华为云数据库内核专家为您揭秘MySQL Volcano模型迭代器性能提升千倍的秘密
Posted 华为云官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为云数据库内核专家为您揭秘MySQL Volcano模型迭代器性能提升千倍的秘密相关的知识,希望对你有一定的参考价值。

林舒,20年以上数据库内核研发经验。原IBMDB2数据库内核专家,专长数据库内核性能优化、SQL查询优化、MPP分布式数据仓库技术等。现就职于华为加拿大研究所,全程参与了RDS for MySQL以及GaussDB(for MySQL)的研发工作,熟悉GaussDB(for MySQL) 全栈技术。负责NDP的总体架构设计和实现,并成功落地上线。拥有多项技术发明专利,并co-author了SIGMOD 2020 Taurus( GaussDB(for MySQL)) Paper,目前专注于下一代云数据库智能优化器的研究。
1. 背景介绍
MySQL 8.0.18引入了一个新的SQL执行引擎,它遵循了Volcano模型。该模型的关键思想是将所有操作建模为“迭代器”。迭代器提供基本迭代组件:初始化、迭代和终止。所有迭代器都提供如以上相同的接口,因此迭代器可以任意组合堆叠在一起,形成执行计划。
MySQL 8.0.18还包括一个新的连接方法:哈希连接。哈希连接有探测端和构建端。哈希表是使用构建端的连接列作为哈希键值构建的;然后使用探测端的连接列来查找哈希表中的匹配行。
关于Volcano模型和哈希连接的细节不在本文的范围内。本文重点讨论一个问题,即哈希连接的谓词没有附加到合适的哈希连接迭代器,该问题可能会导致严重的性能下降。请注意:这不是一个功能问题,因为尽管有显著的性能下降,但最终的查询结果是正确的。
华为云数据库内核专家林舒向MySQL官方提交了此错误报告,以及对应的补丁,具体信息请参考这里:https://bugs.mysql.com/?id=104760。在本文中,我们将通过一个示例查询,来说明此问题,并比较应用补丁前后的性能差异。
本文中的查询在MySQL 8.0.26上测试,使用100MB的TPC-H数据库。为了说明问题,在查询语句中使用了索引提示(Index Hint)来促使SQL优化器选择哈希连接。
2. 问题描述
该问题使用的查询及其执行计划如下:
问题查询:
explain format=tree
select avg(case ps_partkey when null then 1 else l_quantity end)
from lineitem left outer join
( partsupp ignore index (primary) join part ignore index (primary) on ps_partkey = p_partkey and p_name like \'%snow%\')
on ps_suppkey = l_suppkey and ps_partkey = l_partkey
执行计划:

-> Aggregate: avg((case partsupp.PS_PARTKEY when NULL then 1 else lineitem.L_QUANTITY end)) (cost=179829230844583.70 rows=899131908749360)
-> Left hash join (part.P_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_SUPPKEY = lineitem.L_SUPPKEY) (cost=89916039969647.67 rows=899131908749360)
-> Table scan on lineitem (cost=61043.00 rows=596410)
-> Hash
-> Filter: (part.P_NAME like \'%snow%\') (cost=2849092735.78 rows=1507573496)
-> Inner hash join (no condition) (cost=2849092735.78 rows=1507573496)
-> Table scan on partsupp (cost=0.23 rows=77726)
-> Hash
-> Table scan on part (cost=0.01 rows=19396)
注意以上查询计划的内哈希连接(Inner hash join)部分,partsupp和part之间的连接是“无条件”的,而谓词(part.P_NAME like“%snow%”)是在内哈希连接完成之后才被应用来过滤结果集的。观察原始查询语句,我们会注意到,partsupp和part之间存在一个连接谓词(ps_partkey = p_partkey),这个谓词去哪里了呢?它隐含在外层的左哈希连接(Left hash join)的连接谓词中,即 (part.P_PARTKEY =lineitem.L_PARTKEY)和(partupp.PS_PartKEY=lineitem.L_PartKEY)这两个谓词描述里。在内哈希连接中缺少谓词会导致性能问题,因为它使得有谓词的连接操作被替换为笛卡尔积,由于缺少连接条件进行过滤,结果集会被放大。此外,本地谓词(part.P_NAME like“%snow%”),可以在内哈希连接之前被应用,提前过滤掉无效的行。
3. 原因分析
这个问题发生的场景是,一个语句使用了外连接,而这个外连接选用哈希连接来完成,并且这个外连接的一部分涉及到了多于一张表。当这些条件同时具备,就可能会引发此问题。
在哈希连接中,其构建端是无法访问探测端上的任何列,反之亦然。一个引用了双端的谓词只能放置在哈希连接迭代器上。当MySQL优化器为表分配谓词时,它假定谓词可以引用表前面出现的所有表,然而这显然不适用于哈希连接。因此,当优化器的计划转换为迭代器计划时,优化器到迭代器的转换代码需要做出额外的补救,现在MySQL的转换代码中缺少相关的处理,导致了本文的问题。
4. 如何修复
针对这个问题的修复主要专注在优化器结构到迭代器转换代码中的主函数:ConnectJoins()。基本的思路是让该函数知道哪些表在当前不是可用的,因为这些表位于哈希连接的另一边。当函数将谓词放置在迭代器上时,尚未应用的谓词将沿着迭代器向上推,并在所需的表可用后立即被应用。
以下是在MySQL 8.0.26之上应用修复后的执行计划。partupp和part之间的内哈希连接现在有一个连接谓词:partupp.PS_PARTKEY=part.P_KEY。另外 ,本地谓词(part.P_NAMElike“%snow%”)现在出现在内部连接下面,也就是先于内哈希连接而被应用。

-> Aggregate: avg((case partsupp.PS_PARTKEY when NULL then 1 else lineitem.L_QUANTITY end)) (cost=179829230844583.70 rows=899131908749360)
-> Left hash join (part.P_PARTKEY = lineitem.L_PARTKEY), (partsupp.PS_SUPPKEY = lineitem.L_SUPPKEY) (cost=89916039969647.67 rows=899131908749360)
-> Table scan on lineitem (cost=61043.00 rows=596410)
-> Hash
-> Inner hash join (partsupp.PS_PARTKEY = part.P_PARTKEY) (cost=2849092735.78 rows=1507573496)
-> Table scan on partsupp (cost=0.23 rows=77726)
-> Hash
-> Filter: (part.P_NAME like \'%snow%\') (cost=0.01 rows=19396)
-> Table scan on part (cost=0.01 rows=19396)
下面是应用补丁前后的查询时间比较:打补丁前,查询耗时需要11分37秒
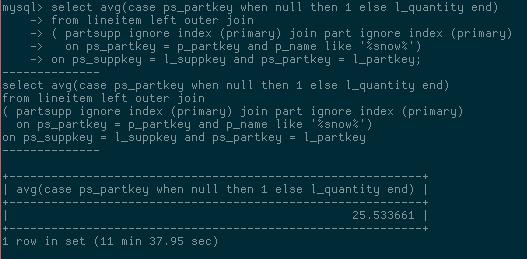
打补丁后,查询耗时仅需0.49秒

11分37秒 vs 0.49秒,修改前后的性能差距有1400多倍,区别是巨大的。希望这个问题可以在下一个MySQL版本中得到解决。
我们知道,MySQL社区的发展离不开每个数据库领域从业人员的努力,华为云GaussDB也一直重视开源社区的发展,积极对社区版本进行优化和改进,为社区做贡献。本次MySQLVolcano模型迭代器的谓词位置优化,助力MySQL查询性能提升千倍,正是华为云GaussDB 对社区发展的积极反馈。
另外,告诉大家一个好消息,华为云数据库专场活动正在进行,云数据库MySQL包年19.9元起,助力企业无忧上云,更多活动详情戳阅读原文。
参考资料:
[1] G. Graefe, "Volcano— An Extensible and Parallel Query Evaluation System," IEEE Transactions on Knowledge and Data Engineering, pp. 120-135, 1994.
[2] "WL#11785: Volcano iterator design," [Online]. Available: https://dev.mysql.com/worklog/task/?id=11785.
[3] "WL#12074: Volcano iterator executor base," [Online]. Available: https://dev.mysql.com/worklog/task/?id=12074.
[4] "WL#12470: Volcano iterator semijoin," [Online]. Available: https://dev.mysql.com/worklog/task/?id=12470.
[5] "Hash Join Optimization," [Online]. Available: https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html.
[6] "WL#2241: Hash join," [Online]. Available: https://dev.mysql.com/worklog/task/?id=2241.
[7] "TPC-H Homepage," [Online]. Available: http://www.tpc.org/tpch/.
本文由华为云发布。
以上是关于华为云数据库内核专家为您揭秘MySQL Volcano模型迭代器性能提升千倍的秘密的主要内容,如果未能解决你的问题,请参考以下文章