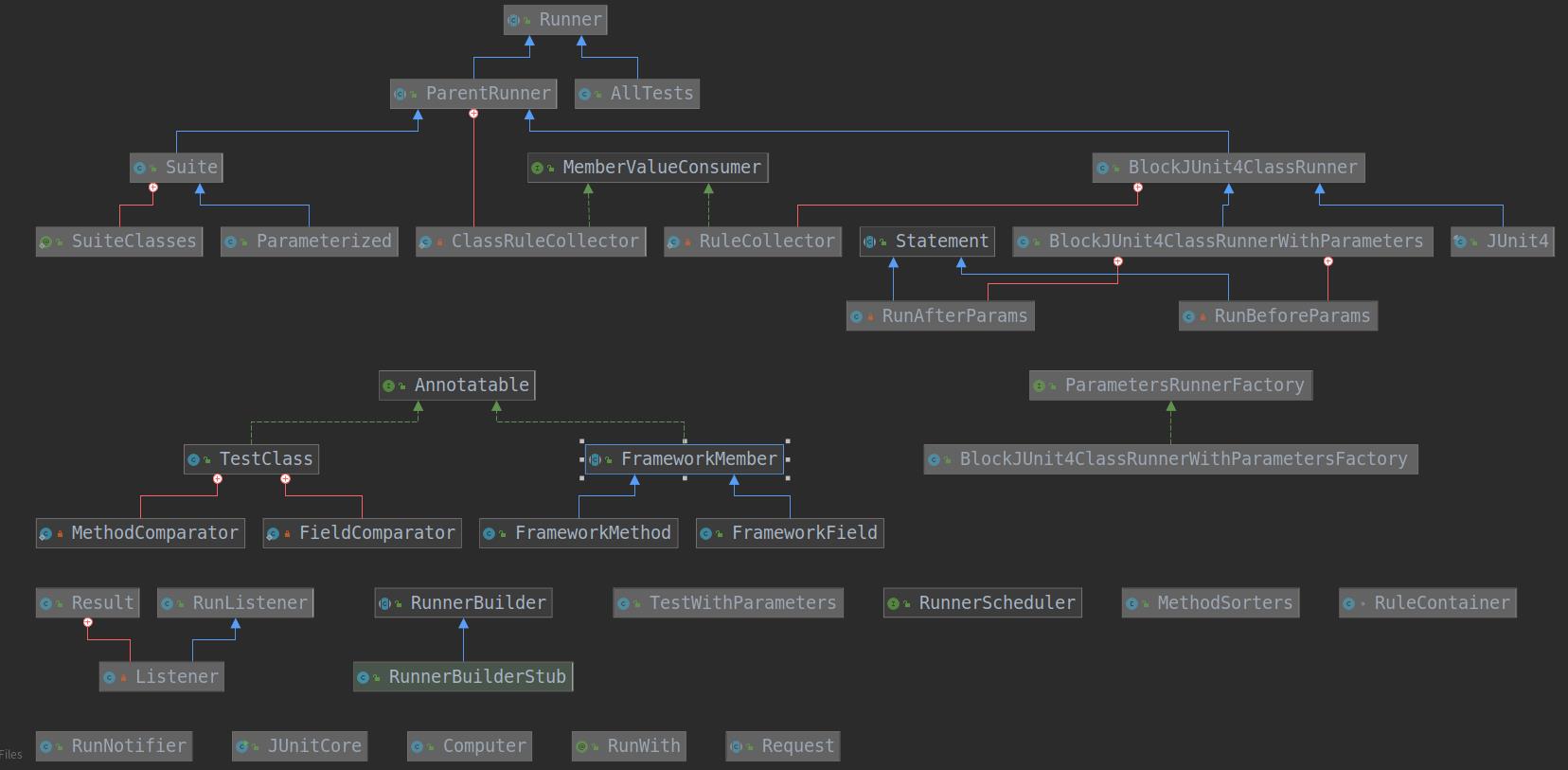
构建抽象模型能进一步缩小我们所要阅读的源码的量,或者更准确的说,是进一步缩小我们首先要阅读的源码的量。
前面说了,抽象模型是我们对现实问题的抽象,构成抽象模型的对象就是「核心对象」,其它对象都是为这些「核心对象」服务的。这也同样符合二八原则,能将我们首次需要阅读的代码量再减少80%!
如何构建抽象模型?
要构建抽象模型,我们需要先找到「核心对象」。找「核心对象」的方式和找「核心模块」的方式很类似,都是通过依赖关系来定位。但是具体方式还有差异,或者说定位「核心对象」的方法更精细。
我们在定位「核心模块」的过程中,只依据了模块之间的继承关系。实际上模块之间还有依赖、调用等关系,这些关系的整体结果才能完整的体现模块之间的关系,不过考虑到通过UML的方式展示,线条过多,不利于展示,故人为忽略了。
更精确的依赖关系分析是DSM,能够将模块、类之间的所有关系都统计出来。下面将通过DSM来演示如何定位核心对象。
DSM(Dependency Structure Matrix)表示类组之间的依赖关系。
示例
我们分析runner和runners模块来定位核心对象。
在IDEA中的菜单栏, 选择Analyze->Analyze Dependency Matrix。选择custom scope,点击后面的按钮,在弹出的窗口中选择runner和runners包(包括子包),点击右边的include按钮,最后点击OK。
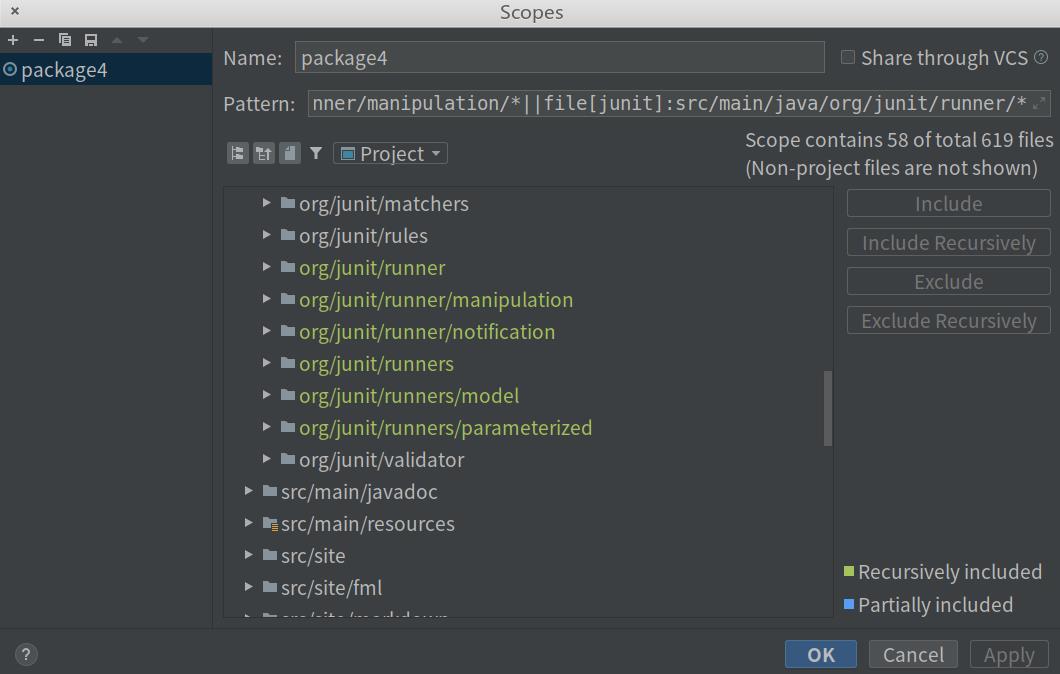
你将会得到下图:
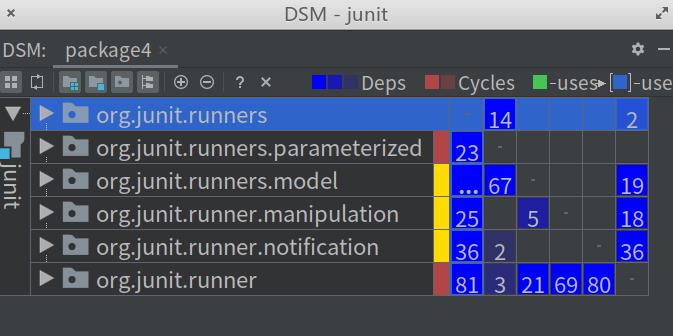

如果你是第一次使用DSM,看到这个图你可能一脸懵逼,这里简单解释一下:
-
每一行和每一列都表示一个模块/包/类,行和列对应。比如:第一行是org.junit.runners包,第一列也是org.junit.runners包;最后一行是org.junit.runner包,最后一列也是org.junit.runner包
-
对应的格子中的数字,表示对应的列(模块)在对应行(模块)的依赖。比如:第一行最后一列的2,表示org.junit.runner包有两处依赖了org.junit.runners包
-
纵向标出来的数字,表示选中的行(模块)对列(模块)的依赖。比如:最后一行第一列的81表示org.junit.runners包有81处依赖了org.junit.runner包
-
包后面的颜色标识是一个快速的依赖提示:红色表示模块相互有依赖;黄色表示选中模块依赖标识的模块;绿色表示标识模块依赖选中模块。
-
org.junit.runners.model模块的第一列的三个点,表示依赖数量超过了99,没有展示出来,鼠标指上去后会展示,这里的依赖是327!
很明显,被依赖最多的模块是org.junit.runners.model模块,而看包名,我们也能确定这个包就是「对象模型」!
从这里我们会发现前文确定的核心模块的先后顺序和这里是相反的,实际上我们阅读源码的过程就是在一个粗略的模型上,不断的细化纠正,得到一个详细的完善的模型的过程。
我们双击model包,将会展开此包,我们得到下图:
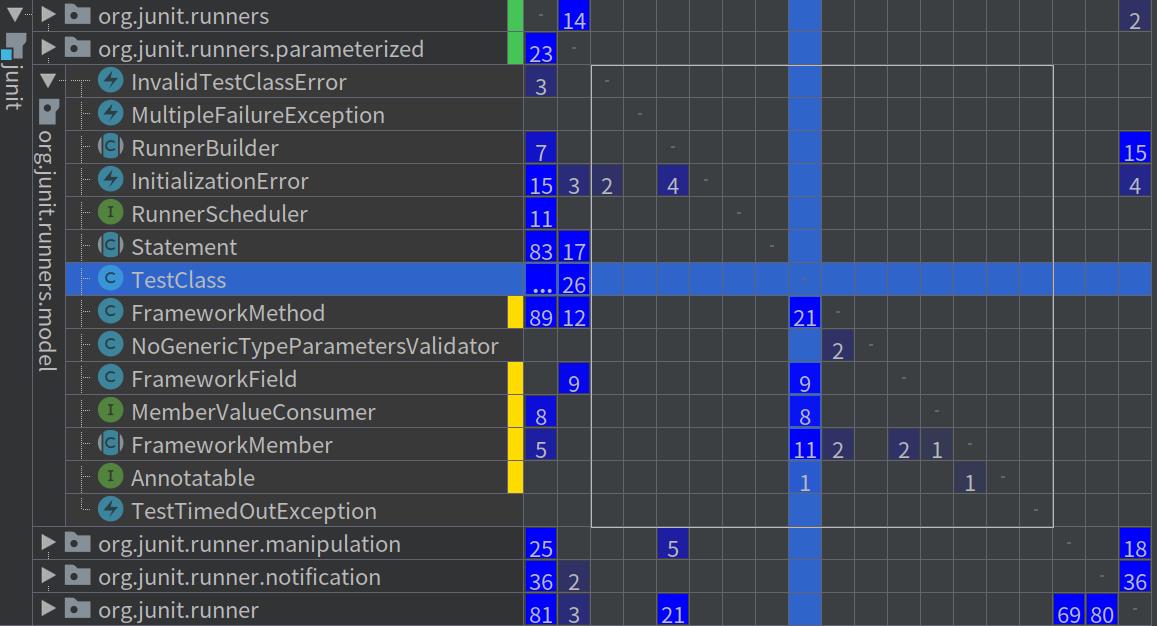
注意右边的矩形,矩形内部的数字表示是模块内的依赖关系。从这张图,我们就能基本确定构成「抽象模型」的核心对象了:
-
被依赖较多的类:TestCase,Statement,RunnerBuilder,RunnerScheduler
-
被TestCase依赖的类:FrameworkMethod,FramewrokField,FrameworkMethod,FrameworkMember,MemberValueConsumer,Annotatable
我们将这些类拖到UML中,就可以得到我们需要的抽象模型了:
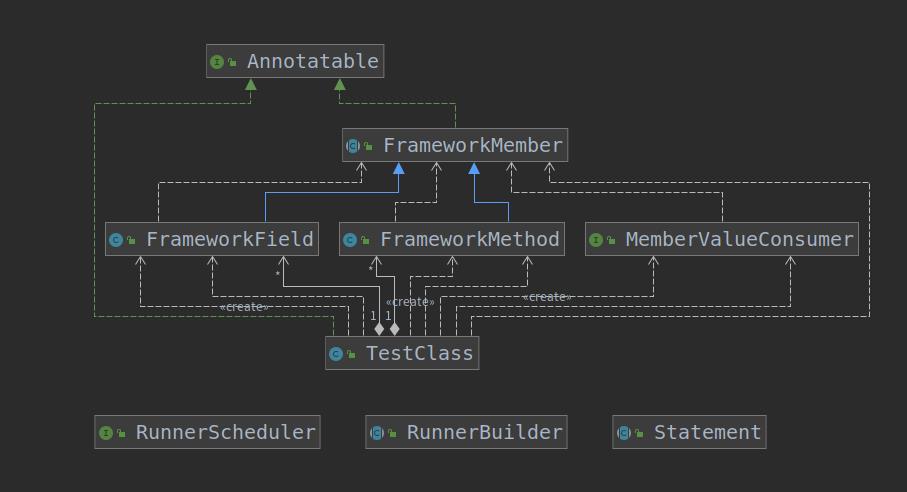
总结
本节讲述了抽象模型的作用及如何确定抽象模型,并通过IDEA的DSM工具演示了具体的确定抽象模型的流程。
下文我们将基于这个模型,来梳理具体的执行流程。
以上是关于高效阅读源码的关键:构建核心抽象模型的主要内容,如果未能解决你的问题,请参考以下文章
如何进行高效的源码阅读:以Spring Cache扩展为例带你搞清楚