Python获取html页内容
Posted 悟透
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python获取html页内容相关的知识,希望对你有一定的参考价值。
一个简单的python获取html页面
版本说明:
Testing system os : Windows 7
Python : 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 22:20:52) [MSC v.1916 32 bit (Intel)] on win32
安装模块:
1.requests模块安装
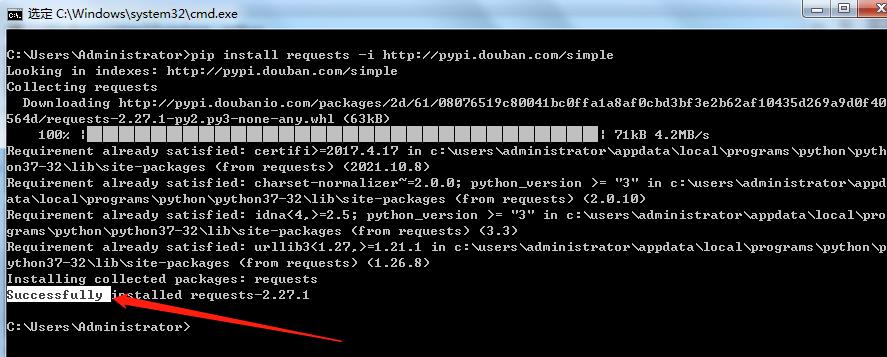
C:\\Users\\Administrator> pip install requests -i http://pypi.douban.com/simple
看到Successfully 就是安装成功了,参数-i是临时指定去那个网站找模块,国内也有其他源可以选择
2. lxml模块安装
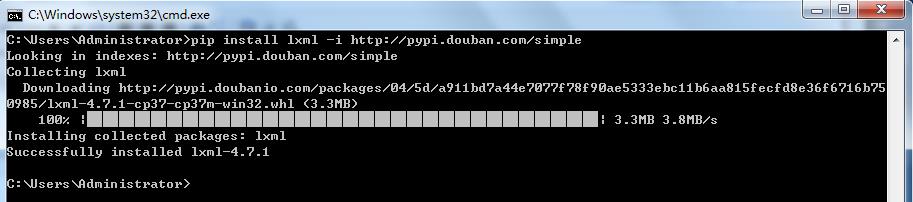
C:\\Users\\Administrator>pip install lxml -i http://pypi.douban.com/simple
看到Successfully 就是安装成功了,参数-i是临时指定去那个网站找模块,国内也有其他源可以选择
获取html内容:
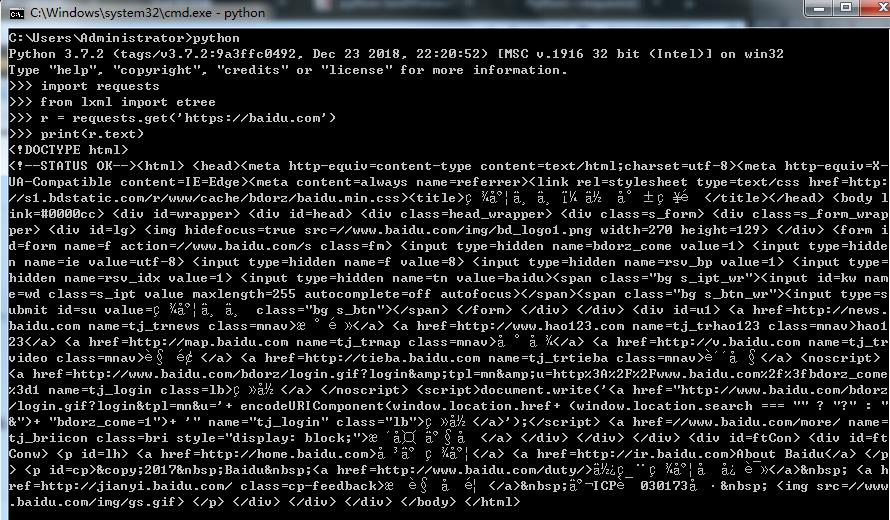
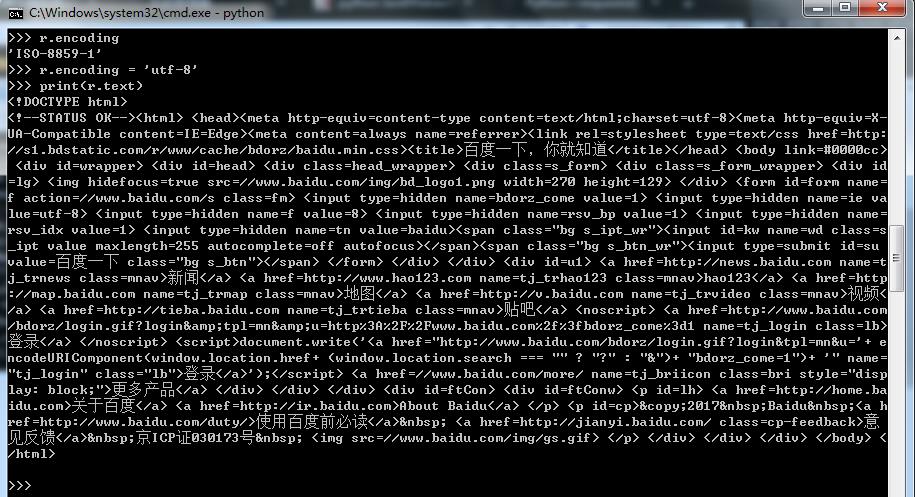
## 引入模块 > import requests > from lxml import etree ## 打开baidu.com网站 > r = requests.get(\'https://baidu.com\') ## 汉字显示乱码 > print(r.text) ## 查看当前编码 > r.encoding ## 设置编码utf-8 ,因为网页是utf-8,编码不对显示汉字会乱码 > r.encondig = \'utf-8\' ## 重新打印汉字就正常显示了 > print(r.text)
汉字显示乱码
设置编码后汉字显示正常
参考:
https://www.jb51.net/article/161053.htm
https://www.cnblogs.com/lanyinhao/p/9634742.html
以上是关于Python获取html页内容的主要内容,如果未能解决你的问题,请参考以下文章