《深入理解计算机系统》CSAPP_MallocLab
Posted duile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《深入理解计算机系统》CSAPP_MallocLab相关的知识,希望对你有一定的参考价值。
MallocLab
开始日期:22.2.8
操作系统:linux
调试工具:gdb
Link:CS:APP3e
Pre-knowledge
-
完全阅读CSAPP9.9章节,该章节有Implicit list + First fit + LIFO的全实现
-
本文主要参考2015 fall的ppt及rec,2022 spring今年开始更新,大家也以去看
-
任务要求是实现,
mm_free,mm_malloc,mm_realloc,期间还需要编写辅助函数(helper function) -
本文主要参考blog:[读书笔记]CSAPP:MallocLab,CSAPP:Lab5-Malloc Lab,针对-coalesce-trace-文件优化定制,CS:APP3e 深入理解计算机系统_3e MallocLab实验
-
traces文件是缺失的,请自取link: traces
- 第一次学git往github送文件,折腾了好一会儿
-
主要知识
-
块结构(注意
bp指向payload,而p是指向Header)|Header|payload|padding|Footer| ^p ^bp教材:
P 592:malloc返回一个指针,它指向有效载荷的开始处
p 599:块指针bp指向第一个有效载荷字节 -
内存模型(注意
head_listp指向Prologue Footer)|Padding|Prologue Head|Prologue Foot|Normal Block|...|Epilogue Head| ^head_listp -
链表结构(Keeping Track of Free Blocks)
- Implicit list(隐式链)
- Root -> block1 -> block2 -> block3 -> ...
- Explicit list(显示链)
- Root -> free block 1 -> free block 2 -> free block 3 -> ...
- Segregated lists(离散链表)
- Small-malloc root -> free small block 1 -> free small block 2 -> ...
- Medium-malloc root -> free medium block 1 -> ...
- Large-malloc root -> free block block 1 -> ...
- Implicit list(隐式链)
-
合并策略(Coalescing policy)
分为立即合并(Immediate coalescing)和延迟合并(Deferred coalescing)两种,本文只采用立即合并。
延迟合并可以参考[读书笔记]CSAPP:MallocLab -
插入策略(Insert policy)
当有一块新的空闲块该如何插入当前列表?-
LIFO,后进先出,直接插入开头处
-
Address order(配合Segregated list)按照地址顺序插入,而地址顺序靠size classes(大小类)决定
Insert freed blocks so that free list blocks are always in address order:
addr(prev) < addr(curr) < addr(next)
-
-
放置(搜索)策略(Placement policy)
- First fit(配合LIFO)
每次都从头找 - Next fit(配合LIFO)
第一次从头开始找,找到之后马上标记;第二次起,每次都从上一次的标记找,每次找到也要标记
换句话说,第二次是从第一次标记的地方开始找,第三次是从第二次标记的地方开始找,以此类推
需要注意的是,如果从标记到内存结尾这一遍没找到,要从内存开始到标记找一遍,如果还是没找到就算作找不到。 - Best fit(配合Address order)
按照size classes从小到大找,每次都能找到最适合的
- First fit(配合LIFO)
-
Content
Implicit list + First fit + LIFO
- 保持耐心,参照教材敲一遍代码,能够很好的理解
- 也可以用Code Examples中的mm.c
- 笔者结合了两者,其实没啥修改,链接:Implicit list + First fit + LIFO
- 本文没有编写检查函数
mm_realloc,教材并没有提及,而且write up没有写得很清楚,它的主要功能是给一个已分配的块重新划分大小,我是看菜鸟教程- 跑分
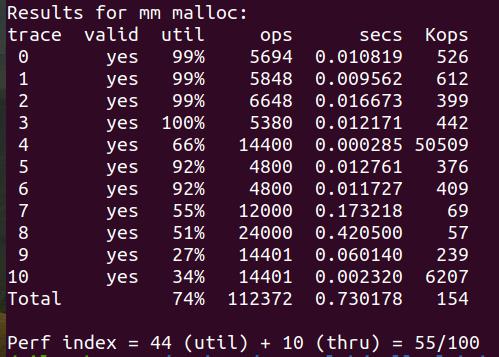
Implicit list + Next fit + LIFO
-
添加了全局变量
rover,相比上一个需要更改三处,链接:Implicit list + Next fit + LIFOstatic char *rover; /* Next fit rover */ -
mm_init,添加初始化rover语句,将其指向heap_listp/* Initialize rover */ rover = heap_listp; -
find_fit,使用Next fitstatic void *find_fit(size_t asize) /* Next fit search */ char *oldrover = rover; /* Search from the rover to the end of list */ for ( ; GET_SIZE(HDRP(rover)) > 0; rover = NEXT_BLKP(rover)) if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover)))) return rover; /* Divide and Conquer */ /* search from start of list to old rover */ for (rover = heap_listp; rover < oldrover; rover = NEXT_BLKP(rover)) if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover)))) return rover; return NULL; /* no fit found */ -
coalesce,防止rover指向已经被合并的bp/* if the rover is pointing into the free block that we just coalesced */ /* we change it pointing to newest free block */ if ((rover > (char *)bp) && (rover < NEXT_BLKP(bp))) rover = bp;- 灵魂图示

- 灵魂图示
-
跑分
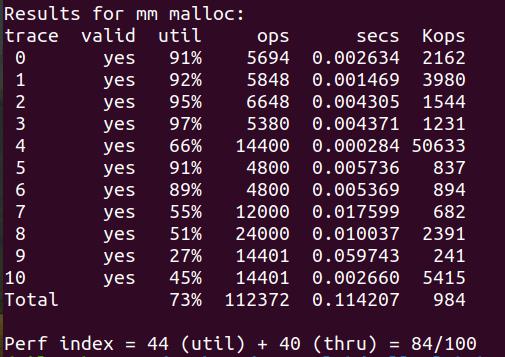
Explicit list + First fit + LIFO
-
使用了Explicit list,需要修改不少地方,链接:Explicit list + First fit + LIFO
-
添加全局变量
static char* efree_listp = 0; /* Pointer to first free block */ -
mm_init,添加初始化efree_listp语句,它是空指针,在合并的时候要注意/* Initialize efree_listp */ efree_listp = NULL; -
添加四个Marco,分别用于计算某一个空闲块前后继的地址,修改某一个空闲块前后继的指向地址
/* Given block ptr bp, compute value of its succ and pred */ #define GET_SUCC(bp) (*(unsigned int *)(bp)) #define GET_PRED(bp) (*((unsigned int *)(bp) + 1)) /* Put a value at address of succ and pred */ #define PUT_SUCC(bp, val) (GET_SUCC(bp) = (unsigned int)(val)) #define PUT_PRED(bp, val) (GET_PRED(bp) = (unsigned int)(val))此时空闲块的结构如下:
|Header|succ|pred|padding|Footer| ^p ^bp -
mm_free,添加清空前后继的语句void mm_free(void *ptr) size_t size = GET_SIZE(HDRP(ptr)); PUT(HDRP(ptr), PACK(size, 0)); PUT(FTRP(ptr), PACK(size, 0)); PUT_PRED(ptr, NULL); PUT_SUCC(ptr, NULL); coalesce(ptr); -
辅助函数
remove_s_p,辅助place和coalesce
它分为四种情况,通过修改前后继,将空闲块从空闲链中移除,放置或者合并都要使用到static void remove_s_p(void *bp) void* pred = GET_PRED(bp); void* succ = GET_SUCC(bp); PUT_PRED(bp, NULL); PUT_SUCC(bp, NULL); if (pred == NULL && succ == NULL) /* NULL-> bp ->NULL */ efree_listp = NULL; else if (pred == NULL) /* NULL-> bp ->FREE_BLK */ PUT_PRED(succ, NULL); /* as the first block */ efree_listp = succ; else if (succ == NULL) /* FREE_BLK-> bp ->NULL */ PUT_SUCC(pred, NULL); else /* FREE_BLK-> bp ->FREE_BLK */ PUT_SUCC(pred, succ); PUT_PRED(succ, pred); -
辅助函数
insert,使用LIFO策略,将空闲块插入空闲链的最开始处,辅助coalesce- 如果efree_listp是空的,说明是第一次插入
- 如果不空,将空闲块插入空闲链的最开始处
static void insert(void *new_first) /* First insert */ if (efree_listp == NULL) efree_listp = new_first; return; /* efree_list -> insert -> succ */ void* old_first = efree_listp; PUT_SUCC(new_first, old_first); PUT_PRED(new_first, NULL); PUT_PRED(old_first, new_first); efree_listp = new_first; -
place,注意remove_s_p的调用,当一个空闲块被分配了,必须移除它static void place(void *bp, size_t asize) size_t bsize = GET_SIZE(HDRP(bp)); /* when a free bloc be allocted, we must remove it */ remove_s_p(bp); if ((bsize - asize) >= (2*DSIZE)) PUT(HDRP(bp), PACK(asize, 1)); PUT(FTRP(bp), PACK(asize, 1)); /* bp: Remainder of block */ bp = NEXT_BLKP(bp); PUT(HDRP(bp), PACK(bsize-asize, 0)); PUT(FTRP(bp), PACK(bsize-asize, 0)); PUT_SUCC(bp, NULL); PUT_PRED(bp, NULL); coalesce(bp); else PUT(HDRP(bp), PACK(bsize, 1)); PUT(FTRP(bp), PACK(bsize, 1)); -
coalesce- 要区别
remove_s_p的4个情况 和coalesce的case 1 ~ 4 情况
前者是把block从explicit free list中移除,这个block要么是将要被分配的block,要么将要被合并(coalesce)的free block,这4个情况指的是block的succ,pred的有无;
后者是把邻近的free block合并,case 1 ~ 4 情况指的是block邻近free block的有无 - 结束时,记得插入到空闲链当中
static void *coalesce(void *bp) size_t prev_alloc = GET_ALLOC(HDRP(PREV_BLKP(bp))); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); if (prev_alloc && next_alloc) /* alloc-> bp ->alloc */ /* then we will insert(bp) */ else if (prev_alloc && !next_alloc) /* alloc-> bp ->free */ remove_s_p(NEXT_BLKP(bp)); size += GET_SIZE(HDRP(NEXT_BLKP(bp))); PUT(HDRP(bp), PACK(size, 0)); PUT(FTRP(bp), PACK(size,0)); else if (!prev_alloc && next_alloc) /* free-> bp ->alloc */ remove_s_p(PREV_BLKP(bp)); size += GET_SIZE(HDRP(PREV_BLKP(bp))); PUT(FTRP(bp), PACK(size, 0)); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp); /* prev block as first free block */ else /* free-> bp ->free */ remove_s_p(NEXT_BLKP(bp)); remove_s_p(PREV_BLKP(bp)); size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); bp = PREV_BLKP(bp); insert(bp); return bp; - 要区别
-
extend_heap,添加前后继的初始化语句/* Initialize explicit free list ptr: efree_listp, succ and pred */ PUT_SUCC(bp, 0); /* Free block succ */ PUT_PRED(bp, 0); /* Free block pred */ -
跑分
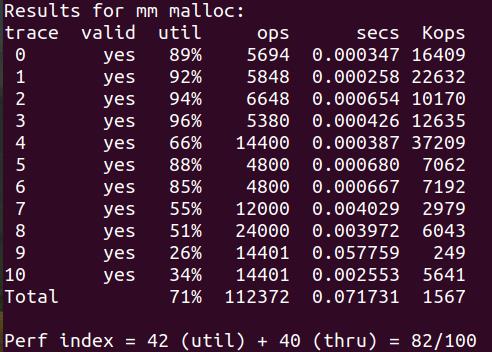
Segregated list + Best fit + Address order
-
实现Segregated list有两种方式,一种是开辟新的内存块来存放不同大小类的头指针,另一种是用指针链表
笔者采用的是前者,链接Segregated list + Best fit + Address order
后者可以看CS:APP3e 深入理解计算机系统_3e MallocLab实验 -
Segregated list采用了九种大小类(size classes),注意因为
8字节对齐和头脚的填充,最小块是16字节 -
block_list_start,添加全局变量,用来指向不同大小类的头指针static char* block_list_start = 0; /* Pointer to first free block of different size */ -
mm_init,初始化时,开辟新的内存块来存放不同大小类的头指针(九种)
block_list_start一开始指向最小类,注意heap_listp的指向也要随之改变int mm_init(void) if ((heap_listp = mem_sbrk(12*WSIZE)) == (void*)-1) return -1; PUT(heap_listp, 0); /* block size <= 32 */ PUT(heap_listp+(1*WSIZE), 0); /* block size <= 64 */ PUT(heap_listp+(2*WSIZE), 0); /* block size <= 128 */ PUT(heap_listp+(3*WSIZE), 0); /* block size <= 256 */ PUT(heap_listp+(4*WSIZE), 0); /* block size <= 512 */ PUT(heap_listp+(5*WSIZE), 0); /* block size <= 1024 */ PUT(heap_listp+(6*WSIZE), 0); /* block size <= 2048 */ PUT(heap_listp+(7*WSIZE), 0); /* block size <= 4096 */ PUT(heap_listp+(8*WSIZE), 0); /* block size > 4096 */ PUT(heap_listp+(9*WSIZE), PACK(DSIZE, 1)); /* Prologue header */ PUT(heap_listp+(10*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */ PUT(heap_listp+(11*WSIZE), PACK(0, 1)); /* Epilogue header */ block_list_start = heap_listp; /* pointer to block size <= 32 */ heap_listp += (10 * WSIZE); /* pointer to Prologue footer */ if (extend_heap(2 * DSIZE/WSIZE) == NULL) return -1; return 0; -
remove_s_p,由于指针头不再是一个单独的全局指针,而是一个内存块,所以remove_s_p需要做出相应的调整,主要是要清空bp的前后继,以及root要指向原先的后继(succ),而不是NULLstatic void remove_s_p(void *bp) void *root = get_sfreeh(GET_SIZE(HDRP(bp))); void* pred = GET_PRED(bp); void* succ = GET_SUCC(bp); PUT_PRED(bp, NULL); PUT_SUCC(bp, NULL); if (pred == NULL) /* NULL-> bp ->NULL */ PUT_SUCC(root, succ); /* NULL-> bp ->FREE_BLK */ if (succ != NULL) PUT_PRED(succ, NULL); else /* FREE_BLK-> bp ->NULL */ PUT_SUCC(pred, succ); /* FREE_BLK-> bp ->FREE_BLK */ if (succ != NULL) PUT_PRED(succ, pred); -
insert,这最主要的修改,因为使用了Address order,需要按照不同大小类插入,而且插入时也要按照从小到大的顺序插入(这时也要分为4种情况)static void insert(void* bp) if (bp == NULL) return; void* root = get_sfreeh(GET_SIZE(HDRP(bp))); void* pred = root; void* succ = GET(root); /* size form small to big to aviod always use big free block */ while (succ != NULL) if (GET_SIZE(HDRP(succ)) >= GET_SIZE(HDRP(bp))) break; pred = succ; succ = GET_SUCC(succ); /* Luckly! the first succ block bigger than bp block */ /* So bp is root and pred of bp is NULL*/ if (pred == root) /* 1. root -> insert, First insert*/ PUT(root, bp); PUT_PRED(bp, NULL); PUT_SUCC(bp, succ); /* 2. root -> insert -> xxx, First insert and then having free block*/ /* if succ != NULL, bp is pred of succ */ if (succ != NULL) PUT_PRED(succ, bp); /* Unluckly! the first succ block smaller than bp block */ /* So bp is NOT root and pred of bp EXISTS*/ else /* 3. root -> xxx -> insert, Last insert*/ PUT_PRED(bp, pred); PUT_SUCC(bp, succ); PUT_SUCC(pred, bp); /* 4. xxx-> insert -> xxx , Middle insert*/ /* if succ != NULL, bp is pred of succ*/ if (succ != NULL) PUT_PRED(succ, bp); -
get_slisth,找到不同大小类的内存块void* get_sfreeh(size_t size) int i = 0; /* i > 4096 */ if(size >= 4096) return block_list_start + (8 * WSIZE); /* i <= 32 */ size = size >> 5; /* other */ while (size) size = size >> 1; i++; return block_list_start + (i * WSIZE); -
find_fit,由于采用了Address order,从头开始找就算best fit了,注意如果当前类找不着,应当去下一个类看看能不能找到。static void* find_fit(size_t asize) for (void* root = get_sfreeh(asize); root != (heap_listp-WSIZE); root += WSIZE) void* bp = GET(root); while (bp) if (GET_SIZE(HDRP(bp)) >= asize) return bp; bp = GET_SUCC(bp); return NULL; -
跑分
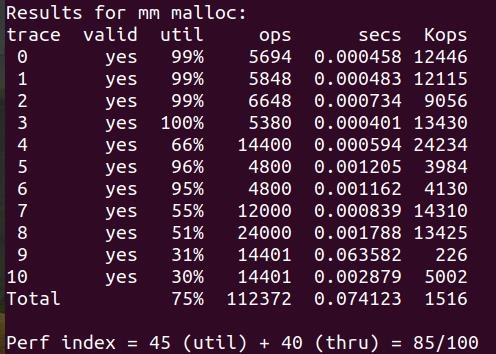
Optimization
-
...is to you know first do fairly simple things and then look and see where the slowdowns and inefficiencies are and the just sort of hit those one after the other and optimize only for the things that are necessary.
Optimization: space VS time
- 优化从最简陋的做起,教授这段话很有见地
-
针对
coalesce trace文件4优化定制,参考针对-coalesce-trace-文件优化定制-
因为文件4的请求经过对齐总是大于
4096bytes,所以第一次的extend_heap扩展堆(4096bytes)总是用不了,导致内存利用率总是66% -
因此第一次的扩展堆我们只申请最小块(
16bytes),爱用不用= . =,影响很小,更改extend_heap/* First Extend: Only require the 16 bytes */ if (extend_heap(2 * DSIZE/WSIZE) == NULL)
-
-
跑分,链接:Optimization

-
笔者没有对remalloc进行优化,想看如何减少internal fragment,参考CS:APP3e 深入理解计算机系统_3e MallocLab实验
Conclusion
Questions in lab
-
由于之前完全没了解过linux操作系统,做到这个lab才知道
Makefile是干什么用的,在此简单记录下:-
指令
make用以编译文件,形成可执行文件,指令make clean清空之前的可执行文件文件
先输入make clean清空,再输入make编译可以解决以下问题:/usr/bin/ld: i386:x86-64 architecture of input file `mdriver.o\' is incompatible with i386 output /usr/bin/ld: i386:x86-64 architecture of input file `mm.o\' is incompatible with i386 output -
更改
Makefile的中参数可以改变编译方式:-
一如,要用到
gdb调试,则对编译命令加入-g字段(而后使用指令gdb mdriver即可调试)CFLAGS = -Wall -02 -m32 -g -
一如,删除
-02优化字段,防止调试时出现跳跃,而不是线性(一行行)执行CFLAGS = -Wall -m32 -g
-
-
-
./mdriver -v报错Testing mm malloc Reading tracefile: amptjp-bal.rep Could not open ... /amptjp-bal.rep in read_trace: No such file or directory-
在
config.h中更改TRACEDIR为本地自己的traces文件夹路径,重新make即可#define TRACEDIR "/home/ubuntu/.../malloclab-handout/traces/"
-
-
don\'t worried about
warning: )- 实验给出的
mdriver.c编译时会出现warning但不会影响评分 - 笔者编写的函数有些类型转换存在问题,没有彻底解决
- 实验给出的
-
简要复习下曾忘掉的
gdb调试命令break pointerstep (go into function) (come back byfinish)next (not go into function)infobreak pointer or othercontinue (jump this time)watch`parameter``- ``d`elete
btbuffer expresslayout srcrespectively express source code and debug cmdrun run at break pointerquitkill- type
Enterfrom keyboard to repeat last operation
-
主要遇到的bug
- segment fault(core Dump)
段错误(核心转移),主要是访问了已经使用的地址,或者非法访问(eg. 访问只读内容) - Ran out of memory
超出内存范围 - paylod overlap
重复分配已经分配的块 - not align to
8byte
没有向8字节对齐 - 一直在运行,但是跑不出结果 = =
- segment fault(core Dump)
-
误解bug,改错函数
-
不同blog的思路虽然相同,但实现差别蛮大,不容易移植
Thinks
-
完成日期:22.2.12
-
这个实验凭我个人能力,中短时间内很难做出来,主要是bug很多,而且样例不好调试,个人的debug能力没有刻意练习过,gdb之前也没好好练习上手,用的半生不熟,bug难解决,所以借鉴了许多blog的代码实现。
-
还有的是,思路即使相同,但是实现时没能想到更多的情形,被ppt的图示框住了:刚写
remove_s_p的时候,我一开始默认是前后块都存在(实际是四种情形),而且也没考虑到一个空闲块被分配后也应当remove -
期间看代码看到怀疑人生,整个人很自闭,太快地敲代码,没有细细想
-
以后要先细想清楚再实现,否则拿着错误的想法,debug到猴年马月,还挫伤自信心
-
我的代码之路离一万小时还很远,要保持耐心,加油!
-
一万小时理论来自于《异类》这本书,以及《奇特的一生》这两本书改变了我原先的学习心态,我有感觉,它们会对我今后的学习有更大影响,推荐给你,我的读者。
以上是关于《深入理解计算机系统》CSAPP_MallocLab的主要内容,如果未能解决你的问题,请参考以下文章