论文总结A Survey of Zero-Shot Learning: Settings, Methods, and Applications
Posted Salah
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文总结A Survey of Zero-Shot Learning: Settings, Methods, and Applications相关的知识,希望对你有一定的参考价值。
论文地址:https://dl.acm.org/doi/abs/10.1145/3293318
一、Learning Settings
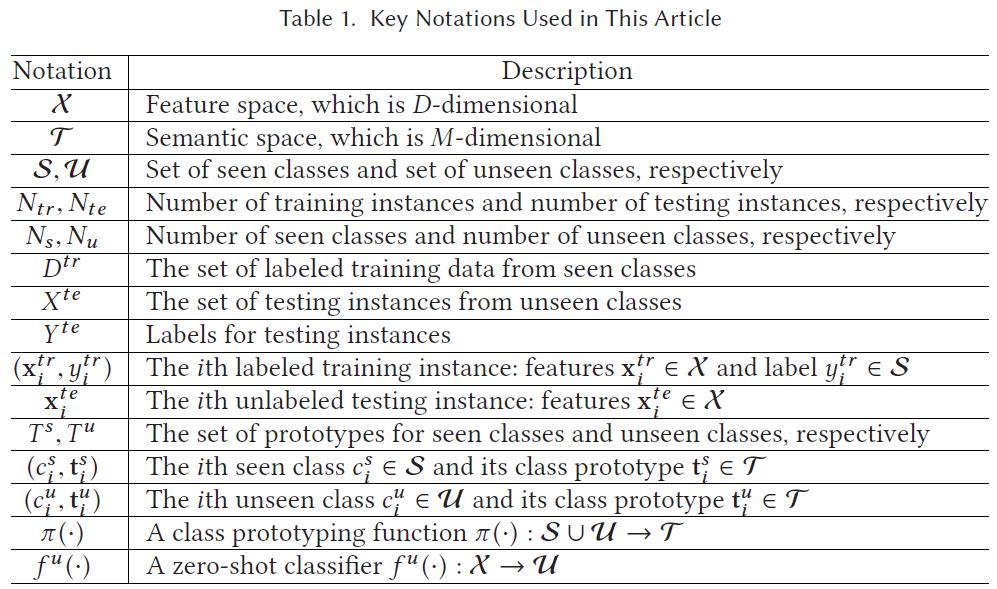
参数
- Class-Inductive Instance-Inductive (CIII) Setting:训练时只使用已标记的可见类的数据集 Dtr 和可见类所对应的语义特征 Ts 集合。
- Class-Transductive Instance-Inductive (CTII) Setting:训练时使用已标记的可见类的数据集 Dtr,可见类所对应的语义特征 Ts 集合和不可见类所对应的语义特征 Tu 集合。
- Class-Transductive Instance-Transductive (CTIT) Setting:训练时使用已标记的可见类的数据集 Dtr,未标记的不可见类的数据集 Xte,可见类所对应的语义特征 Ts 集合和不可见类所对应的语义特征 Tu 集合。
由于训练样本和测试样本包含的类是不相交的,领域漂移现象在 zero shot 中变得更加常见。
- 其中 CIII 的训练因为没有不可见类的信息参与,领域漂移的问题最严重,但是分类新的不可见类的数据时,泛化能力一般优于 CTII 和 CTIT。
- CTII 使用了不可见类的语义特征集合去训练,领域漂移的问题的严重性较轻,但分类新的不可见类的数据的能力受到限制。
- CTIT 使用不可见类的语义特征集合和未标记的数据集去训练,领域漂移的问题的严重性最轻,但分类新的不可见类的数据的能力受到最严重的限制。
二、语义空间
文章把语义空间分两类 Engineered Semantic Spaces 和 Learned Semantic Spaces。Engineered Semantic Spaces 是
1. Engineered Semantic Spaces
Engineered Semantic Spaces 的优势是将人类自身的知识嵌入到语义空间的建设中,但大量依赖人力。
1. Attribute spaces
属性空间由一组属性构成。描述类的性质的词语即为属性,每个属性通常是一些类的性质所对应的词语。比如,动物类的属性可以是身体颜色或者栖息地。属性的值可以是连续的,也可以是二进制的。
2. Lexical spaces
词汇空间是基于类的标签和提供语义信息的数据集,这些数据集一般是结构化的词汇数据库,如 WordNet。可以利用 WordNet 的上下位关系,使用所有类连同他们的祖先类形成一个语义空间,形成的语义空间每一个维度对应着一个类别。
3. Text-keyword spaces
关键词空间由一组关键词组成,关键词是从每个类别对应的文本描述中筛选得到。类对应的文本描述一般通过搜索引擎从网站中获得,可以使用 binary occurrence indicator 或者 Bag of Words 等方式从文本描述中提取关键词,每个关键词即对应着语义空间的一个维度。
4. Some problem-specific spaces
根据要解决的问题的特点形成语义空间。
2. Learned Semantic Spaces
通过学习得到的语义空间中的维度不是由人定义的,每个类的语义特征都是由模型生成的,优势是节省了大量人力,语义特征中的任一个具体维度也没有明确的含义,语义包含于全部维度组合起来的语义特征中,缺点为不利整合现有知识到对应的语义特征中。
1. Label-embedding spaces
标签嵌入空间的语义特征通过类标签的嵌入获得。例如通过 Word2Vec 模型,将类的标签(词)嵌入到一个新的语义空间中,在新的语义空间中,类的标签可以表示成一个向量。原来语义联系紧密的标签,对应的向量在语义空间中的联系也会密切。可以对每个标签只生成一个向量,也可以生成符合高斯分布的多个向量。
2. Text-embedding spaces
类似于标签嵌入空间,文本嵌入空间同样需要一个模型,将类的信息嵌入到新的语义空间中,转化为向量,不同的是将类的一段文本描述输入到模型中。
3. Image-representation spaces
图像表示空间通过某一类别的图片构建语义空间,例如通过 GoogLeNet 模型,将类的图片嵌入到一个新的语义空间中,模型输出的向量即为该类的语义特征。
三、方法
3.1 Classifier-Based Methods
基于分类器方法重点在如何直接对不可见类训练分类器。
3.1.1 correspondence methods
在语义空间中,每一个类由唯一对应的语义特征,因此,这个语义特征可以看作是这个类在语义空间中的表示,而每个类的二分类器同时也是看作这个类在特征空间中的表示。一致性方法利用类的二分分类器和语义特征间的一致性构造不可见类的分类器。
一致性方法的一般流程为:
- 通过可用信息生成一致性模型
- 通过一致性模型和不可见类的语义特征构造二分分类器
- 在构造的二分分类器上测试
最关键的步骤就是如何生成一致性模型,介绍在 CIII Setting 下的一种具体实现:

首先通过可见类的训练集,训练可见类的二分分类器。
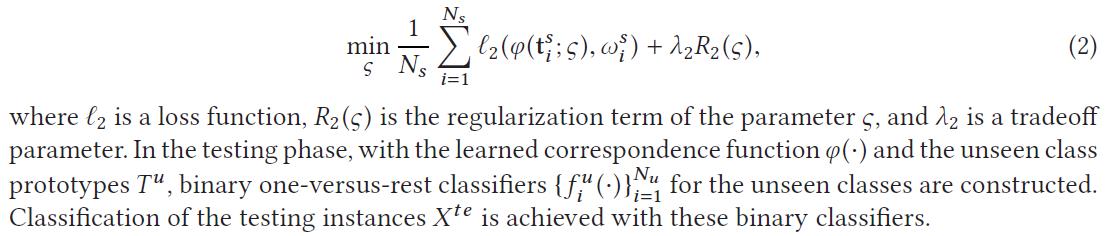
再以可见类在语义空间中的语义特征作为样本,特征空间中的可见类二分分类器参数作为标签,训练一致性模型。
也可以同时将二分分类器和一致性模型结合在一起,直接将可见类数据作为样本,对应类的语义特征作为标签,构建一个从特征空间的原始数据到语义空间的语义特征间的模型。

3.1.2 Relationship Methods
有很多方法可以衡量可见类和不可见类之间的关系(如计算类在语义空间中的语义特征的距离),通过可见类分类器和类间关系构建不可见类的分类器。
关系方法的一般流程为:
- 通过可用信息生成可见类分类器
- 通过计算语义特征或其他方法构建可见类和不可见类之间的关系
- 通过未知类与可见类之间的关系和可见类分类器,构建不可见类的分类器,再进行测试。
主要的步骤是如何计算类间关系,以及如何根据类间关系和可见类分类器构建不可见类分类器,介绍在 CIII Setting 下的一种具体实现。

首先使用可见信息生成可见类的分类器集合。

然后对于每个可见类,根据该类与不可见类的关系程度,通过线性相加的方式将其组合起来构成不可见类的分类器。可以从概率论角度的解释。
对于构建可见类和不可见类之间的关系的方法,一般是将类转化为在语义空间的语义特征,如计算语义特征间的余弦相似度,WordNet中的 ontological structures等。
在 CTII Setting 中,因为训练时使用不可见类所对应的语义特征 Tu 集合,可以使用图去构造不可见类的分类器,如 kNN 图, HEX 图等。
评价!
3.1.3 Combination Methods
之前提到过属性空间、词语空间等语义空间,这些空间有很多维度,每个维度都代表着一个属性或者词语。组合方法同样每个维度视为一个属性,一组属性的组合可以构成一个语义特征,这个语义特征即是一个类在语义空间上的映射。
关系方法的一般流程为:
- 通过可用信息生成属性分类器
- 通过推断模型将属性分类器转化为不可见类分类器
一种在 CIII Setting 下的实现:

3.1.4 我的理解
zero shot 问题中,要实现对不可见类的样本的分类,而我们仅仅在测试阶段才可以得到不可见类样本的标签信息,我们要做的就是将可见类和不可见类的标签联系起来,嵌入到一个新的语义空间中,这个语义空间就是连接不可见类和已知信息的桥梁。

一致性方法重点在类在特征空间和语义空间上的一致性,即可见类的分类器在特征空间存在表示,同时又在语义空间存在表示,一般都涉及到从特征空间到语义空间转化的模型。同时,这种隐式的转化不会明确类间关系。
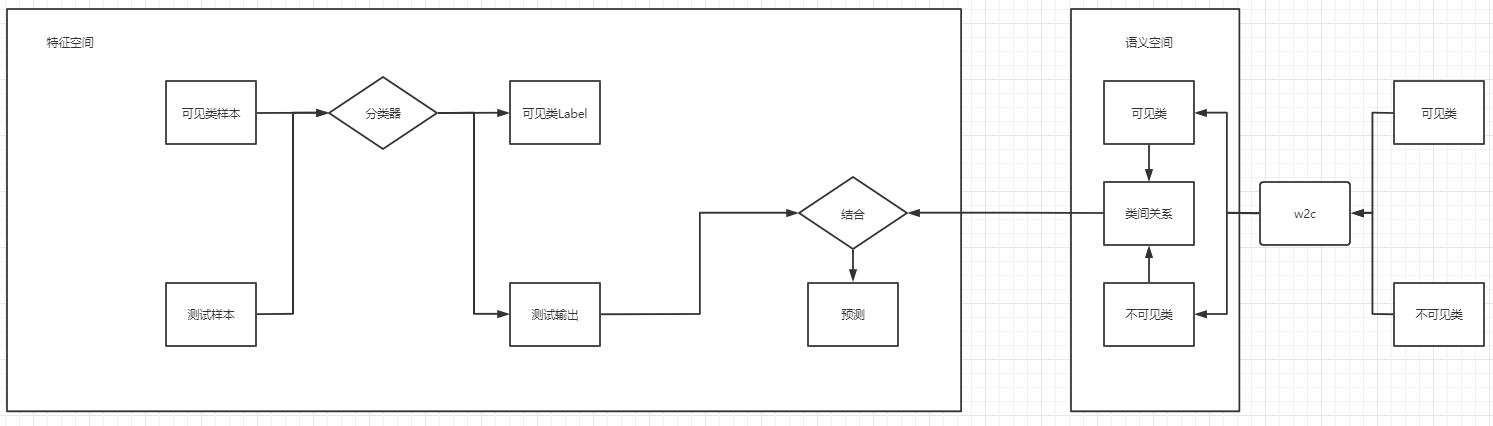
关系方法重点都在语义空间中类的相互关系。在测试阶段,将测试样本输入到逐个可见类分类器中去,将各个分类器得到的输出结合通过不可见类和各个可见类关系,生成预测。最后的分类器实现的是从特征空间到特征空间的映射。
组合方法重点同样的语义空间中类的相互关系,但与关系方法不同的是,组合方法在训练时首先训练可见类的属性分类器,之后使用推断模型利用属性分类器间的关系,生成预测。我的感觉比关系模型更加深入,但语义空间上每个维度需要有较准确的意义。(推断模型不是特别了解)
3.2 instance-based methods
基于样本方法重点在如何获得不可见类的标签,再使用其训练分类器。
3.2.1 Projection Methods
任意一个类在特征空间中都会有对应的样本,样本的标签即为这个类,同样,在语义空间中也会有对应的语义特征,而此语义特征对应的标签也是这个类。根据这个思想,映射方法将特征空间中的样本数据和语义空间中的语义特征都映射到一个相同的空间,在新的空间上,我们就可以得到了由特征空间样本和语义空间的语义特征映射来的类及标签,在测试阶段,输入的不可见类的语义特征即可转化至新空间,然后再对测试数据进行分类,因此新空间的不可见类只有一个测试时输入的一个,所以一般使用 1NN 方法进行分类。

映射方法的一般流程为:
- 将特征空间的样本和语义空间中的语义特征都映射到一个空间
- 在新的映射空间进行分类
在 CIII Setting 下,映射到的目标空间很多样,可以是语义空间,可以是特征空间,可以是其他普通空间,甚至可以是多于一个空间,当映射空间是语义空间时:

但是在 CIII 设定并且使用语义空间作为映射空间的情况下,容易出现枢纽点问题。
当映射空间是特征空间时:

在 CTIT Setting 下,可以使用测试集的样本,因此我们可以将直推式学习嵌入到映射或分类中。
- 映射阶段:Manifold regularization 流形正则化,Matrix factorization 矩阵分解
- 分类阶段:Self-training 自训练,Label propagation 标签传播,Structured prediction 结构化预测
3.2.2 Instance-Borrowing Methods
如果我们想训练一个卡车分类器但却没有卡车的图像,那么我们可以借用汽车和公共汽车的图像,因为这两类车和卡车相似,将这两类的数据作为正例训练分类器即可得到卡车的分类器。实例借用方法就是基于类之间的相似性,在相似类知识的帮助下,可以实现识别不可见类的实例。
实例借用方法的一般流程为:
- 对每个不可见类,将类的标签分配给一些可见类的图片
- 使用新标记的图片训练分类器
重要的步骤就是借用与不可见类相似的类,因此在训练前要先确定不可见类,因此此方法不能在 CIII Setting 下使用,下面介绍 CTII setting 下:

对于相似类的筛选,我们不同的处理方式:
- 选择所有的可见类作为相似类。
- 通过可见类的和不可见类语义空间的相似度排序,选择高相似度的可见类作为相似类。
对于新标记的类,我们不同的处理方式:
- 对于新标记的类的所有数据,采取相同的处理方式。
- 对于新标记的类的数据,计算数据符合不可见类的分数,将分数低的去掉。
3.2.3 Synthesizing Methods
合成方法的基本思想是通过合成一些伪实例的形式为不可见类生成标记实例。
合成方法的一般流程为:
- 对每个不可见类,合成一些伪实例。
- 使用合成的伪实例训练分类器。
和实例借用方法类似,合成方法同样在训练前要先确定不可见类,因此此方法不能在 CIII Setting 下使用,下面介绍 CTII setting 下:

合成方法的重点自然是如何合成伪实例,下面介绍两种方式:
- 可以计算可见类的实例的高斯分布,再通过语义特征计算可见类和不可见类数据的关系,从而得出不可见类的实例分布参数的估计,通过其生成不可见类的实例。
- 也可以通过训练一些生成模型,如 GAN、GMMN 等,通过类的语义特征生成一些伪实例。
3.2.4 我的理解
映射方法将特征空间和语义空间整合起来,使每个不可见类的语义特征在新的映射空间中也被视为一个带标签的实例。映射的方式很灵活,映射的目标空间同样灵活。但每个不可见类只有一个带标签的实例,限制了分类方法。
实例借用方法的实例直接来自于可见类的实例,而可见类和不可见类一定有或多或少的区别,那么训练出来的分类器一定不如真实不可见类数据训练出的准确性高。但是可以从多个可见类中只借用最为相似的数据,以最大优化其训练的准确性。
合成方法的实例主要是根据数据集中其他可见类的实例分布,结合语义空间中的类间关系得到的。生成的伪实例一定遵循着某种分布,容易造成伪实例的偏差。
实例借用和合成方法的实例来源都是本身数据集的可见类,但借用是直接根据类间关系把实例抢过来,而合成方法考虑了其他类的实例分布来生成实例。
以上是关于论文总结A Survey of Zero-Shot Learning: Settings, Methods, and Applications的主要内容,如果未能解决你的问题,请参考以下文章