SNA社交网络算法
Posted 琴月阳89
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SNA社交网络算法相关的知识,希望对你有一定的参考价值。
社交网络需要用到igraph库,所以需要安装。可以在lfd的网站
http://www.lfd.uci.edu/~gohlke/pythonlibs/ 上下载python_igraph,具体的python对应版本和是32位还是64位的,比如我下载了 python_igraph‑0.7.1.post6‑cp35‑none‑win_amd64.whl
利用pip 安装whl文件:pip install文件名.whl
为了避免出错,打开cmd以后,要cd进入你存放的该whl文件的解压后的目录下在用pip进行安装。
一、社交网络算法介绍
应用场景:在社交网络中社区圈子的识别;基于好友关系为用户推荐商品或内容;社交网络中人物影响力计算;信息在社交网络上的传播模型;虚假信息和机器人账号的识别;互联网金融行业中的反欺诈。
什么是图:
节点代表人,边代表人与人之间的关系。
无向图(人人网)和有向图(twitter或豆瓣这种单向关注的属于有向图)。
二分图(两类不同的节点,u和v里面的节点没有连接)和多图(两个节点之间有多条边)
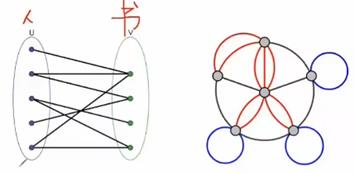
社交网络算法——分析指标:
一个具体的网络可以抽象为由一个节点集合V和边集合E组成的图G=(V,E),节点数记为n=|V|,边数记为m=|E|。衡量指标(社交网络的分析性指标)包括
①度(结点直接关联的属性)
通俗点理解就是人有多少个朋友。无向图的话只有度,有向图的话有入度和出度。
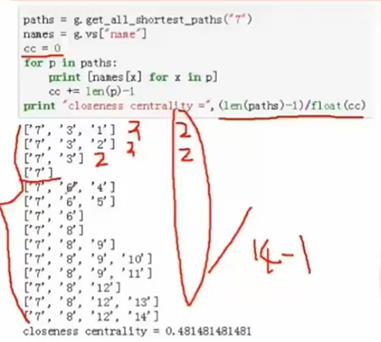
②紧密中心性(closeness centrality)
某个结点到达其他结点的难易程度,也就是其他所有结点距离平均值的倒数。该数值越大,说明周围聚集的点越多。
(路径个数-1)/路径长度
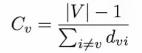
方法1:自己写,Igraph中,有g.get_all_shortest_paths(‘7’) #获得7的所有最短路径
方法2:用igraph中的函数closeness
③介数中心性(betweenness centrality)
网络中的交通枢纽性,拿掉后网络会分裂开。
计算整个网络中任意两个节点的最短路径,当然需要得到具体路径,对各个节点判断该节点是否在最短路径上,最后将刚刚的判断进行累加得到从i到j的最短路径经过该节点的个数,比如数一下,经过7的最短路径有几条。
代码实现:
#coding=utf8 from igraph import * from igraph import Graph as IGraph import os import time import pandas as pd import numpy as np edges = [] path = \'./data/\' firstline=True for file in os.listdir(path): if file.endswith(".csv"): with open(path+file, \'rb\') as f: for row in f.readlines(): if firstline == True: firstline = False continue parts = row.decode().replace(\' \',\'\').replace(\'\\r\\n\',\'\').strip().split(",") try: u, v, e, weight = [i for i in parts] edges.append((u, v, int(weight), e)) except ValueError: continue g = IGraph.TupleList(edges, directed=True, vertex_name_attr=\'name\',edge_attrs=[\'weight\',\'relationship\']) #中心度计算、紧密中心性、介数中心性、pageRank等计算 print (\'STARTING TIME : \', time.asctime((time.localtime(time.time())))) data = [] for p in zip(g.vs, g.degree(), g.indegree(), g.outdegree(),g.closeness(weights="weight"),g.betweenness(),g.pagerank(weights="weight",niter=100)): data.append(\'name\':p[0][\'name\'], \'degree\':p[1], \'indegree\':p[2], \'outdegree\':p[3], \'closeness\':p[4] ,\'betweeness\':p[5],\'pageRank\':p[6]) #根据pagerank排个序 result = sorted(data, key=lambda x:x[\'pageRank\'],reverse=True) result1 = pd.DataFrame.from_dict(result) result1.to_csv(\'./outData/graphIndex.csv\',index=False,encoding=\'gb18030\') print(\'ENDING TIME: \', time.asctime((time.localtime(time.time()))))

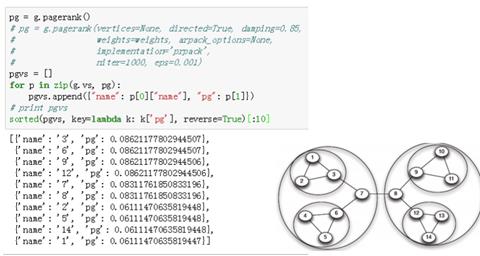
社交网络算法——PageRank算法:
思想:被大量高质量网页引用的网页也是高质量网页(质量高的网页有很多链接指向它)。最初会设置一个初始值,假设所有网页的一个权重是1/N(B0),然后用A*B0去得到Bi(新的权重),其中A还一个方正,比如有7个节点,就是7*7的矩阵,里面的值是每个节点之间边的数量。第三个公式是对第一个的优化,设定α的值(阻尼因子,反应用户停留当前页面而不链走的概率),帮助更快的收敛。该算法其实是利用了马尔科夫链,求得最终收敛的稳定概率,最终停留在一个页面上概率越高,说明该页面越吸引人,质量越好,求出的遍历概率作为PageRank值)。A
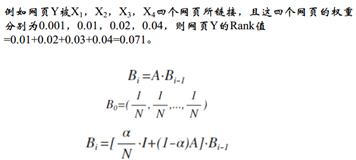
Python中也有现成的包,其中参数damping就是α的值。
复杂网络理论中网络的三大特性:小世界、无标度(无尺度,网络中的度服从幂律)、社区结构
社交网络算法——社区发现算法:
什么是社区?同一社区内的节点与节点之间的连接很紧密,而社区与社区之间的连接比较稀疏。设图G=G(V, E),所谓社区发现是指在图G中确定nc(>=1)个社区C=C1, C2,….Cnc,使得各社区的顶点集合构成V的一个覆盖。
若任意两个社区的顶点集合的交集均为空则称C为非重叠社区,否则为重叠社区。 更加贴近于真实的网络情况,而聚类算法不允许一个点属于多个类。
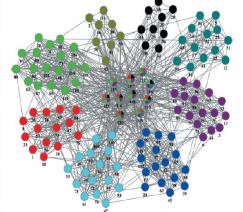
社交发现算法——GN算法:
边介数(betweenness):网络中经过每条边的最短路径的数目。
GN算法:计算网络中所有边的介数;找到介数最高的边并将它从网络中移除;重复,直到每个节点就是一个社团为止。GN算法的复杂度较高,做了一次全网遍历,计算边介数,时间消耗非常高。该算法是最经典的社区发现算法,利用分裂的思想来做的。其中不一定是要计算边介数,你也可以计算度、紧密中心性等等,你可以自己优化该算法。
边介数的计算:

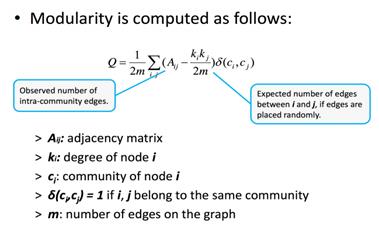
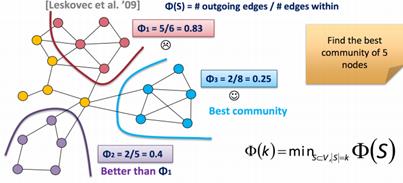
社区评价指标——模块度(评价整个社区划分结果):
模块度,利用了社区结构的定义,社区内的节点联系是比较紧密的,社区中两个节点有边的概率要高于随机图中两个节点有边的概率。Aij是邻阶矩阵(各节点之间相连的边介数),KiKj/2m(所有节点间的边随机连接,两点之间连接的概率)。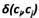 为1,如果i和j属于同一个社区,否则为0。
为1,如果i和j属于同一个社区,否则为0。
社区评价指标——阻断率conductance(单个社区紧密性的评估):
连接到社区外的边数/社区内的节点连接的边个数。越小越好。
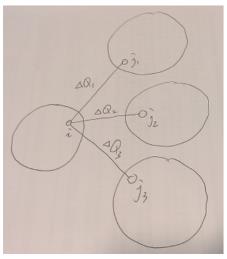
社区发现算法——Louvain算法(工业界中用的较多,并行化后速度更快):
该方法就是利用模块度来优化的一种方法。首先把每一个节点作为一个独立的社区,假设我们把J1加入到i会有一个模块度的增量,把J2加入到i会有一个模块度的增量..等等,从中选出模块度最高的一个邻居节点,加入i的社区中。这是一种启发式的凝聚算法,直到detaQ不会是为正的为止。
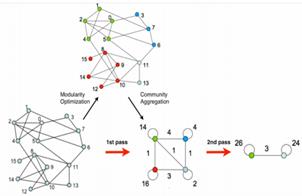
社区发现算法——LPA算法label propagation agrithm(时间复杂度较低近似n,标签传播的思想):
但该算法在工业界并没有很好的实践,开源社区给出的代码,稳定性并不是很好。优点:不需要预先知识,不用预先给定社区的数量,可以控制迭代的次数来划分节点类别。可扩展性强,时间复杂度近线性,适合处理大规模复杂网络。
算法思想:初始化每个节点,给其唯一标签;根据邻居节点最常见的标签更新每个节点的标签;最终收敛后标签一致的节点属于一个社区。
同步更新:可能存在最后不能收敛的情况。
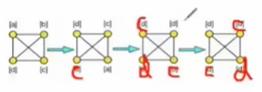
异步更新:使用到上一次我的节点更新的信息
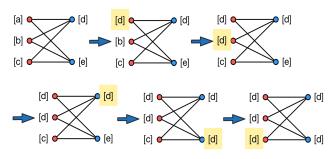
spark中scala语言实现,graphx包中有该方法,如果不做优化调用该包,可能结果不是很稳定,效果不会很好

社区发现算法——SLPA算法(LPA算法的改进)speaker listener propagation agrithm
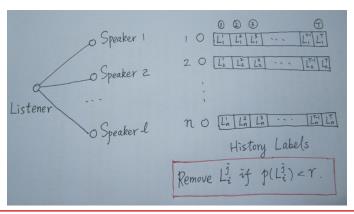
算法思想:之前LPA算法,每个节点只有一个标签,SLPA给每个节点设置一个列表来存储历史标签,每次迭代更新的标签都存储起来;
如下图,每个Speaker节点带概率选择自己标签列表中的标签传播给listener节点(Speaker节点为Listerner节点的邻居节点);节点将最热门的标签更新到标签列表中(如果迭代20次,则存储20个标签);使用阈值r去删除低频标签,产出标签一致的节点为社区。(支持非重叠社区)类比现实中,我们有很多朋友,这些朋友都在跟我说一些消息,如果有多个朋友跟我说同一个消息,我记住的可能性也会非常大。
社交网络算法在金融反欺诈中应用
传统反欺诈主要是评分卡,其实就是逻辑回归,只是变量的选取会有一定的技巧。
应用社交网络反欺诈:客户一度、二度关系是否触黑;客户消费关联商家是否异常;一机多人;识别组团欺诈(离线情况下,社区划分,可能有些社区的违约率很高,我们就把他贴上拒贷用户的标签,对于新来的用户,就可以判断他属于哪个社区)
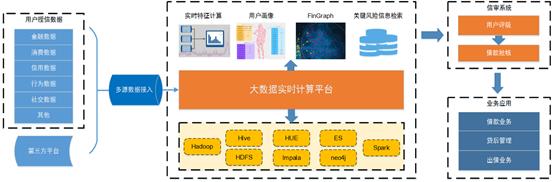
业界现在有构造知识图谱

以上是关于SNA社交网络算法的主要内容,如果未能解决你的问题,请参考以下文章