计算机网络再次整理————tcp例子[五]
Posted 程序员其实就是一个写文档的工作,代码只是文档的一部分,一切皆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机网络再次整理————tcp例子[五]相关的知识,希望对你有一定的参考价值。
前言
本文介绍一些tcp的例子,然后不断完善一下。
正文
服务端:
// See https://aka.ms/new-console-template for more information
using System.Net;
using System.Net.Sockets;
var socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
var ipAddress = IPAddress.Parse("127.0.0.1");
EndPoint endPoint = new IPEndPoint(ipAddress, 8888);
socket.Bind(endPoint);
socket.Listen();
while (true)
Console.WriteLine("开始接收");
var clientSocket = socket.Accept();
Console.WriteLine("接收到消息");
var receiveMessage = new Byte[1000];
clientSocket.Receive(receiveMessage);
Console.WriteLine("receive message is:"+System.Text.Encoding.UTF8.GetString(receiveMessage));
clientSocket.Close();
客户端:
using System.Net;
using System.Net.Sockets;
var socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
var ipAddress = IPAddress.Parse("127.0.0.1");
EndPoint endPoint = new IPEndPoint(ipAddress, 8888);
socket.Connect(endPoint);
socket.Send(System.Text.Encoding.UTF8.GetBytes("hello service"));
socket.Send(System.Text.Encoding.UTF8.GetBytes("hello service2"));
Console.WriteLine("发送成功");
Console.ReadLine();
服务端打印:

可以看客户端发送了两次,但是服务端一次就读取出来了,这就是著名的粘包。
为什么会有粘包这个现象呢?首先来分析一下这个粘包的原因,抓包即可。
看到第一次发送的包:
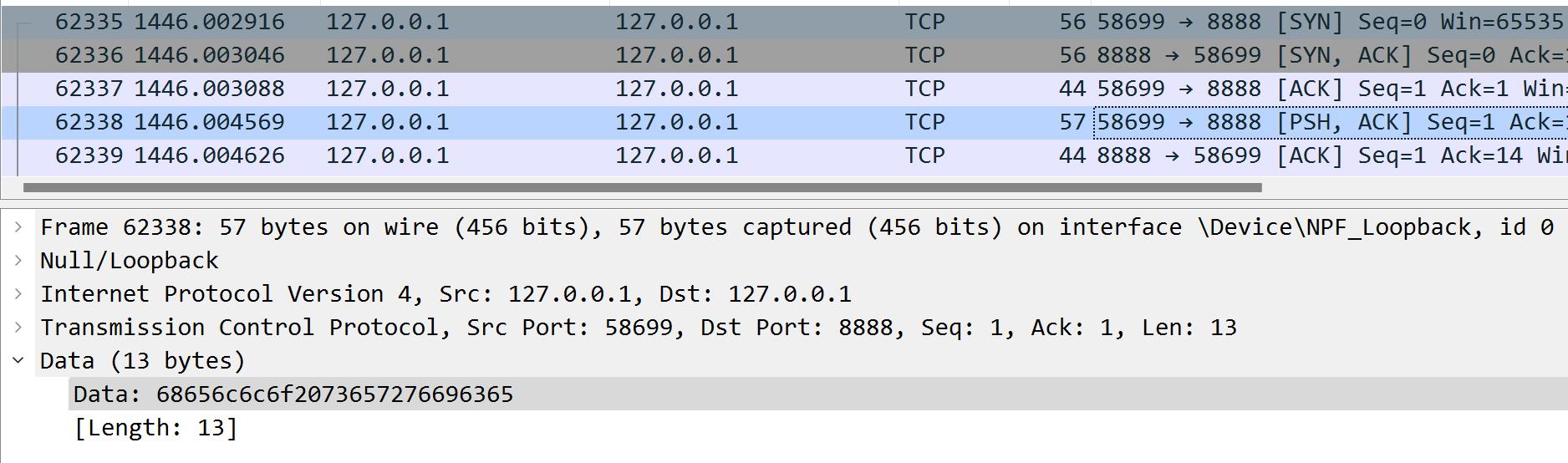
看到第二次发送的包:
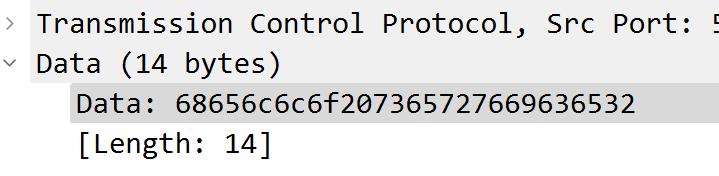
看来跟客户端没有关系了。
这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
那么有没有可能粘包是客户端造成的,或者说发送方造成的?当然也是很多有可能的,这里就不作演示,单纯的理论一下。
TCP 协议是面向连接的、可靠的、基于字节流的传输层通信协议,应用层交给 TCP 协议的数据并不会以消息为单位向目的主机传输,这些数据在某些情况下会被组合成一个数据段发送给目标的主机。
比如说nagle 算法:
Nagle 算法是一种通过减少数据包的方式提高 TCP 传输性能的算法。因为网络 带宽有限,它不会将小的数据块直接发送到目的主机,而是会在本地缓冲区中等待更多待发送的数据,这种批量发送数据的策略虽然会影响实时性和网络延迟,但是能够降低网络拥堵的可能性并减少额外开销。
在早期的互联网中,Telnet 是被广泛使用的应用程序,然而使用 Telnet 会产生大量只有 1 字节负载的有效数据,每个数据包都会有 40 字节的额外开销,带宽的利用率只有 ~2.44%,Nagle 算法就是在当时的这种场景下设计的。
当应用层协议通过 TCP 协议传输数据时,实际上待发送的数据先被写入了 TCP 协议的缓冲区,如果用户开启了 Nagle 算法,那么 TCP 协议可能不会立刻发送写入的数据,它会等待缓冲区中数据超过最大数据段(MSS)或者上一个数据段被 ACK 时才会发送缓冲区中的数据。
除了 Nagle 算法之外,TCP 协议栈中还有另一个用于延迟发送数据的选项 TCP_CORK,如果我们开启该选项,那么当发送的数据小于 MSS 时,TCP 协议就会延迟 200ms 发送该数据或者等待缓冲区中的数据超过 MSS。
无论是 TCP_NODELAY 还是 TCP_CORK,它们都会通过延迟发送数据来提高带宽的利用率,它们会对应用层协议写入的数据进行拆分和重组,而这些机制和配置能够出现的最重要原因是 — TCP 协议是基于字节流的协议,其本身没有数据包的概念,不会按照数据包发送数据。
好了,现在知道了粘包问题了。
上面这段代码还有另外一个问题,那就是比如我们传输1个G的数据,那么操作系统会帮我们分成很多个包进行拆分。
比如1g数据分成了100个包了,接收方没有接收完,就调用了读取。这时候又该怎么处理呢?我是读取到了50个包的时候完成了,还是读取80个包的时候完成了。
这些就是应用协议应该解决的问题了。
我们知道数据链路层通过再数据前后增加标识符来变成帧来识别一段数据的。
而网络层,如果是比较大的包,那么路由器会进行拆包,但是包里面标记了序号,同样标记了每个包的大小,和总包的大小。(ip报文分片)
首先tcp是按顺序传输的,这样呢,我们就不用标记序号了,那么就有两个选择了:
- 在数据前后标记,这样便于分割或者组合
- 在数据里面增加消息的大小,比如说有缓存了100个字节,前面4个字节表示后面消息的大小
要真正的写好这两个还是比较多code的,后面找个时间补充。而且网上例子挺多的。
可以去搜tcp数据无边界问题,不一定只搜粘包问题,比如说发送1G数据,到底什么时候才算收完,这就不叫粘包了,但是属于tcp无数据边界问题。
当然了粘包给出的方案也解决了数据无边界的问题。
结
下一节,简单介绍一下udp吧。很多问题,其实在以前的网络编程系列中提及到了,后面依然会整理,可能会反复整理几次。
以上是关于计算机网络再次整理————tcp例子[五]的主要内容,如果未能解决你的问题,请参考以下文章