ElasticSearch-入门篇
Posted root@su
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch-入门篇相关的知识,希望对你有一定的参考价值。
一、ElasticSearch介绍
1.1 介绍
1、elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
2、elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
突出优点:
-
扩展性好,可部署上百台服务器集群,处理PB级数据。
-
近实时的去索引数据、搜索数据。
es和solr选择哪个?
-
如果你公司现在用的solr可以满足需求就不要换了。
-
如果你公司准备进行全文检索项目的开发,建议优先考虑elasticsearch,因为像Github这样大规模的搜索都在用它。
1.2 倒排索引
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的 去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:

现在,如果我们想搜到quick brown我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 , 那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
1.3 docker 安装ElasticSearch
1.设置max_map_count不能启动es会启动不起来
查看max_map_count的值 默认是65530
cat /proc/sys/vm/max_map_count
重新设置max_map_count的值
sysctl -w vm.max_map_count=262144
2.下载镜像并运行
#拉取镜像
docker pull elasticsearch:7.7.0
#启动镜像
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:7.7.0
--name表示镜像启动后的容器名称
-d: 后台运行容器,并返回容器ID;
-e: 指定容器内的环境变量
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
3.浏览器访问ip:9200 如果出现以下界面就是安装成功

4.安装elasticsearch-head
#拉取镜像
docker pull mobz/elasticsearch-head:5
#创建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#启动容器
docker start elasticsearch-head
or
docker start 容器id (docker ps -a 查看容器id )
5.浏览器打开: http://IP:9100

尝试连接easticsearch会发现无法连接上,由于是前后端分离开发,所以会存在跨域问题,需要在服务端做CORS的配置。
解决办法
6.修改docker中elasticsearch的elasticsearch.yml文件
docker exec -it elasticsearch /bin/bash (进不去使用容器id进入)
vi config/elasticsearch.yml
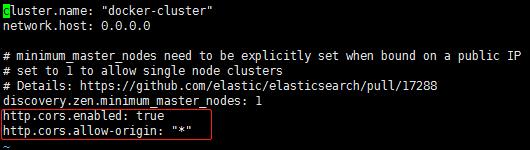
在最下面添加2行
http.cors.enabled: true
http.cors.allow-origin: "*"
退出并重启服务
exit
docker restart 容器id

7.ElasticSearch-head 操作时不修改配置,默认会报 406错误码
#复制vendor.js到外部
docker cp 容器id:/usr/src/app/_site/vendor.js /usr/local/
#修改vendor.js
vim vendor.js

修改完成在复制回容器
docker cp /usr/local/vendor.js 容器id:/usr/src/app/_site
重启elasticsearch-head
docker restart 容器id
最好就可以查询到es数据了

8.安装ik分词器
首先问一个问题,ElasticSearch中自带的有分词器为什么还要使用IK分词器?
在ElasticSearch中的分词器会把中文分为一个一个的字,例如"今天是周五",会被分成“今”、“天”、“是”,“周”、“五”,这里很明显是不合适的,在大多数场景下需要的是词而不是字。
所以就需要安装中文分词器IK来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细力度。分别都有什么区别会在下期文章中给大家提出来。
这里需要注意安装的版本需要跟ElasticSearch版本一致。
进入到ElasticSearch容器中docker exec -it 容器ID /bin/bash
使用wget来进行安装,执行wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip即可。
当你使用wget安装出现Unable to establish SSL connection时执行以下俩个命令即可。
yum install opensslls
yum install openssl-devel
执行cd /usr/share/elasticsearch/plugins来到插件目录创建一个IK目录。
将压缩包移动到IK目录中,执行解压指令elasticsearch-analysis-ik-7.7.0.zip
接着删除压缩包即可,此时你可以看到一个config包和几个jar包
二、基本概念
1.创建索引库 ———————>类似于:数据库的建表
2.创建映射 ———————>类似于:数据库的添加表中字段
3.创建(添加)文档 ———————>类似于:数据库的往表中添加数据。术语称这个过程为:创建索引
5.搜索文档 ———————>类似于:从数据库里查数据
6.文档 ———————>类似于:数据库中的一行记录(数据)
7.Field(域) ———————>类似于:数据库中的字段
2.1 创建索引库
2.1.1 概念:
ES的索引库是一个逻辑概念,它包括了分词列表及文档列表,同一个索引库中存储了相同类型的文档。它就相当于MySQL中的表,或相当于Mongodb中的集合。
索引(index)
# 索引是 ES 对逻辑数据的逻辑存储,所以可以被分为更小的部分
# 可以将索引看成 MySQL 的 Table,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值
# 可以将索引存放在一台机器,或分散在多台机器上
# 每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)
操作:
使用postman这样的工具创建: put http://localhost:9200/索引库名称
# ES 中提供非结构化索引,实际上在底层 ES 会进行结构化操作,对用户透明
PUT http://localhost:9200/索引库名称
"settings":
"index":
"number_of_shards":"1", # 分片数
"number_of_replicas":"0" # 副本数
-
number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同 的结点,提高了ES的处理能力和高可用性,入门程序使用单机环境,这里设置为1。
-
number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为0.
2.2 创建映射
2.2.1 概念
在索引中每个文档都包括了一个或多个field,创建映射就是向索引库中创建field的过程,下边是document和field 与关系数据库的概念的类比:
文档(Document)—– Row记录
字段(Field)—– Columns 列
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。 上边讲的创建索引库相当于关系数据库中的数据库还是表?
1、如果相当于数据库就表示一个索引库可以创建很多不同类型的文档,这在ES中也是允许的。
2、如果相当于表就表示一个索引库只能存储相同类型的文档,ES官方建议在一个索引库中只存储相同类型的文档。
3、所以索引库相当于数句酷的一个表
2.2.2 操作
1、我们要把课程信息存储到ES中,这里我们创建课程信息的映射,先来一个简单的映射,如下:
发送:post http://localhost:9200/索引库名称/类型名称/_mapping
2、创建类型为xc_course的映射,共包括三个字段:name、description、studymondel 由于ES6.0版本还没有将type彻底删除,所以暂时把type起一个没有特殊意义的名字doc。post 请求:http://localhost:9200/xc_course/doc/_mapping
表示:在xc_course索引库下的doc类型下创建映射。doc是类型名,可以自定义,在ES6.0中要弱化类型的概念, 给它起一个没有具体业务意义的名称。
"properties":
"name":
"type": "text"
,
"description":
"type": "text"
,
"studymodel":
"type":"keyword"
2.3创建文档
2.3.1 概念
ES中的文档相当于MySQL数据库表中的记录。
# 存储在 ES 中的主要实体叫文档,可以看成 MySQL 的一条记录
# ES 与 Mongo 的 document 类似,都可以有不同的结构,但 ES 相同字段必须有相同类型
# document 由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)
# 每个字段的类型,可以使文本、数值、日期等。
# 字段类型也可以是复杂类型,一个字段包含其他子文档或者数组
# 在 ES 中,一个索引对象可以存储很多不同用途的 document,例如一个博客App中,可以保存文章和评论
# 每个 document 可以有不同的结构
# 不同的 document 不能为相同的属性设置不同的类型,例 : title 在同一索引中所有 Document 都应该相同数据类型
2.3.2 操作
发送:put 或Post http://localhost:9200/xc_course/doc/id值
(如果不指定id值ES会自动生成ID)
http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
"name":”Bootstrap开发框架",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含 了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现个不受浏览器限制的精美界面 效果。”,
"studymodel": "201001"
2.4 搜索文档
1、根据课程id查询文档
发送:get http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用postman测试:

2、查询所有记录
发送 get http://localhost:9200/xc_course/doc/_search
3、查询名称中包括spring 关键字的的记录
发送:get http://localhost:9200/xc_course/doc/_search?q=name:bootstrap
4、查询学习模式为201001的记录
发送 get http://localhost:9200/xc_course/doc/_search?q=studymodel:201001
查询结果分析:
"took": 1,
"timed_out": false,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
,
"hits":
"total": 1,
"max_score": 0.2876821,
"hits": [
"_index": "xc_course",
"_type": "doc",
"_id": "4028e58161bcf7f40161bcf8b77c0000",
"_score": 0.2876821,
"_source":
"name": "Bootstrap开发框架",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较 为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现 一个不受浏览器限制的精美界面效果。",
"studymodel": "201001"
]
结果说明:
took:本次操作花费的时间,单位为毫秒。timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片hits:搜索命中的记录
hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
三、分词
3.1 内置分词
3.1.1 分词API
分词是将一个文本转换成一系列单词的过程,也叫文本分析,在 ES 中称之为 Analysis
例如 : 我是中国人 -> 我 | 是 | 中国人
# 指定分词器进行分词
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"standard",
"text":"hello world"
# 结果中不仅可以看出分词的结果,还返回了该词在文本中的位置
# 指定索引分词
POST http://[\'自己的ip 加 port\']/beluga/_analyze
"analyzer":"standard",
"field":"hobby",
"text":"听音乐"
Standard
# Standard 标准分词,按单词切分,并且会转换成小写
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"standard",
"text": "A man becomes learned by asking questions."
Simple
# Simple 分词器,按照非单词切分,并且做小写处理
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"simple",
"text":"If the document does\'t already exist"
Whitespace
# Whitespace 是按照空格切分
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"whitespace",
"text":"If the document does\'t already exist"
Stop
# Stop 去除 Stop Word 语气助词,如 the、an 等
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"stop",
"text":"If the document does\'t already exist"
Keyword
# keyword 分词器,意思是传入就是关键词,不做分词处理
POST http://[\'自己的ip 加 port\']/_analyze
"analyzer":"keyword",
"text":"If the document does\'t already exist"
中文分词
# 中文分词的难点在于,汉语中没有明显的词汇分界点
# 常用中文分词器,IK jieba THULAC 等,推荐 IK
# IK Github 站点<自定义词典扩展,禁用词典扩展等>
https://github.com/medcl/elasticsearch-analysis-ik
3.2 IK分词器
安装过程这里不介绍,主要是解决常见中文分词的问题
Github地址:https://github.com/medcl/elasticsearch-analysis-ik
3.2.1 两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、 华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。 测试两种分词模式:
四、映射
上边章节安装了ik分词器,如果在索引和搜索时去使用ik分词器呢?如何指定其它类型的field,比如日期类型、数 值类型等。本章节学习各种映射类型及映射维护方法。
4.1 映射维护方法
1、查询所有索引的映射:
GET: http://localhost:9200/_mapping
2、创建映射
post 请求:http://localhost:9200/xc_course/doc/_mapping
在上面提到过
"properties":
"name":
"type": "text"
,
"description":
"type": "text"
,
"studymodel":
"type":"keyword"
3、更新映射
映射创建成功可以添加新字段,已有字段不允许更新。
4、删除映射
通过删除索引来删除映射。
4.2 常用映射类型
4.2.1 text文本字段
1)text
字符串包括text和keyword两种类型: 通过analyzer属性指定分词器。
下边指定name的字段类型为text,使用ik分词器的ik_max_word分词模式。
"name":
"type": "text",
"analyzer": "ik_max_word"
上边指定了analyzer是指在索引和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过search_analyzer属性。
对于ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。
"name":
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
2) index
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些4.内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置 为false。
删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据
"pic":
"type": "text",
"index": false
3)store
是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在”_source”中,一般情况下不需要设置 store为true,因为在_source中已经有一份原始文档了。
4.2.2 keyword关键字字段
上边介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜 索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常 用于过虑、排序、聚合等。
测试:
更改映射:
"properties":
"studymodel":
"type": "keyword"
,
"name":
"type": "keyword"
添加文档:
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel": "201001"
根据name查询文档。搜索:http://localhost:9200/xc_course/_search?q=name:java name是keyword类型,所以查询方式是精确查询。
4.2.3 日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
1)format
通过format设置日期格式例子:
下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式
"properties":
"timestamp":
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
插入文档:
Post :http://localhost:9200/xc_course/doc/3
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp": "2018‐07‐04 18:28:58"
综合例子
post:http://localhost:9200/xc_course/doc/_mapping
"properties":
"description":
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
,
"name":
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
,
"pic":
"type": "text",
"index": false
,
"price":
"type": "float"
,
"studymodel":
"type": "keyword"
,
"timestamp":
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd||epoch_millis"
以上是关于ElasticSearch-入门篇的主要内容,如果未能解决你的问题,请参考以下文章