python爬虫 模拟登陆校园网-初级
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫 模拟登陆校园网-初级相关的知识,希望对你有一定的参考价值。
最近跟同学学习爬虫的时候看到网上有个帖子,好像是山大校园网不稳定,用py做了个模拟登陆很有趣,于是我走上了一条不归路.....
先上一张校园网截图
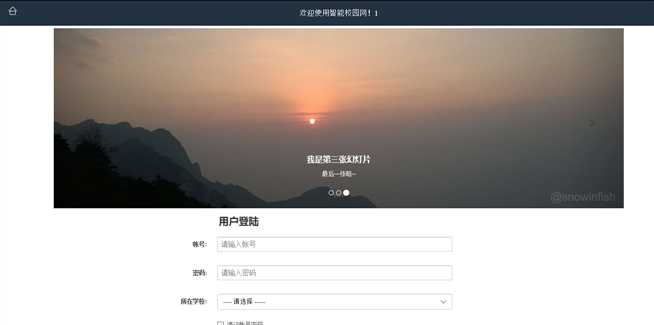
首先弄清一下模拟登陆的原理:
1:服务器判定浏览器登录使用浏览器标识,需要模拟登陆
2: 需要post账号,密码,以及学校id
python走起,我用的2.7版本,用notepad++写的,绑定python可以直接运行
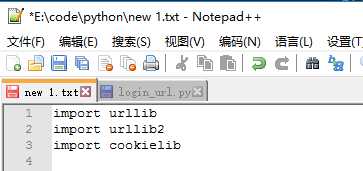
由于是模拟网页登陆,需要导入urllib urllib2 cookielib库,前两个有与网页直接的接口,cookielib就是用来处理cookie的
先了解一下这几个库函数 一片不错的博客
http://www.cnblogs.com/mmix2009/p/3226775.html
ok,开始构建一个opener
cookie=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
用urllib2.HTTOCookieProcessor处理CookieJar获得的cookie,并被build_opener处理
然后构建一下需要post的header,这个地址并不是我们输入账号密码的地址,而是提交数据被处理的地址,在登陆的时候用浏览器抓一下:
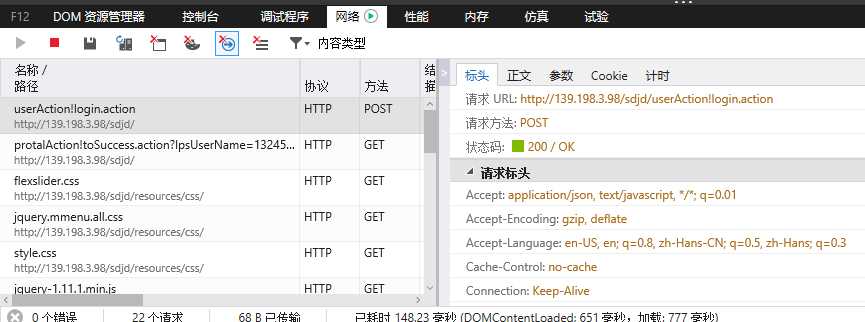
嗯 就是右边的那个URL,我们最后提交的网址就是那个。我们看一下他的header
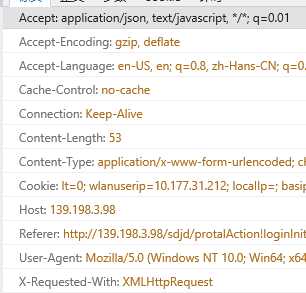
差不多就这些,可以都写上,也可以只写服务器验证的UA等等
需要提交的数据:
data={
"username":"xxxxxxxx",
"password":"xxxxx",
}
post_data=urllib.urlencode(data)
然后就是post了,使用Requset(url,post_data,header)
req=urllib2.Request(‘http://139.198.3.98/sdjd/userAction!login.action‘,post_data,headers) content=opener.open(req)
再open(req)放到content里,print一下试试是否成功。
然后.....然后发现失败了找找bug.....

因为是学习的网上的,那个简单的例子只有用户名和密码,而这个登陆还要选择大学.......
好吧,那就先找下源码,结果没找到,就从header里找,果然在cookie里有个schoo id=XXXX,没错了,就是这个了,于是在data里再加上这个,结果提交了以后还是失败。最后发现提交的data里的userName,password,school_必须和request里的名称大小写下划线什么的要一致:
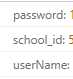
最终代码(账号密码什么的用XXXX代替了):
import urllib
import urllib2
import cookielib
data={
"userName":"xxxxxxxx",
"password":"xxxxx",
"school_id":"xxxx"
}
post_data=urllib.urlencode(data)
cookie=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
headers={
‘Accept‘: ‘text/html, application/xhtml+xml, image/jxr, */*‘,
‘Accept-Encoding‘: ‘gzip, deflate‘,
‘Accept-Language‘: ‘en-US, en; q=0.8, zh-Hans-CN; q=0.5, zh-Hans; q=0.3‘,
‘Connection‘: ‘Keep-Alive‘,
‘Host‘: ‘139.198.3.98‘,
‘Referer‘: ‘http://139.198.3.98/sdjd/protalAction!loginInit.action?wlanuserip=10.177.31.212&basip=124.128.40.39‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393‘,
‘X-Requested-With‘: ‘XMLHttpRequest‘
}
req=urllib2.Request(‘http://139.198.3.98/sdjd/userAction!login.action‘,post_data,headers)
content=opener.open(req)
print content.read().decode("utf-8")
运行一下:
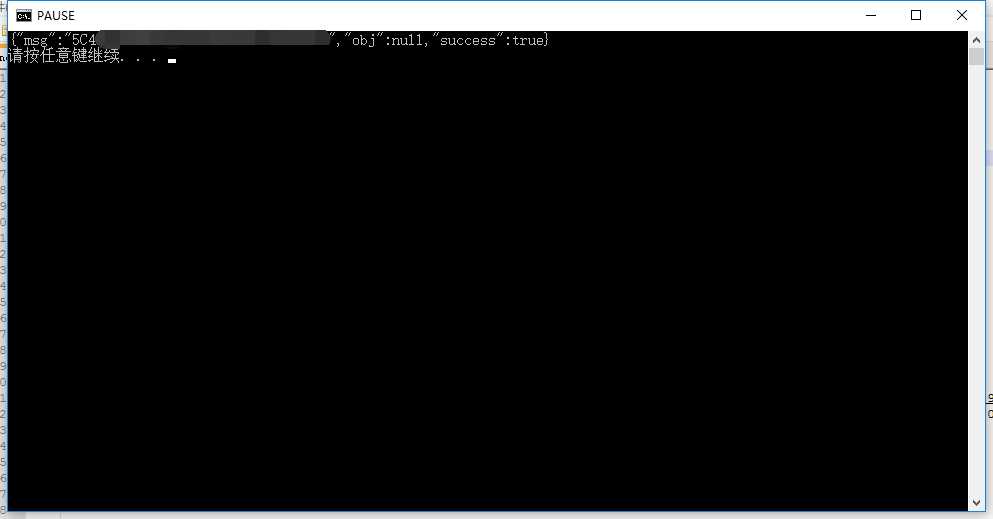
初步success~以后在深一步研究
还有求dalao解答我从notepad++上用#注释没效果咋回事......
以上是关于python爬虫 模拟登陆校园网-初级的主要内容,如果未能解决你的问题,请参考以下文章
利用selenium+chrome模拟登陆合工大信息门户并进行自动填写测评