论文总结Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation
Posted Salah
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文总结Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation相关的知识,希望对你有一定的参考价值。
论文地址:https://arxiv.org/abs/2108.06536
代码:https://github.com/cvlab-yonsei/JoEm
一、内容
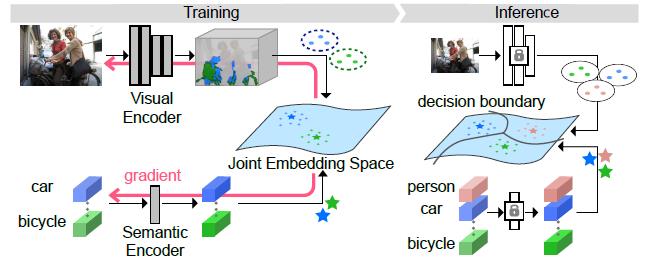
Step 0:将数据集的样本通过 deeplabv3+ 分割模型,将此分割模型作为 Visual Encoder,会输出一个预测结果,通过交叉熵的方式设定预测和对应 Label 的损失。同时保留 deeplabv3+ 倒数第二层的输出,作为特征提取后的特征图。
Step 1:将数据集的 Label 图片的像素和该像素点对应类的语义特征连接起来,形成一个语义空间的特征图,将其输入至一个 Semantic Encoder,保留输出的语义特征图。
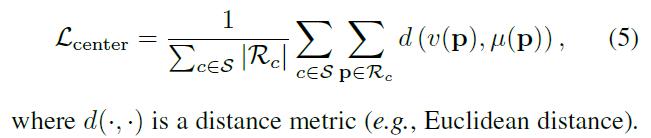
Step 2:通过定义 Center Loss 和 SC Loss,集合 Step 0 中 CE Loss,训练 Visual Encoder 和 Semantic Encoder,CE Loss 帮助 Visual Encoder 准确提取特征,Center Loss 帮助将特征空间和语义空间中的特征映射到一个新的特征空间中。SC Loss 帮助维持新特征空间中语义特征间的距离。
Step 3:训练后的 Encoder 可以将特征空间中的每个特征和语义空间中每个类对应的每个语义特征在一个空间中联系起来,最后,我们使用 Apollonius Circle 结合 NN 分类器,将每个特征点分配给合适的语义特征,这个点便属于了这个语义特征所对应的类。
二、细节
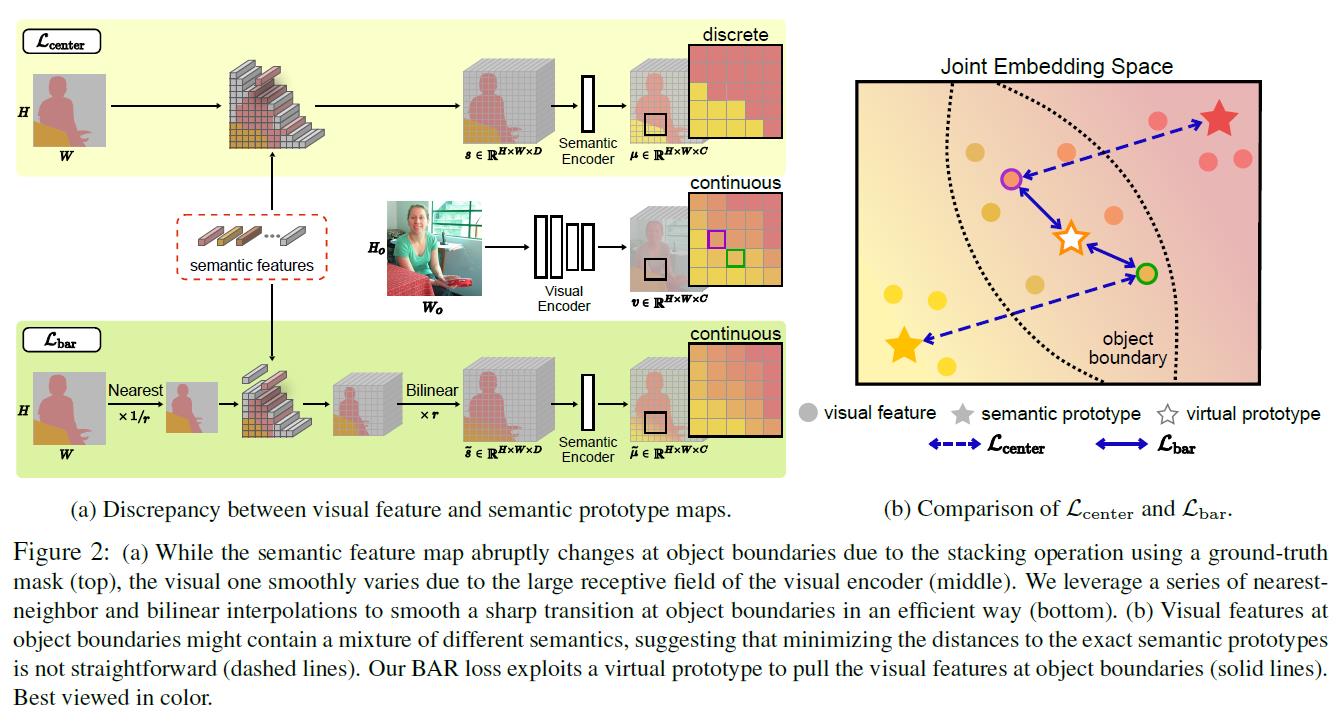
1. 因为 Visual Encoder 的深度使得输出后的特征图的每个特征点有很大的感受野,这意味着每个特征点会包含对应样本图像很多信息,因此如果直接将边界上的特征点分配给一个语义特征时,可能会降低映射模型的表现。因此,如果在目标边界生成了虚拟的语义特征,将有多种类信息的特征点分配给虚拟语义特征,可以使新空间更加兼容特征空间和语义空间。文章中使用先下采样,然后嵌入类的语义信息,再上采样的方法,对边界生成虚拟语义特征。
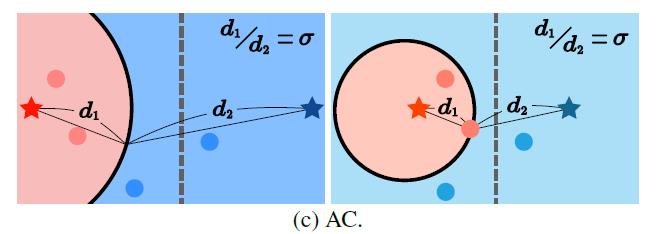
2. 尽管使用了一些方式分辨不同类的视觉特征,但有时不可见类的视觉特征在新的空间的位置还是偏向于一些可见类,尤其是在二者具有相同的视觉表现时。为了解决这个问题,文章使用 Apollonius Circle 对 NN 分类器进行修改,具体来说,如果该像素点被 NN 分类器分给可见类,而第二顺位为不可见类,那么会分别计算该特征在新空间与可见类和不可见类的距离,如果可见类距离和不可见类距离的比值大于一个门槛值,那么依然将此特征分为可见类,如果小于,那么将此特征分为不可见类;如果该像素点直接被 NN 分类器分给不可见类则不做干涉。
三、理解
https://www.cnblogs.com/tangzj/p/15899816.html 中 instance-based methods 类的投影方法。
新颖的地方有两处,一是使用了虚拟语义特征,拉近新特征空间中物体边界的特征点和虚拟语义特征的距离。我理解的这样做的好处在于,因为特征空间中的边界上的特征点有很多语义,直接分配给某一语义特征的话会导致忽略了特征点的其他语义信息,于是将这些含有多语义的边界特征分配的新的虚拟语义特征。那么怎么创造新的虚拟语义特征呢,文章才介绍的下采样再上采样的方式,尤其要注意因果关系和理解顺序。
二是通过 结合 Apollonius Circle 的 NN 分类器 进行分类,此方法比较简单粗暴的,直接强行让拉近了不可见类和周围特征的距离,不可避免地会出现一些错误判断的情况。
以上是关于论文总结Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation的主要内容,如果未能解决你的问题,请参考以下文章