

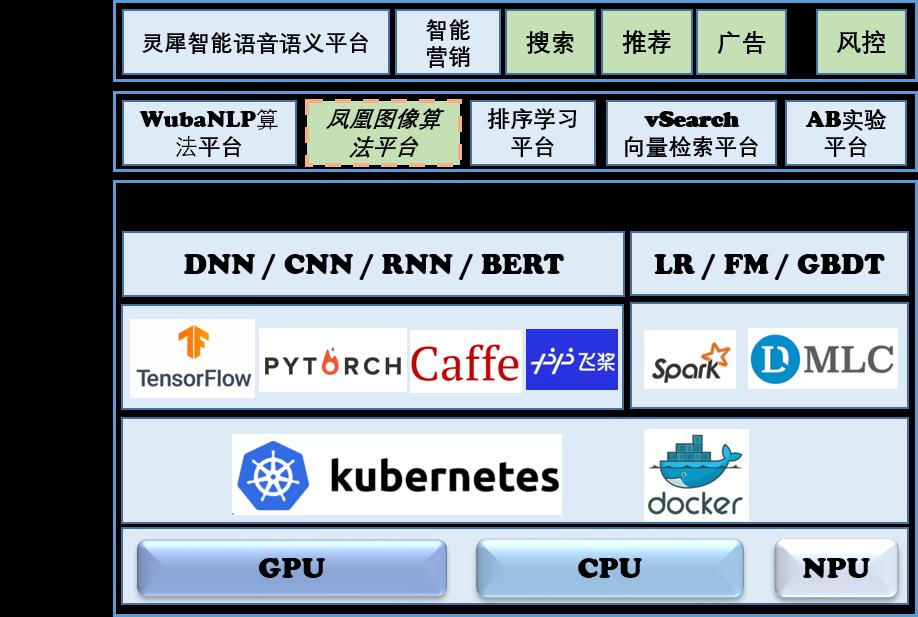
特征存储及计算在CRM商机智能分配中的实践
作者:周磊,58同城 AI Lab 大数据开发工程师
导读:本文介绍的是在CRM智能推荐场景中,所用到的机器学习和推荐技术的模型训练及线上预测的特征数据推送部分,我们应用此套特征推送流程而上线的模型多达几十种,获得了可观的收益。目前特征自动化推送广泛应用于黄页、招聘、创新、转转等业务场景中。
本文收益:了解58CRM商机智能分配场景中的个性化推荐/搜索所采用的特征来源,即特征存储、计算及后续处理方式。
内容如下:
一. 背景介绍
二. 数据流程
三. 特征仓库
四. 特征计算
五. 特征聚合
六. 总结规划
七. 部门简介
CRM系统是服务于我们58销售团队的一个重要系统。面对庞大的历史商机库,我们AI Lab开展了商机智能分配项目。该项目旨在将机器学习和推荐技术应用于CRM,为每个销售人员分配适合其跟进的商机,优化成单转化,以提高销售团队业绩,进而提升业务线收入。
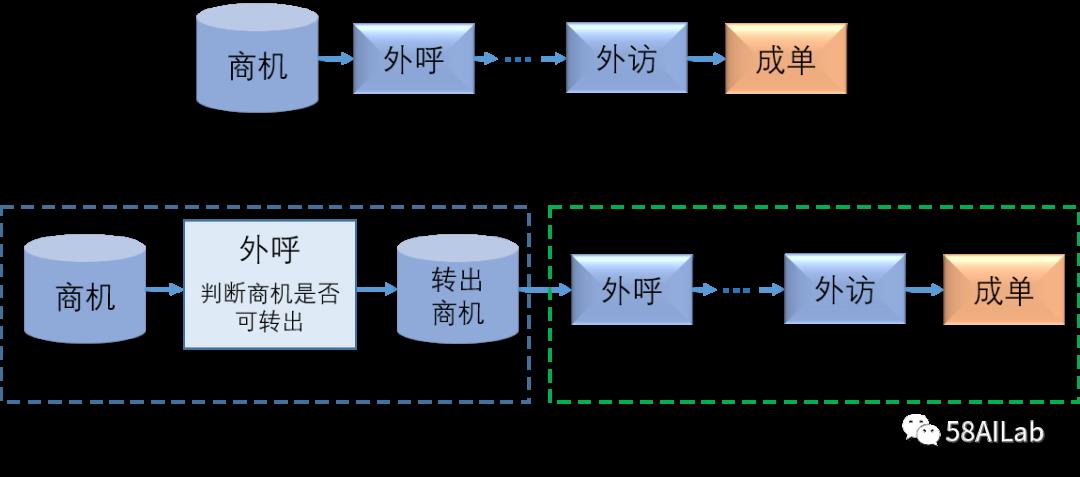
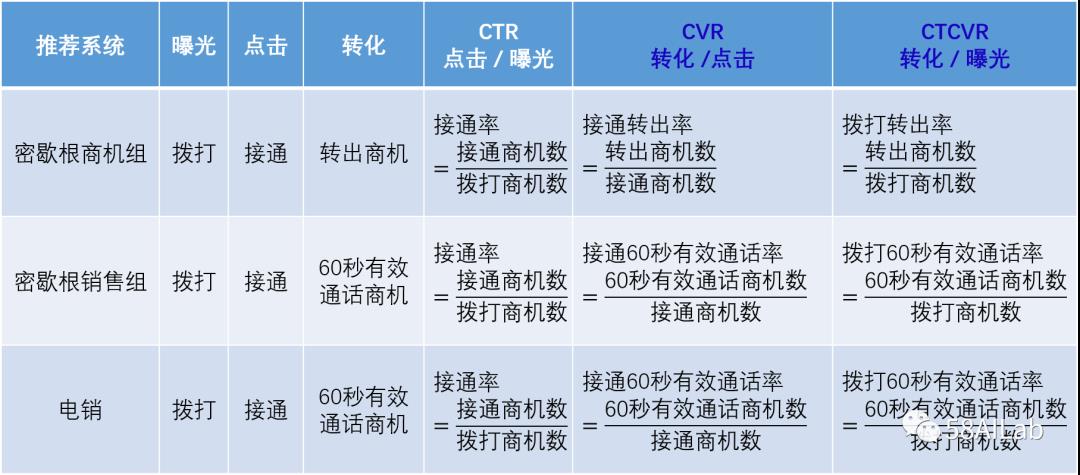
58黄页(本地生活)直销业务线采用的是密歇根营销模式。具体是将销售团队分为商机组和销售组,商机组的职能是商机意向初筛,过滤出有成单意向的商机后转出到销售组的转出商机库,销售组的职能是从转出商机库中进行跟进最终成单。两个团队的销售跟进单位都是商机,即对58潜在会员抽象出来的实体。项目详细介绍请参考公众号文章《AI+CRM提高企业的绩与效》。
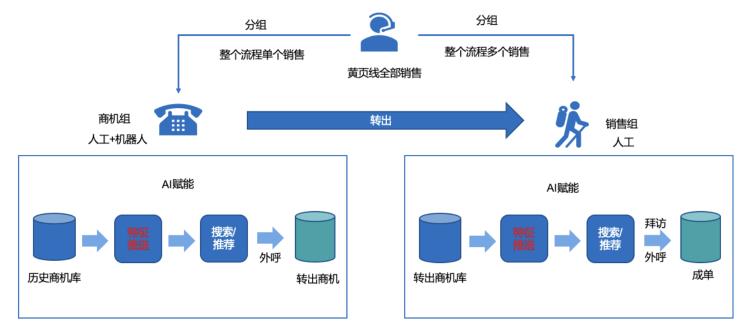
我们从相应的商机库中挖掘出不同维度的特征,进行计算及转换后输出到模型中进行训练和预测。本文介绍的就是服务于CRM系统中的个性化推荐/搜索排序等相关模型的特征数据推送部分。
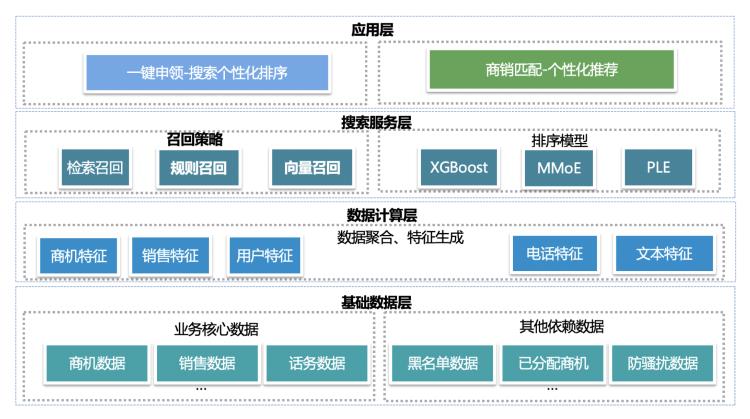
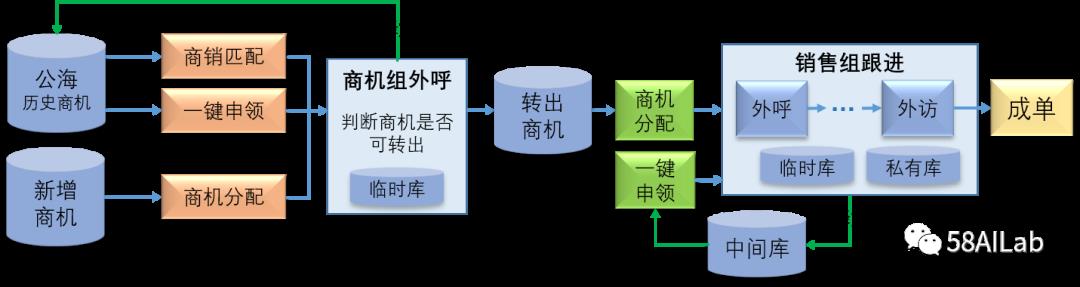
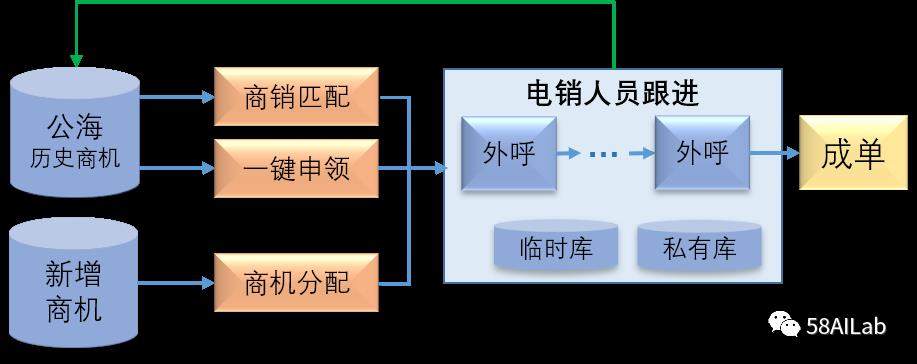
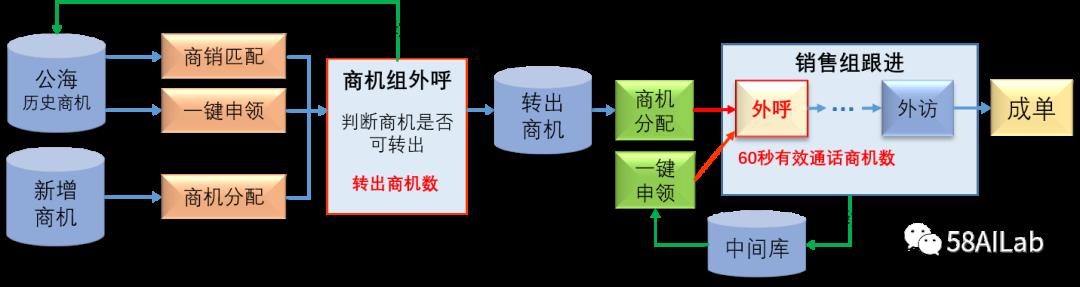
上图是我们AI接入CRM系统的架构图。应用层中的一键申领和商销匹配是密歇根模式引入CRM系统的两个场景,通过引入不同的场景,可以切分成单链路,让销售的目标更加明确,同时我们可以接入更多的AI模型去提升销售的工作效率。一键申领场景即销售主动从商机库中拉取商机,商销匹配场景即系统主动给销售分配到最适合该销售的商机。搜索服务层就是我们场景相关的模型,这里后续会有其他文章进行介绍。数据计算层中的特征计算及处理,和基础数据层中的业务核心数据建设即特征仓库,是我们今天分享的重点。场景的多元化与模型的丰富性加大了我们特征推送的难度,下面介绍一下特征推送自动化流程的具体实践。
需求分析:为了能满足下游模型迭代的特征需求,并且快速推送出相应特征数据。基于此,我们梳理了数据流程,大体可划分为以下几个模块。
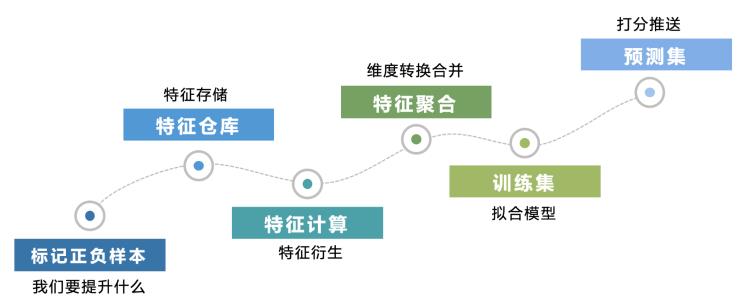
正负样本标识会根据业务线和场景的变化而变化,即和目标提升业务指标高度相关,这里很难做到抽象出公用框架。而对于特征仓库、特征计算和特征聚合,可以做出通用流程,节省人力和效率。最后的预测集和训练集可以基于前两步的数据升级进行通用化。所以这里核心是特征存储和特征计算及其处理。下文将从特征仓库、特征计算、特征聚合三方面叙述自动化特征数据推送的业务点和技术点。
特征仓库可以类比于数据仓库,区别是数仓是为了建设各项数据指标服务,而特征仓库是为了建设基础特征服务。经过探索和积累,我们主要基于HBase的特征仓库业务架构如下:
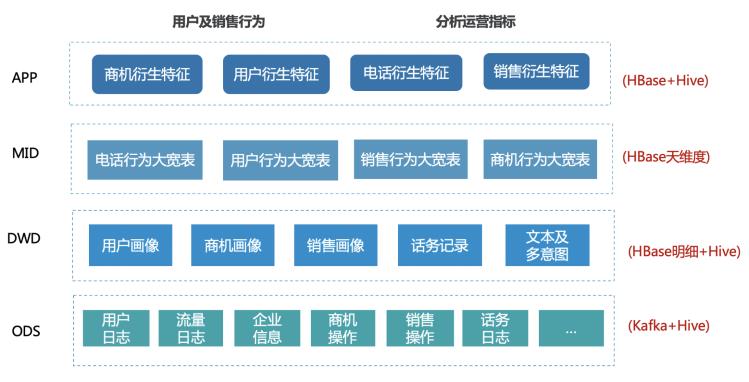
上述架构中的部分表来源于数仓,基于底层数据可以开展各类基础数据计算统计。整体也参考了经典的数仓分层架构,实用性优点这里不予介绍。值得一提的是,由于hive不满足我们的特征仓库的建设,所以hbase的选型在我们的场景里至关重要。
需求分析:
-
由于特征库的要求是表里需要存放至少一年半的特征数据并每日更新当日特征数据,有数据量大及缓慢变化的特性,后续存储也是用了拉链表的思想,可以大幅减少存储内存占用。
-
随着特征更新,需要对特征进行版本管理,如在帖子维度中,我们场景存放的是最近三年下的最近三万条帖子。
-
特征存储要具有灵活性和扩展性,因为算法迭代经常需要尝试不同的特征组合,可能需要新增特征维度,并对特征进行选择及补充相应历史数据。
-
一方面维度分支多,需要聚合成主题大宽表。另一方面,我们部分主题接入了实时,需要对离线和实时融合做兼容。
解决方案:上述分析具体可以概括为三个特性:存储性、扩展性及更新融合性。相应解决办法如下:

作为一种可以高并发和随机读写的K-V数据库,Qualifier-Value可以很好的存储结构化的特征。这里特征仓库ETL的过程应用了很多HBase的特性。
比如对于DWD层的话务表存放的一条数据的例子是:RowKey为电话散列后的电话ID,其中的一对K-V明细数据为:call_01_20210508101358_108:json_feature。相应含义是该电话在01业务线下于2021-05-08 10:13:58秒时接通了108秒,json_value可以存放具体的明细字段。这样当离线数据以同样的逻辑写入(二者时间戳设置相同,可以为拨打时间等),可以直接覆盖该条明细数据,达到实时和离线的融合。然后下游读取时设置TimeStamp为日期,就可以过滤出天维度的特征,然后解析相应json得到的特征经过加工就可以导入到MID层中天维度的HBase特征表中,方便后续进行天粒度的特征计算。同时,结合HBase TTL和Cell多版本特性可以达到特征的自动化管理。
随着维度和新特征的不断增加,基于此种特征仓库建设可以覆盖现有后续几十种的模型特征需求。
本场景的特征计算是在内存中进行大量的离线计算,主要指上述特征仓库中的MID层->APP层的计算,即从维度大宽表中的海量数据及基础特征中,过滤出指定的样本集和特征集来缩减计算量,再采用特征字典+特征矩阵(下文会具体介绍)完成高效计算,输出为深度学习可以直接使用的特征,或者输出后进行特征聚合再输出到机器学习使用的特征。具体内容及实现如下:
计算逻辑:基于商机、电话、用户和销售四个粒度,对其进行基础特征+产品线+计算函数+时间窗进行组合衍生计算,最后输出特征。
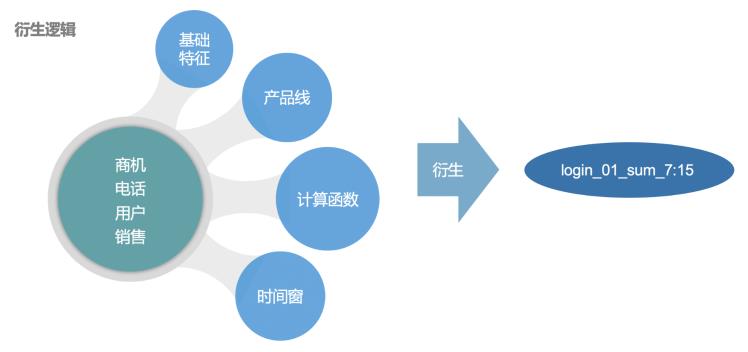
上图中输出特征的含义为某用户在01业务线下7天内登录总次数为15次。
其中,login_01是基础特征,01就是业务线,这里把业务线也作为一个维度,是因为取了不同业务线的特征;然后,SUM是指该特征的计算函数是求和,我们特征衍生计算的计算函数包含了十多种类型,分别是:COUNT(),SUM(),MAX(),MIN(),MAXPARTITION(),MEAN(),MEDIAN(),STD(),RANGE(),MODE()等,这里具体函数含义即为其中文含义,当然对于每一种基础指标,我们会采取其适合的统计方式;最后,时间窗可以自由定义且窗口不交叉,比如时间窗可以是3,7,15,30,90,180。
业务痛点:由于承接的业务线多,每条业务线又有不同的场景,这里的目标是:打造一套剥离出业务逻辑又适用于各种场景的高效特征计算架构。具体梳理来看,主要需要考虑到以下六个问题:
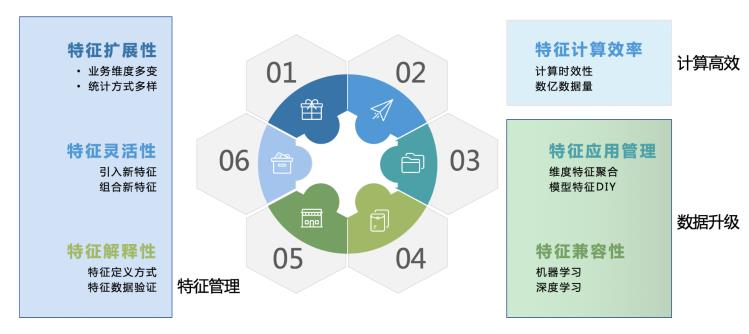
可以抽象出三类问题:
-
特征管理:主要包含图中左半部分的第1,5,6三个问题。目前我们线上有几十个模型,部分模型采用的特征不同,这就对统一的特征计算架构提出兼容不同模型特征的要求,且要提供模型特征选择种类及相应说明给算法、产品及负责人。
-
计算高效:主要是指图中第2个问题。从数据推送流程中可以看到,除了负责离线提供训练集,每日凌晨还需要推送全量数据的预测集到各业务线,以供相关模型进行预测打分,之后推送给CRM端。由于我们的特征的来源有部分是基础数仓,且数仓计算耗时较长,所以留给特征计算的时间很有限,必须高效的完成计算且推送数据出去。
-
数据升级:主要包含图中第3,4个问题。真实的线上运行时,一方面,算法迭代需求会涉及到尝试新老特征组合效果,以及同一场景下不同模型间也会有特征调整的问题;另一方面,对于后续输出特征要兼容到机器学习及相关推荐模型,还需要对特征进行进一步处理加工。
对于上述三类问题,解决方案分别是:特征字典,特征矩阵,聚合存储。其中,聚合存储为数据升级后的结果,放在下部分介绍。先介绍这里的架构设计及其他两项。
架构设计:基于特征仓库设计的特征计算的架构如下,设计为HBase+Spark技术实现,其中也用到了许多HBase的生态组件。
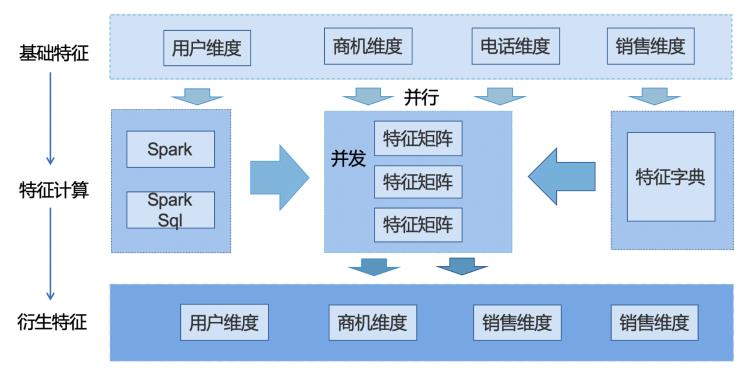
基础特征和衍生特征分别对应的特征仓库的MID层,APP层,中间层引入特征字典+特征矩阵的概念实现高效的计算方式。具体流程大致为:每日凌晨数据运行时,每个维度起一个计算任务进行并行计算。
首先,每个任务内先过滤出相应产品线的不同维度的全量ID,通过对HBase的一个列族打上目标计算群体的标签,然后根据标签用Filter Api过滤出样本集;然后,根据TimeStamp读取初所需要计算的时间跨度内的特征,并读取特征字典表来告诉程序需要计算的具体特征;最后,在内存中每个用户都转化为一个特征矩阵(只存储有效特征),根据计算类型并发计算各个ID的特征,写入衍生特征层。
特征字典:特征字典可类比维度字典表,存放的是特征仓库MID层各个宽表中的基础特征。为了解决以上特征管理的问题,这里我们设计了具体字段,部分字段展示如下:
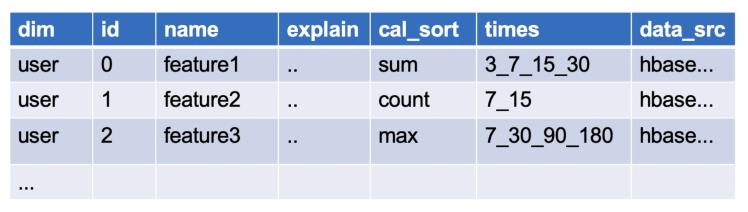
dim存放的是基础特征的维度,id是基础特征对应的特征编码,name是特征名称,explain是对应的中文含义,cal_sort是具体的计算类型,times是衍生逻辑里的时间窗,data_src是基础特征对应的数据源HBase表。
特征矩阵:在计算内存中,每个ID都会转化为一个特征矩阵,之后的计算函数会全部基于这个特征矩阵进行计算。其中,矩阵的行定义为用户维度的特征个数,列定义为时间窗跨度。当计算时,通过查询特征字典表告诉程序所需要计算的特征及类型,然后在特征矩阵中找到相应特征具体的坐标:X(特征ID)和Y(时间窗)的非0有效特征值。最后传入有效值的坐标进行计算。这样可以极大程度上减少存储、简化计算,提高计算效率。具体计算效果如下:
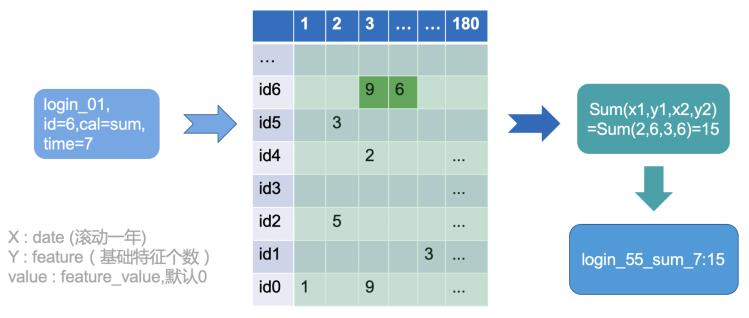
表格中阴影部分就是特征矩阵,因为用户的特征都是稀疏的,所以利用稀疏矩阵的存储方式,只存储有效数据。假设A用户是一个100*365的稀疏矩阵,则对应转换示意图如下:
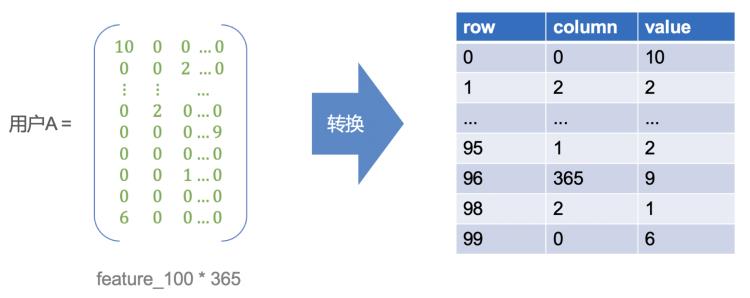
每个用户在内存中转换为二维数组之后,然后根据计算类型和时间窗就可以并发计算出衍生特征。
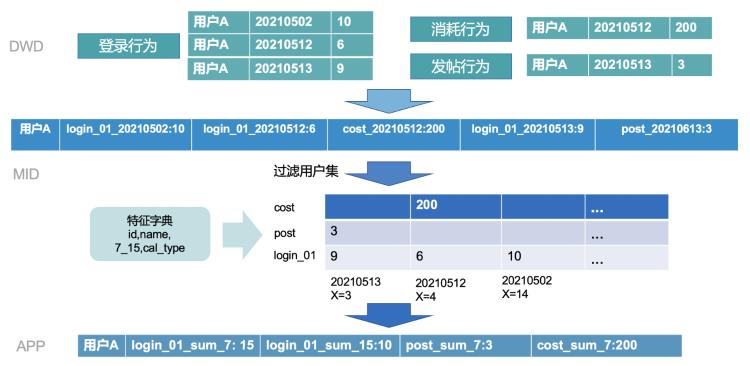
下面是结合上文的特征仓库从DWD->特征计算->APP层全局展示的一个例子。如用户A有三个分支的行为,先聚合到MID层日维度HBase,这里login_01_20210502的设计方式可以很好的管理特征版本,并利用HBase根据RowKey进行聚合成一行,最后在计算内存中形成特征矩阵,衍生出结果保存到APP层。
计算优势:
-
新增特征时只需要更改字典表即可,可以实现特征计算的代码0修改,维护起来也简单。
-
特征个数提高为原来的5倍,通过不同维度直接衍生,统计出相应组合效果的特征。
-
通过Filter过滤器减少数据集计算量,不同维度并行计算以及基于特征矩阵的并发计算,可以极大的提高计算效率。
-
全计算任务无具体业务逻辑,可以提升复用至多个产品线。
实际上这里的特征数据可以输入深度学习进行模型训练,但是考虑到兼容机器学习(Libsvm数据格式),后续还需要进行特征聚合,并且对数据进行升级,兼容二者。
聚合存储分为以下两方面介绍:特征聚合和升级存储。
特征聚合:基于特征计算的逻辑聚合,也就是根据产品线、计算函数、时间窗的组合进行聚合。一个商机下可能关联多个用户ID和电话ID,根据关联的ID把同种组合特征按照该特征的相应计算逻辑(求和,最大值等)聚合到一条商机下。
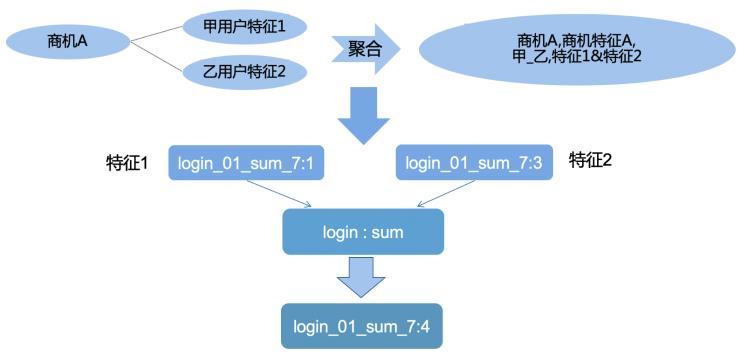
维度转换是根据不同场景的业务需求时常变更的,这里复用了上文的特征计算的衍生逻辑,只需要根据相应的特征进行Groupbykey指定维度就能快速聚合,输出最终特征。
升级存储:兼容下游机器学习和推荐技术的众多模型时,不同模型使用的特征会有不同,所以数据存储及如何对接模型需要做一个统一的管理。相关设计如下:
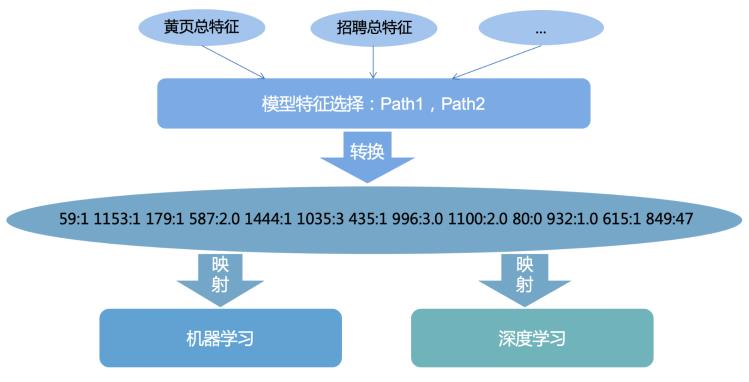
这里的方案是每个业务线计算出全量的特征后,采用Libsvm的方式进行数据存储,下一步相关模型会进行训练而选择出需要使用的高收益特征列表并保存在Hdfs上,然后根据不同模型选择的特征子集进行映射输出到预测集。以这种维护一套总特征的方式来兼容机器学习和深度学习的不同模型,相比Json存储可以降低约70%的存储容量,并且很好的管理不同模型需要的特征。
当前,我们已经打造出一套相对自动化特征推送体系,覆盖了下游现有AI模型的基本特征需求,推动了个性化搜索/推荐技术应用于CRM系统,为58升级收入增长引擎贡献一份力量。未来,我们会持续优化当前AI模型的数据及效果,加入基于NLP生成的文本特征,再引入实时特征数据,用更多数据思维成果来推动AI赋能落地及升级。