Kafka原理介绍
Posted 上善若泪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka原理介绍相关的知识,希望对你有一定的参考价值。
1 Kafka
1.1 定义
Kafka是什么?请简单说一下
Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用Scala 语言编写,目前是Apache 的开源项目。
下面是Kafka中涉及到的相关概念:
broker:Kafka服务器,负责消息存储和转发topic:消息类别,Kafka按照topic来分类消息(即使如此,kafka仍然有点对点和广播发布类型)partition:topic的分区,一个topic可以包含多个partition,topic消息保存在各个partition上offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表该消息的唯一序号Producer:消息生产者Consumer:消息消费者Consumer Group:消费者分组,每个Consumer必须属于一个groupZookeeper:保存着集群broker、topic、partition等meta数据;另外,还负责broker故障发现,partition leader选举,负载均衡等功能
1.2 相关组件介绍
1.2.1 Topic
Topic 是生产者发送消息的目标地址,是消费者的监听目标
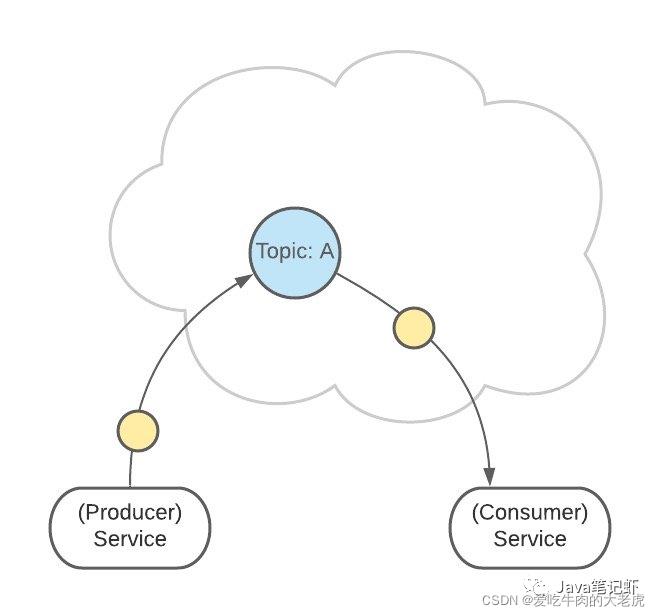
一个服务可以监听、发送多个 Topics
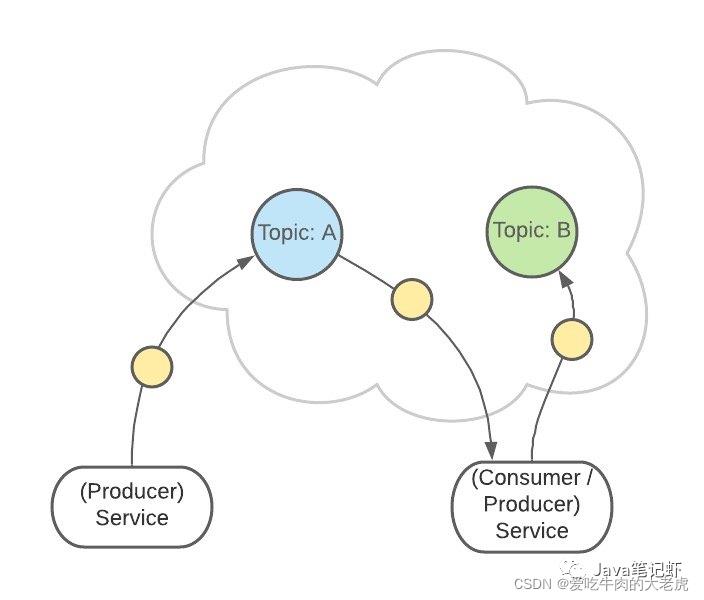
Kafka 中有一个consumer-group(消费者组)的概念。
这是一组服务,扮演一个消费者
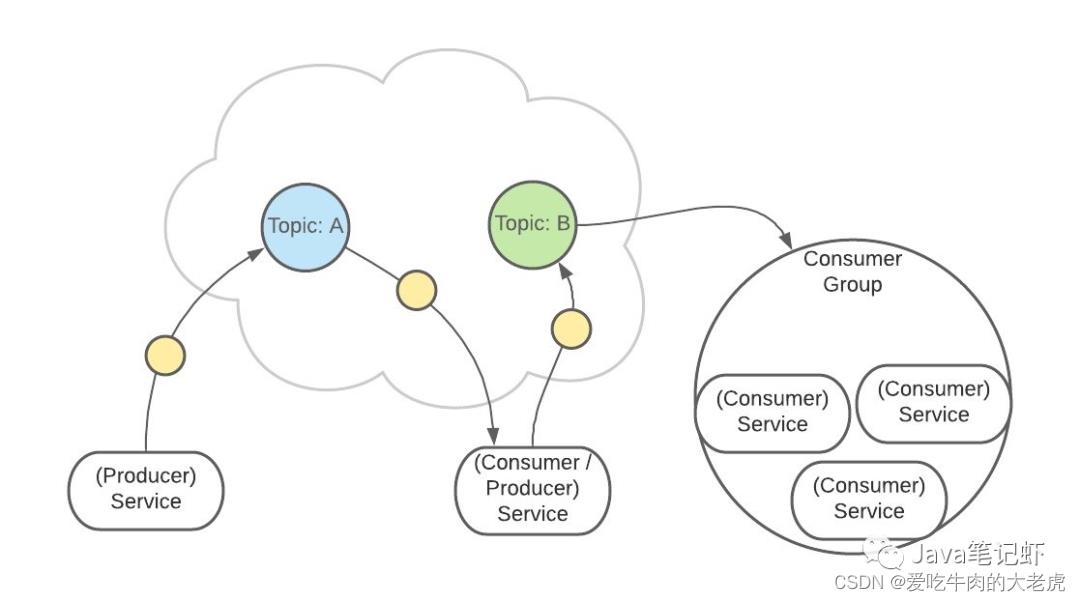
如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务
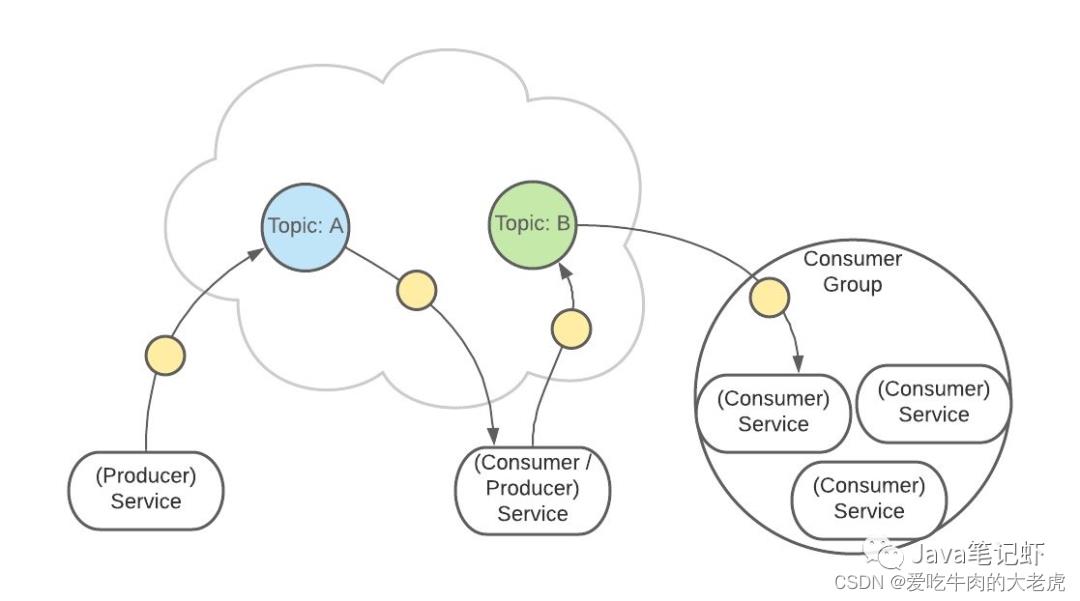
这样有助于消息的负载均衡,也方便扩展消费者。
Topic 扮演一个消息的队列。
首先,一条消息发送了
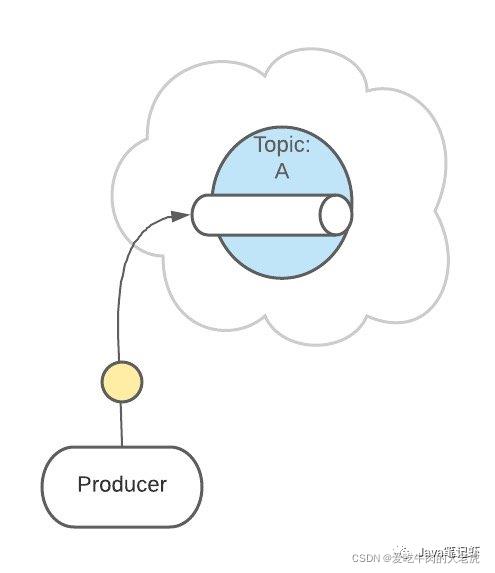
然后,这条消息被记录和存储在这个队列中,不允许被修改
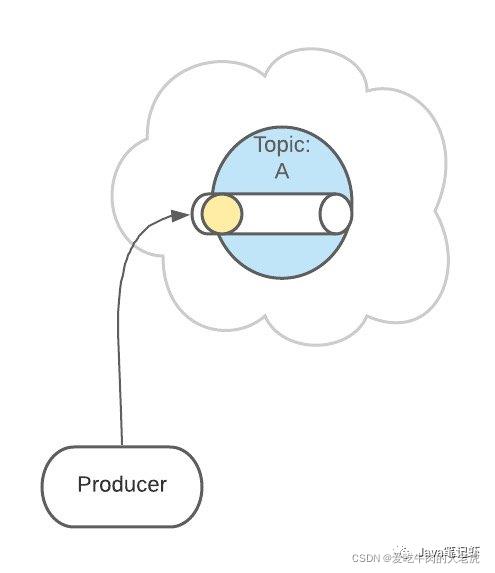
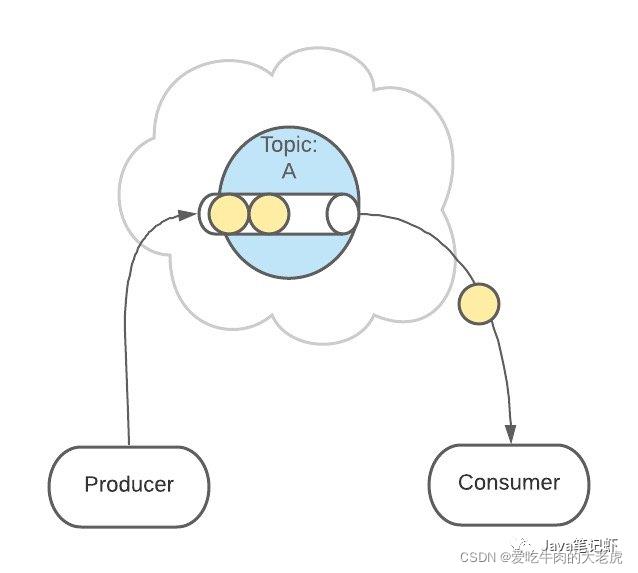
接下来,消息会被发送给此 Topic 的消费者。
但是,这条消息并不会被删除,会继续保留在队列中

像之前一样,这条消息会发送给消费者、不允许被改动、一直呆在队列中。
(消息在队列中能呆多久,可以修改 Kafka 的配置)
1.2.2 Partitions分区
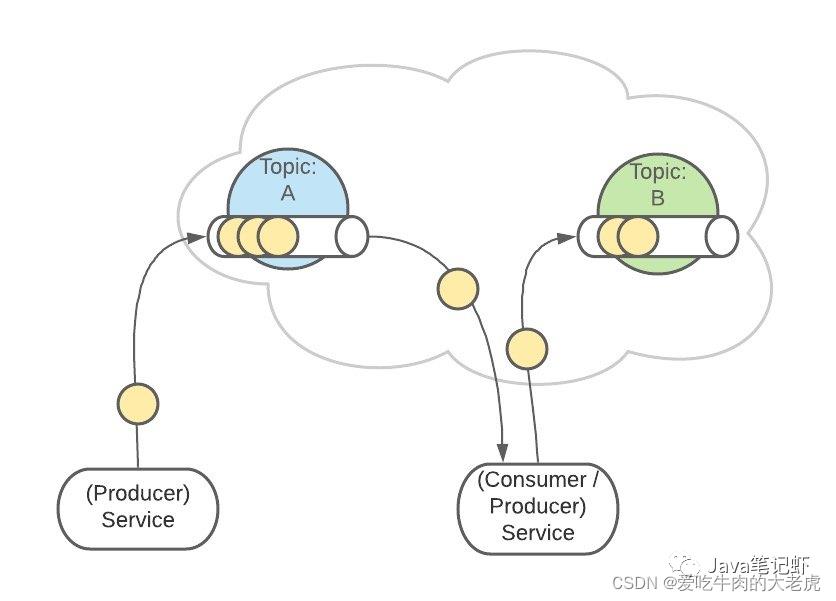
上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为Partition(分区)。
这样可以便于 Topic 的扩展
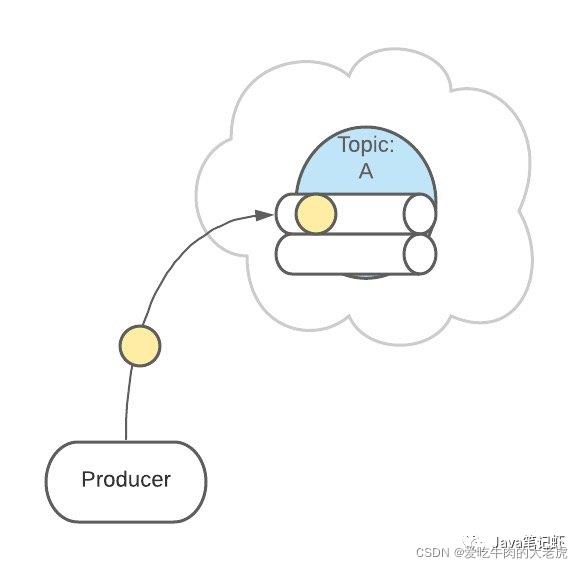
生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition
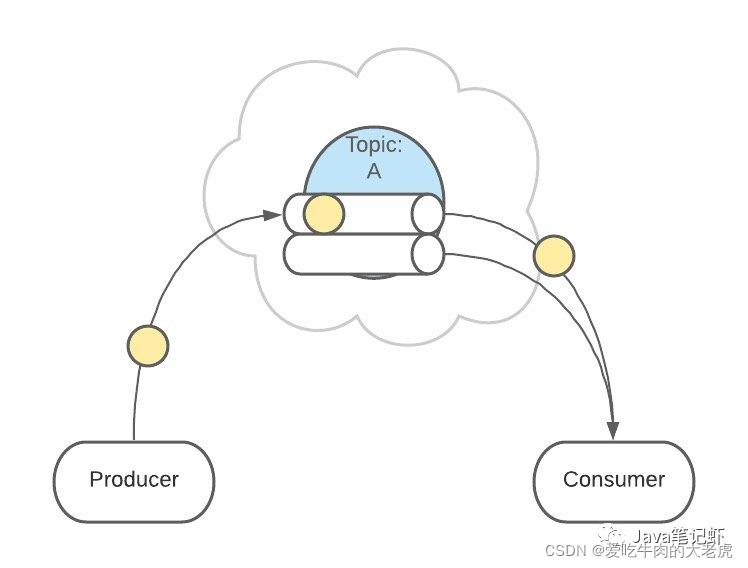
消费者监听的是所有分区
生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略
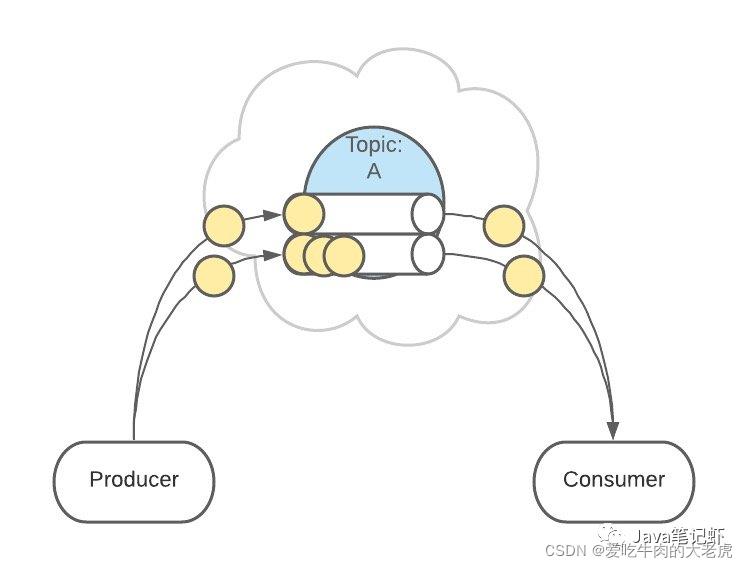
也可以配置 Topic,让同类型的消息都在同一个 Partition。
例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。
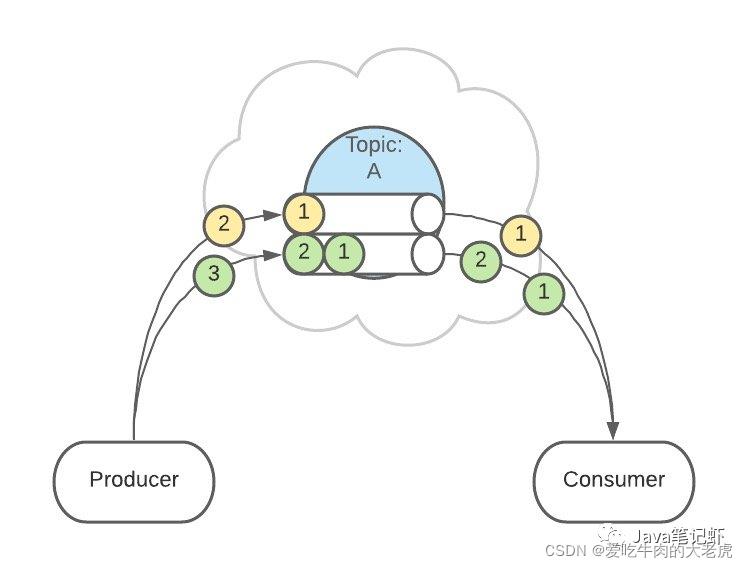
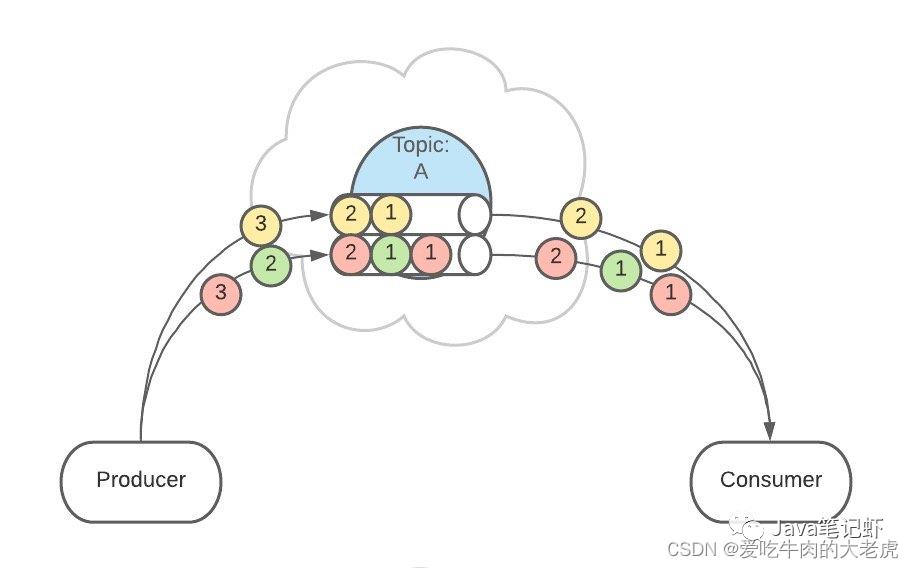
例如,用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。
在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)
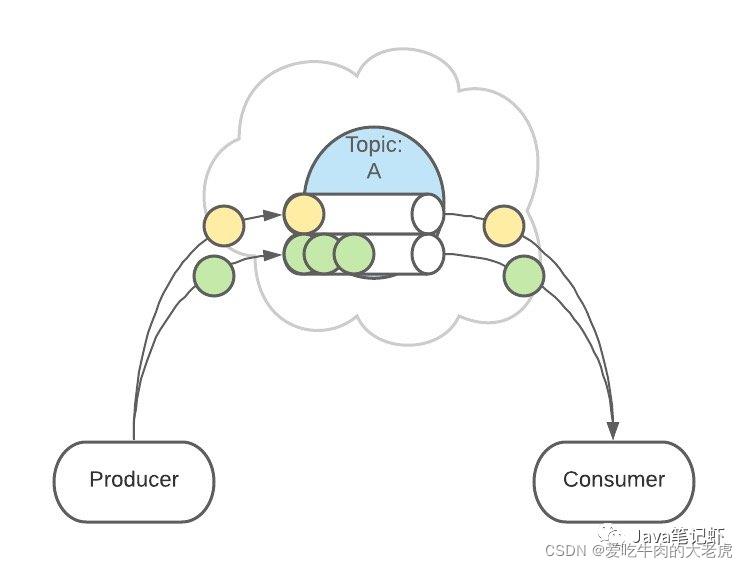
这个功能有什么用呢?
这是为了提供消息的【有序性】。
消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的
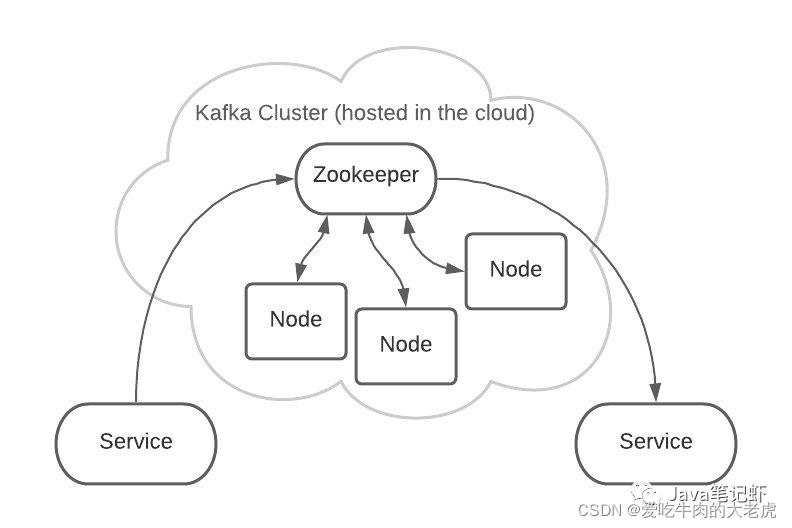
1.2.3 架构和zookeeper关系
Kafka 是集群架构的,ZooKeeper是重要组件。
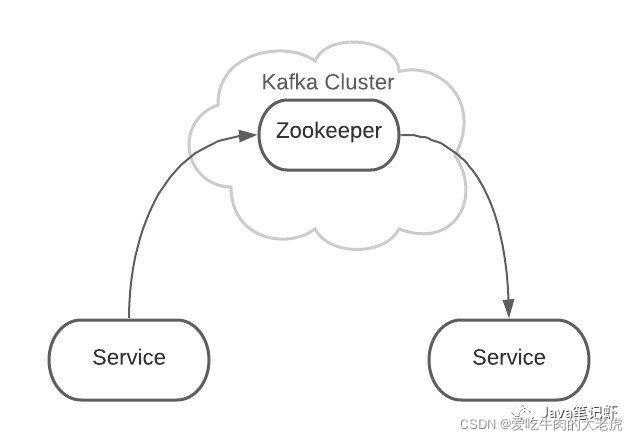
ZooKeeper 管理者所有的 Topic 和 Partition。
Topic 和 Partition 存储在 Node 物理节点中,ZooKeeper负责维护这些 Node
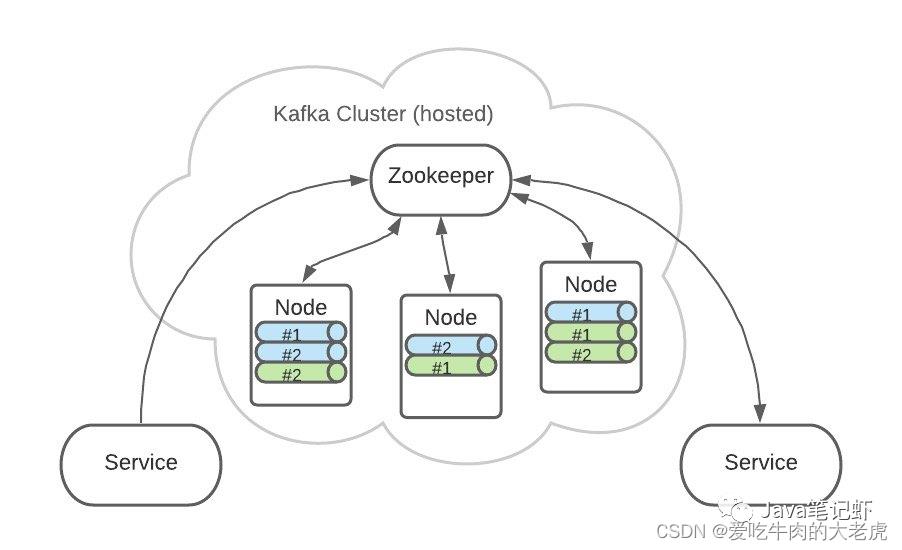
有2个 Topic,各自有2个 Partition
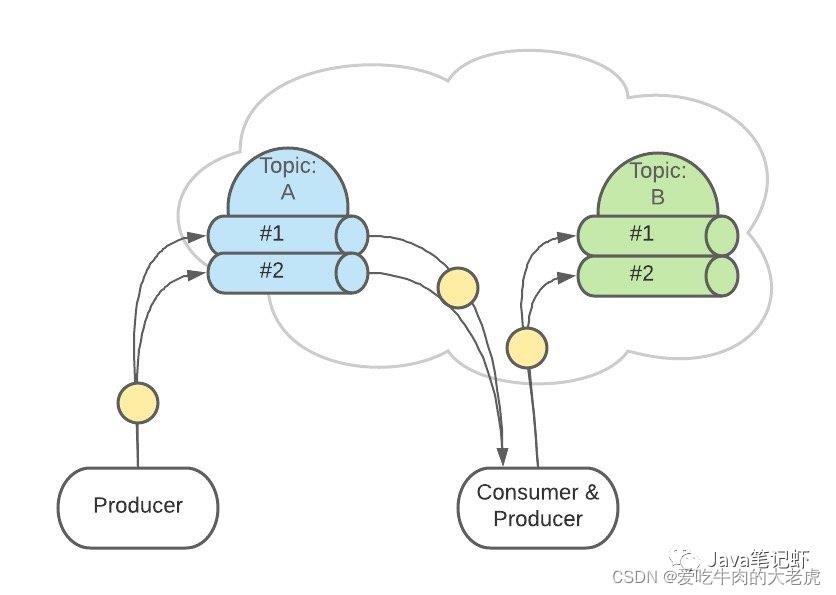
这是逻辑上的形式,但在 Kafka 集群中的实际存储可能是这样的
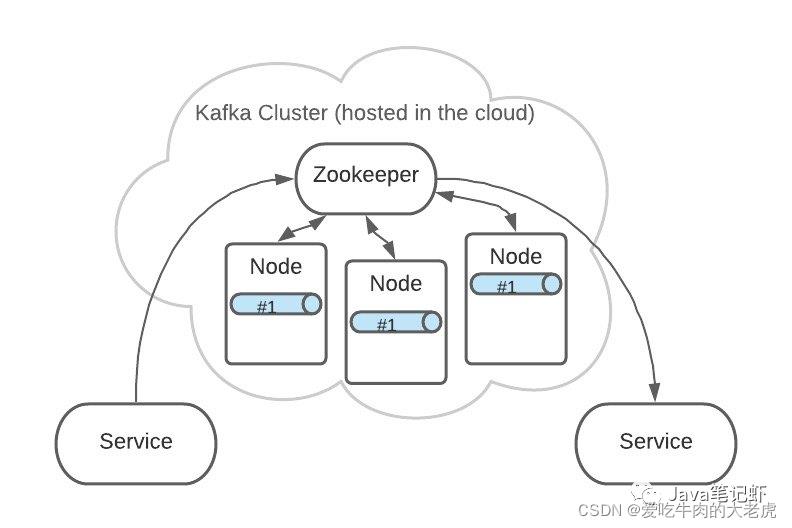
Topic A 的 Partition #1 有3份,分布在各个 Node 上。
这样可以增加 Kafka 的可靠性和系统弹性。
3个 Partition #1 中,ZooKeeper 会指定一个 Leader,负责接收生产者发来的消息
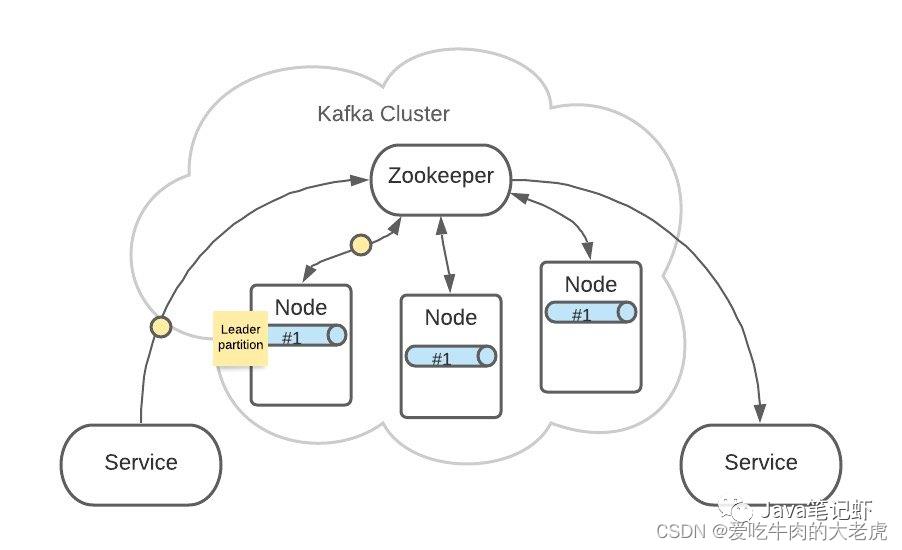
其他2个 Partition #1 会作为 Follower,Leader 接收到的消息会复制给 Follower
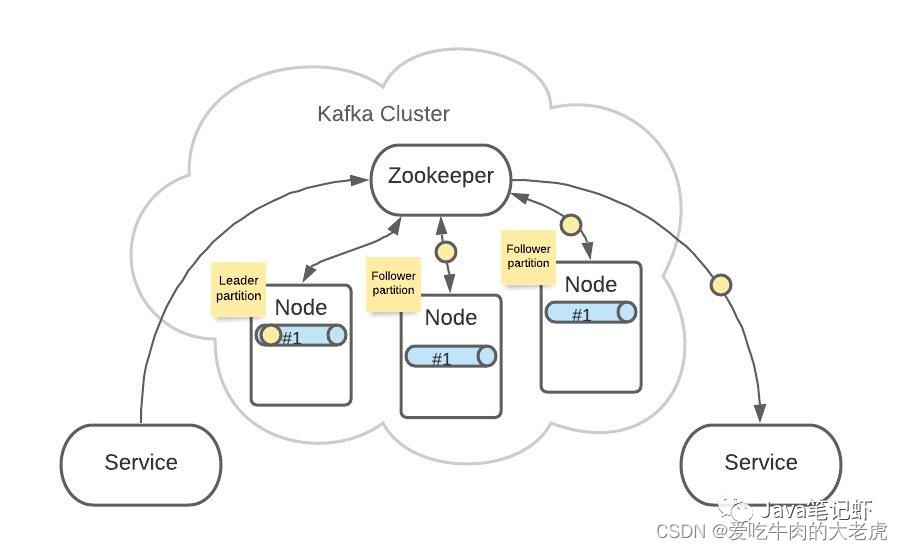
这样,每个 Partition 都含有了全量消息数据。
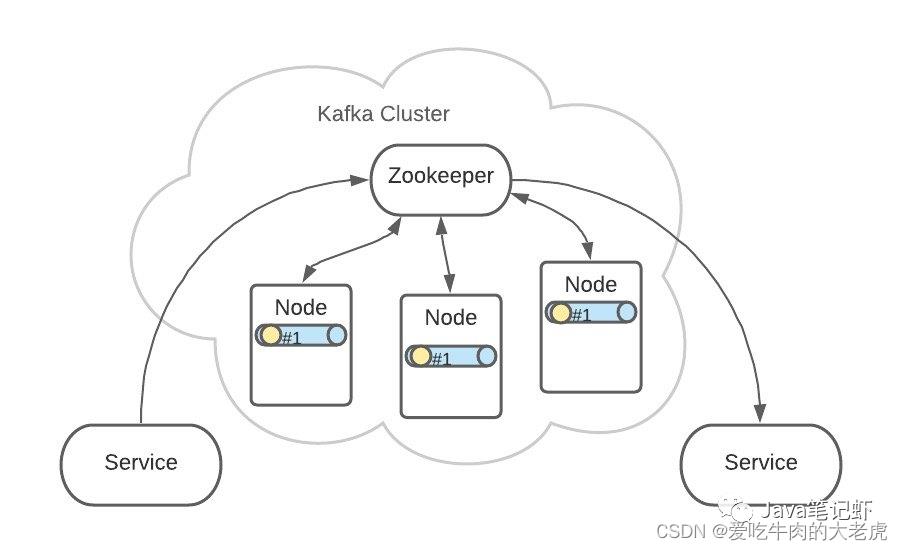
即使某个 Node 节点出现了故障,也不用担心消息的损坏。
Topic A 和 Topic B 的所有 Partition 分布可能就是这样的
转载于:https://mp.weixin.qq.com/s/k7DJJGmImcpnaSy9AhAmmQ
1.3 kafka是如何保证消息的有序性
kafka这样保证消息有序性的:
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。(全局有序性)
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
大家可以看下消息队列的有序性是怎么推导的:
消息的有序性,就是指可以按照消息的发送顺序来消费。有些业务对消息的顺序是有要求的,比如先下单再付款,最后再完成订单,这样等。假设生产者先后产生了两条消息,分别是下单消息(M1),付款消息(M2),M1比M2先产生,如何保证M1比M2先被消费呢。
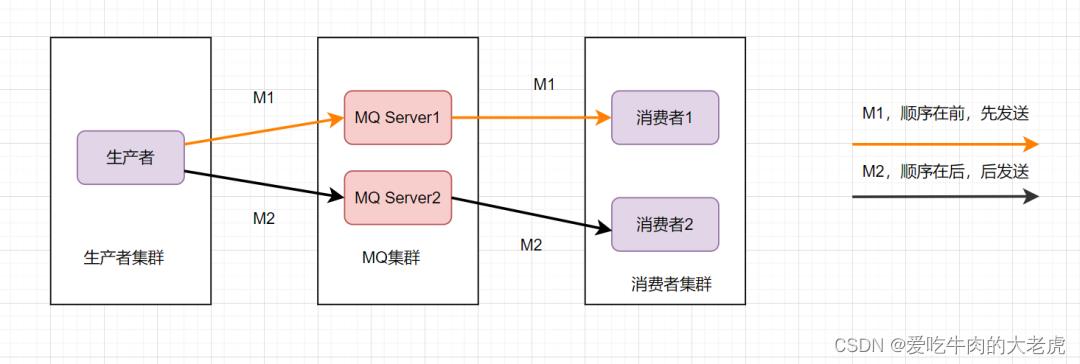
为了保证消息的顺序性,可以将将M1、M2发送到同一个Server上,当M1发送完收到ack后,M2再发送。如图:
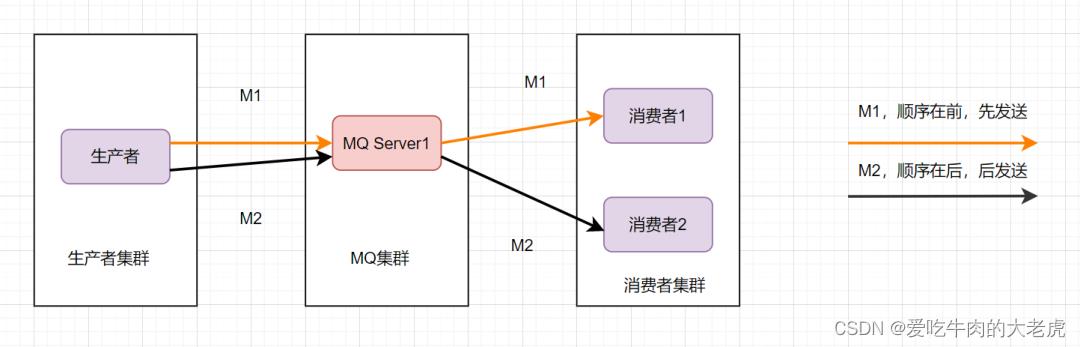
这样还是可能会有问题,因为从MQ服务器到服务端,可能存在网络延迟,虽然M1先发送,但是它比M2晚到。
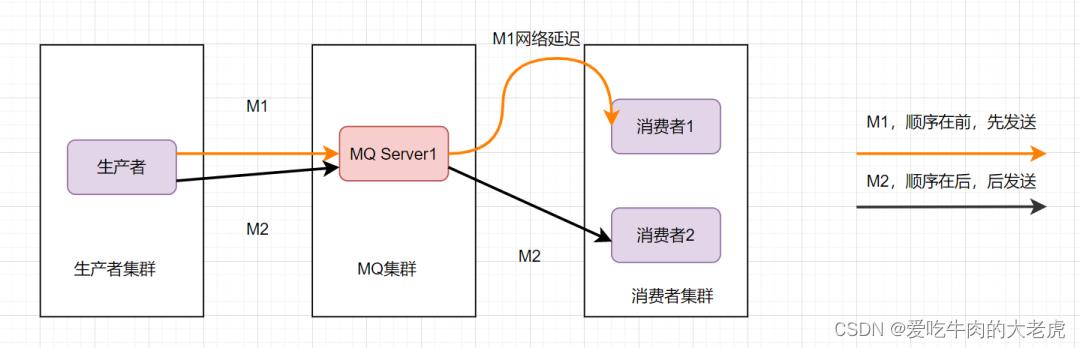
那还能怎么办才能保证消息的顺序性呢?将M1和M2发往同一个消费者,且发送M1后,等到消费端ACK成功后,才发送M2就得了。
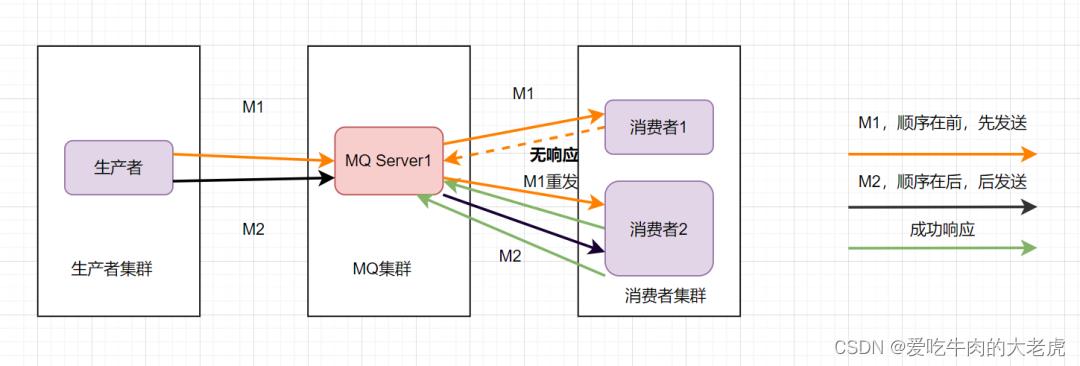
消息队列保证顺序性整体思路就是这样啦。比如Kafka的全局有序消息,就是这种思想的体现: 就是生产者发消息时,1个Topic只能对应1个Partition,一个 Consumer,内部单线程消费。
但是这样吞吐量太低,一般保证消息局部有序即可。在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。然后多消费者单线程消费指定的Partition
转载于:https://mp.weixin.qq.com/s/gHjuYH6R6Fgfn3WZ8W79Zg
以上是关于Kafka原理介绍的主要内容,如果未能解决你的问题,请参考以下文章