服务接口测试自动化工具的研究
Posted 隔壁王书
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务接口测试自动化工具的研究相关的知识,希望对你有一定的参考价值。
1.基于模型的测试生成
在需求分析时,我们遇到了以下4个问题需要解决:
1)自动化生成方法固然能够在短时间内快速生成大量测试数据,但是如何挑选具有高覆盖率、低数量级的测试数据集?这对于降低后续测试执行成本而言是一个关键问题;
2)无论采用哪种组合算法,生成的决策表都会存在冗余和无效的决策,如果不能及时剔除,在后续生成测试用例时会造成额外的开销;
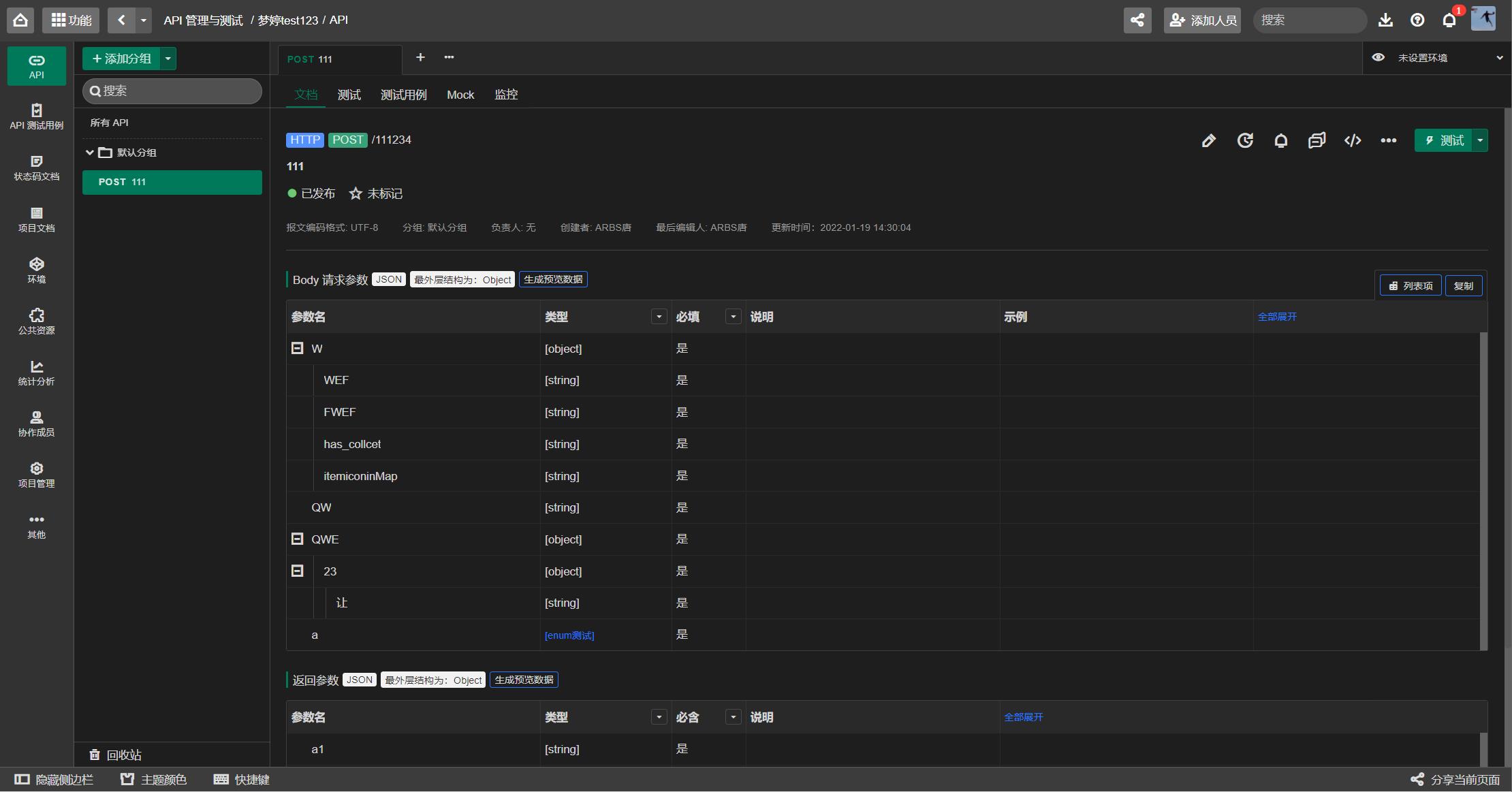
3)被测服务的开发语言存在差异,测试工具可以根据自然语言描述的服务接口文档完成建模工作,无需关注内部实现语言,但在生成测试代码时却缺少灵活性,只能以程序中固化的方式生成特定语言的测试代码;API文档编写内容。详细内容防止重复编写用例;
4)进行组合测试时,服务之间会存在数据和控制依赖关系,如何能便捷直观地描述各种依赖关系,高效完成测试计划编排?
针对上述问题,我们在测试工具的设计与实现中采取了针对性的解决方法。
2.基于数据分区的组合测试数据生成
基于数据模型和服务模型中的参数约束,可以根据测试覆盖率的需求生成测试数据。
使用服务参数的整个输入域作为测试输入,无疑会得到最大的测试覆盖率,但是会带来针对性差、代价高的问题。并且,当同时存在多个参数时,追求全覆盖会导致参数组合爆炸。
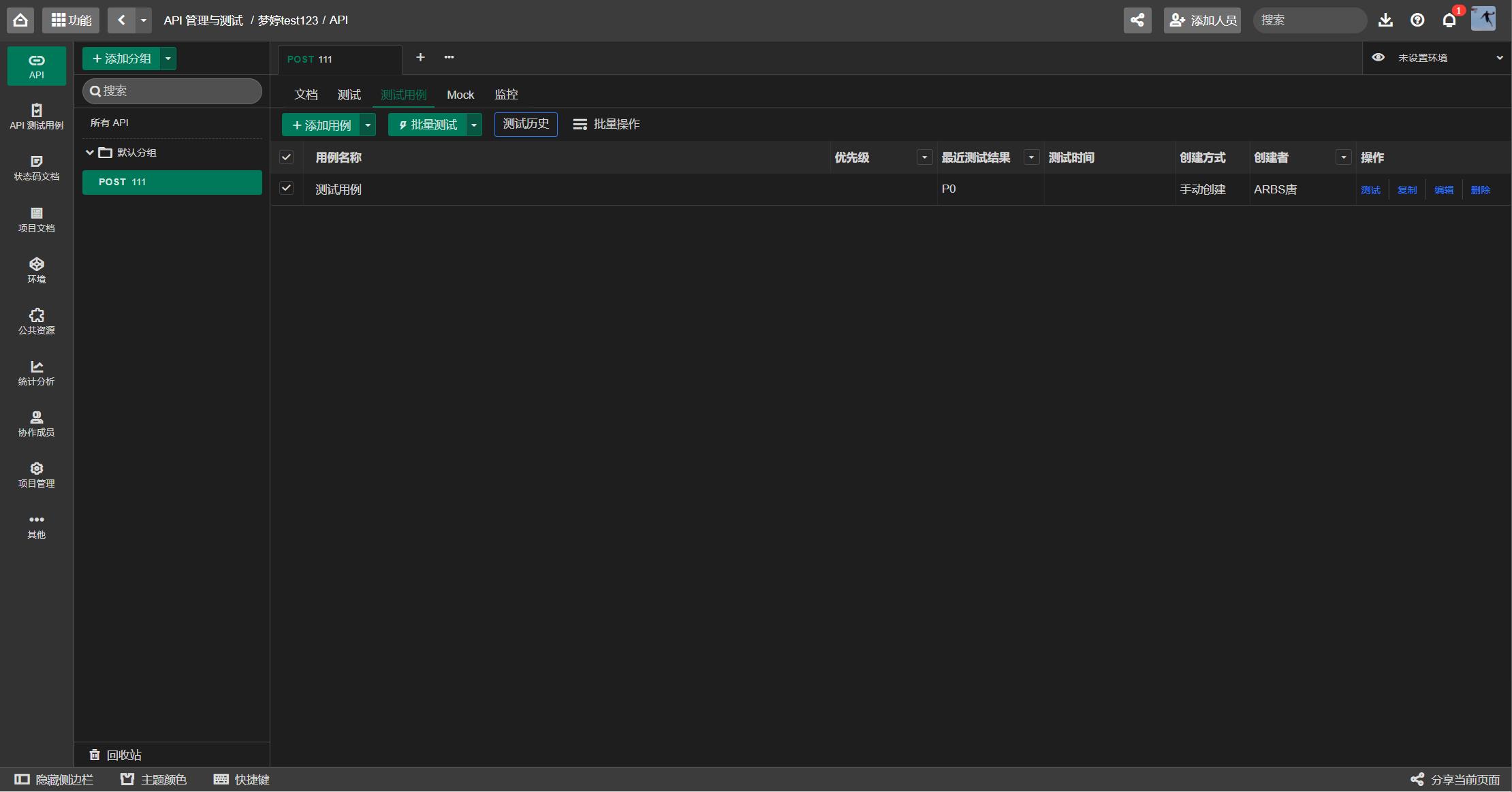
为此,本文提出基于数据分区的组合测试方法,通过为服务参数的输入域划分数据分区并为分区组合构建决策表,解决测试数据生成的盲目性问题,同时在覆盖率和组合爆炸之间取得折中。方法描述有效设置测试用例,使用Eolink测试工具编写测试用例。
1)数据分区划分。依据等价类划分的思想,为服务的每个输入参数划分数据分区,包括合法分区和非法分区,用于描述更加细化的参数数据约束条件;
2)分区数据集设置。针对每个数据分区,可采用随机方式或者自定义方式从每个分区中选取少数代表性数据作为分区数据集,用于最终的测试数据自动生成。分区数据集的设计,既有效避免了使用整个分区作为输入时可能导致的测试数据量过大的问题,又能有效提高测试的针对性,为满足使用尽量少的测试用例达到尽量大的覆盖率的测试目标提供了可能;
3)决策表生成。以服务的输入数据分区作为条件属性,以服务的返回值作为决策属性,为服务的输入参数组合创建决策表。为了避免组合爆炸,采用了多种组合测试算法(全组合、IPO2组合、基于拟水平法的正交实验设计、基于并列法的正交实验设计)来生成满足不同测试覆盖率需求的决策表。
计划模型的测试用例来自于其组成服务的测试用例集组合,对这些用例数据进行笛卡儿积组合遍历无疑会导致组合爆炸,因此,也采用组合测试算法来支持计划模型的测试数据生成。
以上是关于服务接口测试自动化工具的研究的主要内容,如果未能解决你的问题,请参考以下文章