PTA数据结构和答案解析
Posted 旭风°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PTA数据结构和答案解析相关的知识,希望对你有一定的参考价值。
title: "PTA数据结构和答案解析"
author: Sun-Wind
date: January 8, 2022
背景:期末数据结构复习题
绪论和线性表
判断题
The Fibonacci number sequence F N is defined as: F 0 =0, F 1 =1, F N =F N−1 +F N−2 , N=2, 3, .... The time complexity of the function which calculates F N recursively is Θ(N!).
F
根据递推我们可以直到时间复杂度为O(N);
(logn)^2 is O(n).
这个题其实我觉得应该是错的,根据渐进时间复杂度的定义,logN * logN / N ,求无穷大时利用洛必达法则,两者是不等价的,但是答案是T,要是评论区有大佬知道欢迎指出
An algorithm may or may not require input, but each algorithm is expected to produce at least one result as the output.
T
概念题
NlogN^2 and NlogN^3 have the same speed of growth
T
只有前面的系数常数不一样,显然正确
N2logN和NlogN2具有相同的增长速度。
F
显然不对,一个系数是平方,一个是线性系数
2^N 和N^N 具有相同的增长速度
F
太简单的咱就不说了哈
算法分析的两个主要方面是时间复杂度和空间复杂度的分析
T
对于顺序存储的长度为N的线性表,访问结点和增加结点的时间复杂度分别对应为O(1)和O(N)
T
若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用顺序表存储最节省时间。
T
对于顺序存储的长度为N的线性表,删除第一个元素和插入最后一个元素的时间复杂度分别对应为O(1)和O(N)。
F
时间复杂度反了,删除第一个元素线性表会把所有的元素向前移动
线性表L如果需要频繁地进行不同下标元素的插入、删除操作,此时选择顺序存储结构更好。
F
链表更好
队列的特性
队列是后进先出的线性表。
F
队列先进先出
具有N个结点的单链表中,访问结点和增加结点的时间复杂度分别对应为O(1)和O(N)。
F
时间复杂度反了
将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。
F
线性表才是O(logN)
若用链表来表示一个线性表,则表中元素的地址一定是连续的。
F
链表 - 存储结构
链表中逻辑上相邻的元素,其物理位置也一定相邻。
F
链表 - 存储结构
链表是一种随机存取的存储结构。
F
线性表才是随机存取
单选题
在数据结构中,从逻辑上可以把数据结构分成( )。
(1分)
A.动态结构和静态结构
B.紧凑结构和非紧凑结构
C.线性结构和非线性结构
D.内部结构和外部结构
与数据元素本身的形式、内容、相对位置、个数无关的是数据的( )。
(1分)
A.存储结构
B.存储实现
C.逻辑结构
D.运算实现
数据的逻辑结构跟其相对位置无关
通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着( )。
(1分)
A.数据在同一范围内取值
B.不仅数据元素所包含的数据项的个数要相同,而且对应数据项的类型要一致
C.每个数据元素都一样
D.数据元素所包含的数据项的个数要相等
以下数据结构中,( )是非线性数据结构。
(1分)
A.树
B.字符串
C.队列
D.栈
求整数n(n>=0)的阶乘的算法如下,其时间复杂度为( )。
long fact(long n)
if (n<=1) return 1;
return n*fact(n-1);
A.Θ(log2^n)
B.Θ(n^2 )
C.Θ(n)
D.Θ(nlog2^n)
显然递归n次
流程图是描述算法的很好的工具,一般的流程图中由几种基本图形组成。其中判断框的图形是
(1分)
A.菱形
B.长方形
C.平行四边形
D.椭圆型
For the following function (where n>0)
int func ( int n )
int i = 1, sum = 0;
while ( sum < n ) sum += i; i *= 2;
return i;
A.O(logn)
B.O(n)
C.O(nlogn)
D.O(2^n)
因为有个i*=2
Suppose A is an array of length N with some random numbers. What is the time complexity of the following program in the worst case?
void function( int A[], int N )
int i, j = 0, cnt = 0;
for (i = 0; i < N; ++i)
for (; j < N && A[j] <= A[i]; ++j);
cnt += j - i;
A.O(N^2)
B.O(NlogN)
C.O(N)
D.O(N^1.5 )
别漏掉第二个循环后面的;哦
在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是:
(2分)
A.问第i个结点(1≤i≤N)和求第i个结点的直接前驱(2≤i≤N)
B.在第i个结点后插入一个新结点(1≤i≤N)
C.删除第i个结点(1≤i≤N)
D.将N个结点从小到大排序
注意是顺序表
若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用哪种存储方式最节省时间?
A.双链表
B.单循环链表
C.带头结点的双循环链表
D.顺序表
注意是在最后进行插入和删除
顺序表中第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是( )。
A.100
B.105
C.108
D.110
已知二维数组 A 按行优先方式存储,每个元素占用 1 个存储单元。若元素 A[0][0] 的存储地址是 100,A[3][3] 的存储地址是 220,则元素 A[5][5] 的存储地址是:
A.295
B.300
C.301
D.306
220 - 4 = 216
从100 ~ 216 一共3行,每行39个元素
5*39+6+99 = 300
线性表若采用链式存储结构时,要求内存中可用存储单元的地址
A.必须是连续的
B.连续或不连续都可以
C.部分地址必须是连续的
D.一定是不连续的
将线性表La和Lb头尾连接,要求时间复杂度为O(1),且占用辅助空间尽量小。应该使用哪种结构? (2)
A. 单链表
B. 单循环链表
C. 带尾指针的单循环链表
D. 带头结点的双循环链表
需要一个尾指针将后面那个节点连起来
对于一个具有N个结点的单链表,在给定值为x的结点后插入一个新结点的时间复杂度为
(2分)
A.O(1)
B.O(N/2)
C.O(N)
D.O(N 2 )
要先找到这个元素,然后再进行插入
将两个结点数都为N且都从小到大有序的单向链表合并成一个从小到大有序的单向链表,那么可能的最少比较次数是:
(2分)
A.1
B.N
C.2N
D.NlogN
理想情况是某个链表的所有节点都比另一个链表的第一个节点小
已知表头元素为c的单链表在内存中的存储状态如下表所示:

现将f存放于1014H处,并插入到单链表中,若f在逻辑上位于a和e之间,则a、e、f的“链接地址”依次是:(2分)
A.1010H, 1014H, 1004H
B.1010H, 1004H, 1014H
C.1014H, 1010H, 1004H
D.1014H, 1004H, 1010H
a要链接f的地址,e链接的地址不变,f链接到e的地址
多选题
非空线性表的结构特征
非空线性表具有哪些结构特征?
A.只有唯一的开始结点和唯一的终端结点
B.可拥有多个的开始结点和多个终端结
C.除开始结点外,每个结点只有一个前驱结点
D.除终端结点外,每个结点只有一个后继结点
链表 - 时间复杂度
在包含n个数据元素的链表中,▁▁▁▁▁ 的时间复杂度为 $$O(n)$$。
A.访问第 $$i$$ 个数据元素
B.在第 $$i \\ (1 \\leq i \\leq n)$$ 个结点后插入一个新结点
C.删除第 $$i \\ (1 \\leq i \\leq n)$$ 个结点
D.将 $$n$$ 个元素按升序排序
栈和队列
判断题
序列1,2,3,4,5依次入栈,则不可能得到3,4,1,2,5的出栈序列
T
1不可能在2之前出栈
两个栈共享一片连续空间,可以将两个栈的栈底分别设在这片空间的两端
T
Non recursive programs are generally faster than equivalent recursive programs. However, recursive programs are in general much simpler and easier to understand.
T
"Circular Queue" is defined to be a queue implemented by a circularly linked list or a circular array.
F
循环队列是抽象数据类型,不局限于其实现的方式
单选题
现有队列 Q 与栈 S,初始时 Q 中的元素依次是 1, 2, 3, 4, 5, 6 (1在队头),S 为空。若允许下列3种操作:(1)出队并输出出队元素;(2)出队并将出队元素入栈;(3)出栈并输出出栈元素,则不能得到的输出序列是:
A.1, 2, 5, 6, 4, 3
B.2, 3, 4, 5, 6, 1
C.3, 4, 5, 6, 1, 2
D.6, 5, 4, 3, 2, 1
A的操作是1122223333
B的操作是2111113
C的操作是221111 2应该在1的前面
D就是先全部入栈,然后全部输出
循环队列的引入,目的是为了克服( )。
(1分)
A.假溢出问题
B.真溢出问题
C.空间不够用
D.操作不方便
循环队列的队满条件为 ( )。(2分)
A.(sq.rear+1) % maxsize ==(sq.front+1) % maxsize
B.(sq.front+1) % maxsize ==sq.rear
C.(sq.rear+1) % maxsize ==sq.front
D.sq.rear ==sq.front

可以发现满的时候其实还有一个位置空着
若采用带头、尾指针的单向链表表示一个堆栈,那么该堆栈的栈顶指针top应该如何设置?
(2分)
A.将链表头设为top
B.将链表尾设为top
C.随便哪端作为top都可以
D.链表头、尾都不适合作为top
概念题
设有一顺序栈S,元素s1,s2,s3,s4,s5,s6依次进栈,如果6个元素出栈的顺序是s2,s3,s4, s6 , s5,s1,则栈的容量至少应该是( )。
(2分)
A.2
B.3
C.5
D.6
栈中最多只会有3个元素
线性表
判断题
线性表中的所有数据元素的数据类型必须相同
T
KMP算法的特点是在模式匹配时指示主串的指针不会变小回溯。
T
关于非空线性表的前驱结点
非空线性表中每个结点都有一个前驱结点。
F
头结点没有前驱结点
关于非空线性表的开始结点
非空线性表可以有多个开始结点。
F
只能有一个开始结点
单选题
给定程序时间复杂度的递推公式:T(1)=1,T(N)=2T(N/2)+N。则对该程序时间复杂度最接近的描述是:
A.O(logN)
B.O(N)
C.O(NlogN)
D.O(N^2)
利用数学进行递推
T(N) = 2T(N/2) + N = 2 * 2 * T(N/4) + 2*N = ..... = 2^x * T(1) + x * N
其中x = log2N 所以原式子是N + NlogN
渐进时间复杂度是C
KMP算法下,长为n的字符串匹配长度为m的字串的时间复杂度为
(2分)
A.O(N)
B.O(M+N)
C.O(M+LOGN)
D.O(N+LOGM)
if ( A > B )
for ( i=0; i<N; i++ )
for ( j=N*N; j>i; j-- )
A += B;
else
for ( i=0; i<N*2; i++ )
for ( j=N*2; j>i; j-- )
A += B;
时间复杂度是
A.O(N)
B.O(N^2 )
C.O(N^3 )
D.O(N^4 )
多选题
以下说法正确的是。
(2分)
A.求表长、定位这两种运算在采用顺序存储结构时实现的效率不比采用链式存储结构时实现的效率低
B.顺序存储的线性表可以随机存取
C.由于顺序存储要求连续的存储区域,所以在存储管理上不够灵活
D.线性表的链式存储结构优于顺序存储结构
串,数组和广义表
判断题
假设模式串是abababaab,则KMP模式匹配算法中的next[j] = 0 1 1 2 3 4 5 6 2
T
想到这道题,我是真的无语
我发现书上写的和在算法竞赛里的next数组定义是不一样的
而且书上的相当复杂,关键是PTA就是用的书上的内容
书上下标如果从0开始,
那么j=1时,就是-1,后面就是相等前后缀的大小,关键是next[j]指的是j前面的最大相等前后缀,也就是0~j-1
这样的话就是-1 0 0 1 2 3 4 5 1
如果下标从1开始,那么每一个next都要向后移一位
算法竞赛当中,next[j]指的就是从1~j的最大相等前后缀
其实两者都能解决问题,但是书上定义的比较复杂
单选题
设主串 T = abaabaabcabaabc,模式串 S = abaabc,采用 KMP 算法进行模式匹配,到匹配成功时为止,在匹配过程中进行的单个字符间的比较次数是:
A.9
B.10
C.12
D.15
i
a b a a b a a b c a b a a b c
a b a a b c
j
到此为止是6次,然后j回溯
i
a b a a b a a b c a b a a b c
a b a a b c
j
之后再比较4次
总共10次
设广义表L=((a,b,c)),则L的长度和深度分别为( )(2分)
A.1和1
B.1和3
C.1和2
D.2和3
由于在广义表方面个人掌握的不是特别好,所以就多说一些
广义表,又称列表,也是一种线性存储结构。
同数组类似,广义表中既可以存储不可再分的元素,也可以存储广义表,记作:
LS = (a1,a2,…,an)
其中,LS 代表广义表的名称,an 表示广义表存储的数据。广义表中每个 ai 既可以代表单个元素,也可以代表另一个广义表。
原子和子表
通常,广义表中存储的单个元素称为 "原子",而存储的广义表称为 "子表"。
例如创建一个广义表 LS = 1,1,2,3,我们可以这样解释此广义表的构成:广义表 LS 存储了一个原子 1 和子表 1,2,3。
以下是广义表存储数据的一些常用形式:
A = ():A 表示一个广义表,只不过表是空的。
B = (e):广义表 B 中只有一个原子 e。
C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
注意,A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
广义表的表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS=1,1,2,3,5 中,表头为原子 1,表尾为子表 1,2,3 和原子 5 构成的广义表,即 1,2,3,5。
再比如,在广义表 LS = 1 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 表示。
长度
广义表的长度就是看第一层所含的元素个数
深度
广义表的深度是max(每个元素深度) + 1
A=():A是一个空表,长度为0,深度为1
B=(e):B只有一个原子e,B的长度为1,深度为1
C=(a,(b,c,d)):C的长度为2,深度为2
D=(A,B,C)=((),(e),(a,(b,c,d))):D的长度为3,深度为3
E=(a,E):E是一个递归的表,长度为2,深度无限。
广义表((a,b,c,d))的表头、表尾是( )。
(2分)
A.表头:a 表尾:(b,c,d)
B.表头: ( ) 表尾:(a,b,c,d)
C.表头:(a,b,c,d) 表尾:( )
D.表头:(b,c,d) 表尾:(a)
对n阶对称矩阵压缩存储时,需要表长为( )的顺序表。
(2分)
A.n/2
B.n×n/2
C.n(n+1)/2
D.n(n-1)/2
由于矩阵是对称的,所以只需要储存1+2+3+....+n = n(n+1)/2
有一个n×n的对称矩阵A,将其下三角部分按行存放在一维数组B中,而A[0][0]存放于B[0]中,则第i行的对角元素A[i][i]存放于B中的( )处。
(2分)
A.(i+3)i/2
B.(i+1)i/2
C.(2n-i+1)i/2
D.(2n-i-1)i/2
[i][i]前面有i行,一共有1+2+....+i个元素,然后第i行第i个
总共是(1+i)i/2 + i + 1,由于下标从B[0]开始,刚开始算的时候是算了B[0]的
所以还要-1就是(i+3)i/
二维数组 A 的每个元素是由 10 个字符组成的串,其行下标 i=0,1,…,8,列下标 j=1,2,…,10。若 A 按行序优先存储,元素 A[8,5] 的起始地址与当 A 按列序优先存储时的元素( )的起始地址相同。设每个字符占一个字节。
A.A[8,5]
B.A[3,10]
C.A[5,8]
D.A[0,9]
行序优先就是横着存,列序优先就是竖着存,
行序优先是[8,5]那么这是810+5个元素;
对应的列序优先存储是99+4
也就是A[3,10]
对于 C 语言的二维数组 int A[m][n],每个元素占 2 个字节,数组中元素 a[i,j]的存储位置可由( )式确定。
(2分)
A.Loc[i, j]=A[m, n]+(n×i + j )×2
B.Loc[i, j]=Loc[0, 0]+[ (m+n)×i+j ]×2
C.Loc[i, j]=Loc[0, 0]+ (n×i+j)×2
D.Loc[i, j]= (n×i+j)×2
数组 A[0..5, 0..6] 的每个元素占 5 个字节,将其按列优先次序存储在起始地址为 1000 的内存单元中,则元素 A[5, 5] 的地址是( )。(2分)
A.1175
B.1180
C.1205
D.1210
(5*6+5 ) *5 = 175
这里指的是存储的起始地址
稀疏矩阵一般的压缩存储方式有两种,即()。(2)
A. 二维数组和三维数组
B. 三元组和散列
C. 三元组和十字链表
D. 替换为错散列和十字链表误项
设二维数组A[1… m,1… n]按行存储在数组B中,则二维数组元素A[i,j]在一维数组B[1…m*n]中的下标为 ( )。(分)
A.n(i-1)+j
**B.n(i-1)+j-1**
C.i(j-1)
D.jm+i-1
这个题也是第二个我感到有点问题的题,按照道理来讲应该选A的,但是答案选B
比如A[1][1]理论上应该在B[1]的,但是按照公式计算就是B[0]了
评论区如果有知道的小伙伴欢迎指出
带行表的三元组表是稀疏矩阵的一种( )(2)
A. 顺序存储结构
B. 链式存储结构
C. 索引存储结构
D. 散列存储结构
广义表与稀疏矩阵都是线性表的扩展,它们的共同点为()。(2分)
A.都可以用链接结构与顺序结构存储
B.无共同点
C.都是递归结构
D.数据元素本身是一个数据结构
填空题
若串S=‘software’,其子串的数目是37
子串为单个字符有8个,2个字符有7个。。。。
一共是1+2+3+...8 = 36
由于空串也是子串,所以一共有37个子串
根据KMP算法,模式串p="abaabcac"各字符对应的失配值分别是
-1 0 0 1 1 2 0 1
这里根据书上,下标从0开始
设目标串text=“abccdcdccbaa”,模式串pattern=“cdcc”,若采用BF(Brute Force)算法,则在第6趟匹配成功。
若n为主串长度,m为模式串长度,采用BF(Brute Force)模式匹配算法,在最坏情况下需要的字符比较次数为(n-m+1)m
设二维数组a[10][20],每个数组元素占用1个存储单元,若按列优先顺序存放数组元素,a[0][0]的存储地址为200,则a[6][2]的存储地址是多少?
226
这题我其实也没搞明白
按照列优先存储,应该是 2*11+7+199 = 228才对
但是答案是226,评论区有知道的小伙伴欢迎留言
稀疏矩阵,即包含大量值为 0 的矩阵,此类矩阵的一种存储方法是将矩阵中所有非 0 元素所在的位置(行标和列标)和元素值存储在顺序表(数组)中,通过存储由所有非 0 元素的三元组构成的顺序表,以及该稀疏矩阵的行数和列数,即可完成对整个稀疏矩阵的存储,这就是稀疏矩阵使用三元组表示的实现思想。
因此,每个非 0 元素的三元组需要使用结构体进行自定义:
//三元组结构体
typedef struct
int i,j;//行标i,列标j
int data;//元素值
triple;
有一个100×90的稀疏矩阵,非0元素有10,设每个整型数占2个字节,则用三元组表示该矩阵时,所需的字节数是
66
将非零元素所在行、列、非零元素的值构成一个三元组(i,j,v) ;
对于该题:
每个非零元素占3 * 2 =6个字节,共10个非零元素,需610 = 60 个字节;
此外,还一般要用三个整数来存储矩阵的行数、列数和总元素个数,又需要32 = 6个字节;
总共:60 + 6 = 66 个字节。
树与二叉树
判断题
某二叉树的前序和中序遍历序列正好一样,则该二叉树中的任何结点一定都无右孩子。
F
前序是根左右,中序是左根右
应该是任何结点一定都没有左孩子
存在一棵总共有2016个结点的二叉树,其中有16个结点只有一个孩子
F
根据公式n0 = n2 + 1;
2016 - 16 = 2000 = 2n2 + 1;
显然n2算出来是小数,所以不存在
关于哈夫曼树
哈夫曼树中一定没有度为 1 的结点。
T
哈夫曼树的两个性质
- 哈夫曼树中只有度为0和度为2的结点
- n2 = n0 - 1
非空二叉树的形态
一棵非空二叉树,若先序遍历与后序遍历的序列相反,则该二叉树只有一个叶子结点。
T
已知一棵二叉树的先序遍历结果是ABC,则CAB不可能是中序遍历结果。
T
分情况举例讨论
对于一个有N个结点、K条边的森林,不能确定它共有几棵树
F
对一棵有N个结点的树来说,显然有N-1条边
所以一共有N-K棵树
哈夫曼编码是一种最优的前缀码。对一个给定的字符集及其字符频率,其哈夫曼编码不一定是唯一的,但是每个字符的哈夫曼码的长度一定是唯一的。
F
哈夫曼每个字符的频率相同时,码长并不确定
单选题
设每个d叉树的结点有d个指针指向子树,有n个结点的d叉树有多少空链域?
(1分)
A.nd
B.n(d−1)
C.n(d−1)+1
D.以上都不是
这里我们可以直接列举一个例子,假设n = 3,d = 2
显然空链域为4
这里只有C选项符合要求
某二叉树的中序序列和后序序列正好相反,则该二叉树一定是
(2分)
A.空或只有一个结点
B.高度等于其结点数
C.任一结点无左孩子
D.任一结点无右孩子
某二叉树的前序和后序遍历序列正好相反,则该二叉树一定是
(1分)
A.空或只有一个结点
B.高度等于其结点数
C.任一结点无左孩子
D.任一结点无右孩子
如果A和B都是二叉树的叶结点,那么下面判断中哪个是对的?(3分)
A.存在一种二叉树结构,其前序遍历结果是…A…B…,而中序遍历结果是…B…A…
B.存在一种二叉树结构,其中序遍历结果是…A…B…,而后序遍历结果是…B…A…
C.存在一种二叉树结构,其前序遍历结果是…A…B…,而后序遍历结果是…B…A…
D.以上三种都是错的
先序中序后序是根据根结点而言的,叶子结点的相对顺序保持不变
已知一棵完全二叉树的第6层(设根为第1层)有8个叶结点,则该完全二叉树的结点个数最多是:
(3分)
A.39
B.52
C.111
D.119
第六层有8个叶节点,所以第六层也是满的。
假如第7层也满了。那么总共有2^7-1个结点,也就是127个结点
由于8个结点没有衍生出多余的16个结点
所以127-16 = 111
具有65个结点的完全二叉树其深度为(根的深度为1):(3分)
A.8
B.7
C.6
D.5
由于65 = 64 - 1 + 3;
64 = 2 ^ 6;
所以一共6+1=7层
补充知识:线索二叉树
对于一个有n个结点的二叉链表,每个节点都有指向左右孩子的两个指针域,一共有2n个指针域。而n个结点的二叉树又有n-1条分支线数(除了头结点,每一条分支都指向一个结点),也就是存在2n-(n-1)=n+1个空指针域。这些指针域只是白白的浪费空间。因此, 可以用空链域来存放结点的前驱和后继。线索二叉树就是利用n+1个空链域来存放结点的前驱和后继结点的信息。

如图以中序二叉树为例,我们可以把这颗二叉树中所有空指针域的lchild,改为指向当前结点的前驱(灰色箭头),把空指针域中的rchild,改为指向结点的后继(绿色箭头)。我们把指向前驱和后继的指针叫做线索 ,加上线索的二叉树就称之为线索二叉树。
设森林F中有三棵树,第一、第二、第三棵树的结点个数分别为M1 ,M2和M3。则与森林F对应的二叉树根结点的右子树上的结点个数是:(2分)
A.M1
B.M1+M2
C.M2+M3
D.M3
森林转化为二叉树,兄弟关系向右斜
对N(N≥2)个权值均不相同的字符构造哈夫曼树。下列关于该哈夫曼树的叙述中,错误的是:(2分)
A.树中一定没有度为1的结点
B.树中两个权值最小的结点一定是兄弟结点
C.树中任一非叶结点的权值一定不小于下一层任一结点的权值
D.该树一定是一棵完全二叉树
哈夫曼树不一定是完全二叉树
设一段文本中包含字符a, b, c, d, e,其出现频率相应为3, 2, 5, 1, 1。则经过哈夫曼编码后,文本所占字节数为:(2分)
A.40
B.36
C.25
D.12
画出哈夫曼树以后求出他的带权路径长度为4 * 1 + 41 + 23+3*2+5 = 25
哈夫曼树补充知识:

设一段文本中包含4个对象a,b,c,d,其出现次数相应为4,2,5,1,则该段文本的哈夫曼编码比采用等长方式的编码节省了多少位数?
A.0
B.2
C.4
D.5
等长方式编码是什么
等长编码要两位(因为有4个对象)(00 01 10 11)再乘相应次数 = 等长编码的总位数
所以等长编码 = 2 * (4+2+5+1) = 24
画出哈夫曼树,带权路径长度为22
所以节约了2位数
具有1102个结点的完全二叉树一定有__个叶子结点。
(3分)
A.79
B.551
C.1063
D.不确定
完全二叉树的定义:二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的节点都连续集中在最左边~
所以完全二叉树度为1的结点要么是0,要么是1
根据n0 = n2 + 1
计算可得度为1的结点是1;
所以n0 = 551;
下面的函数PreOrderPrintLeaves(BinTree BT)按前序遍历的顺序打印出二叉树BT的所有叶子结点。则下列哪条表达式应被填在空中?
void PreOrderPrintLeaves( BinTree BT )
if (BT)
if (___________________) printf(" %d", BT->Data);
PreOrderPrintLeaves( BT->Left );
PreOrderPrintLeaves( BT->Right );
A.BT->Data != 0
B.!BT->Right
C.!BT->Left
D.!(BT->Left || BT->Right)
二叉树的高度
若根节点为高度1,一棵具有 1025 个结点的二叉树的高度为 ▁▁▁▁▁ 。
(1分)
A.10
B.11
C.11~1025 之间
D.10~1024 之间
已知字符集 a, b, c, d, e, f ,若各字符出现的次数分别为 6, 3, 8, 2, 10, 4 ,则对应字符集中各字符的哈夫曼编码可能是:(3分)
A.00, 1011, 01, 1010, 11, 100
B.00, 100, 110, 000, 0010, 01
C.10, 1011, 11, 0011, 00, 010
D.0011, 10, 11, 0010, 01, 000
随便构建一棵哈夫曼树,显然只有b,d位于第四层,所以需要四位(xxxx)表示,并且bd的前三位(XXXx)应相同,而BCD选项中,bd的哈夫曼编码前三不同,所以排除BCD。固选A
若将一棵树 T 转化为对应的二叉树 BT,则下列对 BT 的遍历中,其遍历序列与 T 的后根遍历序列相同的是:(2分)
A.先序遍历
B.中序遍历
C.后序遍历
D.按层遍历
对 n 个互不相同的符号进行哈夫曼编码。若生成的哈夫曼树共有 115 个结点,则 n 的值是:
(3分)
A.56
B.57
C.58
D.60
由于哈夫曼树只有度为0和度为2的结点,115 = n2 + n2 + 1, n2 = 57,n0 = 58
二叉链表复习
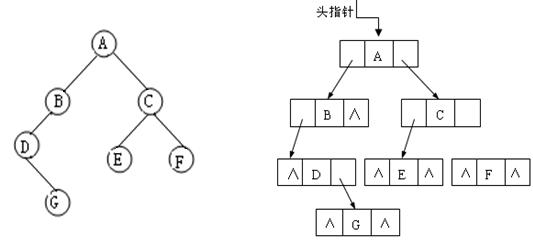
以二叉链表作为二叉树的存储结构,在具有 n 个结点的二叉链表中(n>0),空链域的个数为 __(1分)
A.n+1
B.n
C.n−1
D.无法确定
每个结点都会对应一个头指针,除了父节点,所以一共有N-1个非空链域,
一共有2N个链域,空链域是2N-N+1 = N+1
对于任意一棵高度为 5 且有 10 个结点的二叉树,若采用顺序存储结构保存,每个结点占 1 个存储单元(仅存放结点的数据信息),则存放该二叉树需要的存储单元的数量至少是:
(2分)
A.31
B.16
C.15
D.10
二叉树的储存要先按满二叉树分配即2^k-1个存储单元
一棵度为4的树T中,若有20个度为4的结点,10个度为3的结点,1个度为2的结点,10个度为1的结点,则树T的叶子结点个数是( )。(2分)
A.41
B.82
C.113
D.122
和常规的公式推导一样,n = n4+n3+n2+n1+n0 = 4n4+3n3+2n2+n1+1
所以n0 = 3n4+2n3+n2+1 = 82
若某二叉树有 5 个叶结点,其权值分别为 10、12、16、21、30,则其最小的带权路径长度(WPL)是:
(1分)
A.89
B.200
C.208
D.289
这道题说白了也是求其哈夫曼树
多选题
以下说法错误的是( )。(2分)
A.哈夫曼树是带权路径长度最短的树,路径上权值较大的结点离根较近。
B.若一个二叉树的树叶是某子树的中序遍历序列中的第一个结点,则它必是该子树的后序遍历序列中的第一个结点
C.已知二叉树的前序遍历和后序遍历序列并不能唯一确定这棵树,因为不知道树的根结点是哪一个。
D.在前序遍历二叉树的序列中,任何结点的子树的所有结点都是直接跟在该结点之后。
图
判断题
无向连通图所有顶点的度之和为偶数。
T
每条边既是出度又是入度
无向连通图边数一定大于顶点个数减1。
F
成环就相等了
在任一有向图中,所有顶点的入度之和等于所有顶点的出度之和。
T
如果无向图G必须进行两次广度优先搜索才能访问其所有顶点,则G中一定有回路。
F
一定有两个连通分量
若图G为连通图且不存在拓扑排序序列,则图G必有环。
T
拓扑序列和有环是充分必要条件
P 是顶点 S 到 T 的最短路径,如果该图中的所有路径的权值都加 1,P 仍然是 S 到 T 的最短路径。
F
单选题
若无向图 G = (V, E) 中含 7 个顶点,则保证图 G 在任何连边方式下都是连通的,则需要的边数最少是( )
A.6
B.15
C.16
D.21

如图,6条边不一定能使其连通,如果要让7个顶点连通,首先要让六个顶点完全连通,也就是说需要6*5/2条边让6个顶点完全连通,然后还剩下一条边连第7个顶点
所以一共需要16条边
具有5个顶点的有向完全图有多少条弧?(2分)
A.10
B.16
C.20
D.25
注:任意两个顶点之间都有两条弧
如果G是一个有15条边的非连通无向图,那么该图顶点个数最少为多少?
(3分)
A.7
B.8
C.9
D.10
首先顶点个数要尽可能少,那么就要用尽可能少的顶点数凑够15条边
最少要6个顶点凑够,因为不能连通,所以至少需要6+1个顶点
具有 100 个顶点和 12 条边的无向图至多有多少个连通分量?(2分)
A.87
B.88
C.94
D.95
要让连通分量尽可能地多,我们就要分配尽可能多地顶点,每个顶点都可以作为一个连通分量
所以要尽快凑齐前面的12条边,需要6个顶点凑齐
还剩下94个顶点,成为94个连通分量,前面6个顶点单独作为一个连通分量
一共95个连通分量
AOE网知识补充:
- 求出到达各个状态的最早时间(按最大计)
这个过程是要从源点开始向汇点顺推 - 求出到达各个状态的最晚时间(按最小计)
这个过程是要从汇点开始向源点逆推
下图所示的 AOE 网表示一项包含 8 个活动的工程。活动 d 的最早开始时间和最迟开始时间分别是:
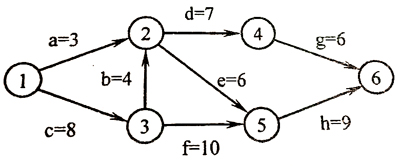
(2分)
A.3 和 7
B.12 和 12
C.12 和 14
D.15 和 15
最早时间对应是
8-3
12-2
19-4
18-5
27-6
对于活动d,2的最早时间是12
最迟时间从汇点向源点递推
所以27-6-7=14
查找
判断题
在散列表中,所谓同义词就是具有相同散列地址的两个元素
T
经典概念题
若用平方探测法解决冲突,则插入新元素时,若散列表容量为质数,插入就一定可以成功。
F
使用平方探测法如果该位置已经有数可能会插入失败
平方探测的整体流程
平方探测的整体流程和线性探测基本相似,但是线性探测是没有③:
①根据哈希函数算出Hashval,i 初始化为零,判断HashTable[Hashval]是否被占用,如果没被占用,则Hashval就是根据哈希函数算出的值,跳出平方探测;如果被占用则向右探测(执行②);
②判断HashTable[Hashval + i * i]是否被占用,如果没被占用,则Hashval = Hashval + i * i,跳出平方探测;如果被占用则向左探测(执行③);
③判断HashTable[Hashval - i * i]是否被占用,如果没被占用,则Hashval = Hashval - i * i,跳出平方探测;如果被占用则i++继续向右探测(执行②);
将M个元素存入用长度为S的数组表示的散列表,则该表的装填因子为M/S。
T
装填因子的概念
对包含N个元素的散列表进行查找,平均查找长度为:
(1分)
A.O(1)
B.O(logN)
C.O(N)
D.不确定
和这个散列表解决冲突的方式有关
设散列表的地址区间为[0,16],散列函数为H(Key)=Key%17。采用线性探测法处理冲突,并将关键字序列 26,25,72,38,8,18,59 依次存储到散列表中。元素59存放在散列表中的地址是:
(2分)
A.8
B.9
C.10
D.11
这里利用线性探测法,26%17 = 9,25%17 = 8,72 % 17 = 4,38 % 17 = 4,这里产生第一次冲突
所以38放到5这个位置,8产生第二次冲突,8放到10的位置
18%17 = 1,59 % 17 = 8,产生第三次冲突
所以59放到11的位置
将元素序列18,23,11,20,2,7,27,33,42,15按顺序插入一个初始为空的、大小为11的散列表中。散列函数为:H(Key)=Key%11,采用线性探测法处理冲突。问:当第一次发现有冲突时,散列表的装填因子大约是多少?
(2分)
A.0.27
B.0.45
C.0.64
D.0.73
注意这里是第一次发生冲突时,所以
18%11 = 7,23 % 11 = 1,11 % 11 = 0,20 % 11 = 9,2 % 11 = 2,7 % 11 = 7(这里发生第一次冲突)
所以此时的装填因子是5/11 ~ 0.45
给定散列表大小为11,散列函数为H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的4个元素。问:此时该散列表的平均不成功查找次数是多少?
A.1
B.4/11
C.21/11
D.不确定
此题也是经典题
查找成功的平均查找长度 比较次数之和/元素个数
查找失败的平均查找长度 离空位的比较次数之和/模
0 1 2 3 4 5 .... 10
5 4 3 2 1 1 .... 1
所以5+4+3+2+1 + ... 1/11 = 21/11
每个空位还要单独计算一次
从一个具有N个结点的单链表中查找其值等于X的结点时,在查找成功的情况下,需平均比较多少个结点?
(2分)
A.N/2
B.N
C.(N−1)/2
D.(N+1)/2
1+2+3+。。。+n=n*(n+1)/2;因此是(n+1)/2
给定输入序列 4371, 1323, 6173, 4199, 4344, 9679, 1989 以及散列函数 h(X)=X%10。如果用大小为10的散列表,并且用分离链接法解决冲突,则输入各项经散列后在表中的下标为:(-1表示相应的插入无法成功)
(2分)
A.1, 3, 3, 9, 4, 9, 9
B.1, 3, 4, 9, 7, 5, -1
C.1, 3, 4, 9, 5, 0, 8
D.1, 3, 4, 9, 5, 0, 2
分离链接法补充:


给定输入序列 4371, 1323, 6173, 4199, 4344, 9679, 1989 以及散列函数 h(X)=X%10。如果用大小为10的散列表,并且用开放定址法以及一个二次散列函数h 2 (X)=7−(X%7)解决冲突,则输入各项经散列后在表中的下标为:(-1表示相应的插入无法成功)
(2分)
A.1, 3, 3, 9, 4, 9, 9
B.1, 3, 4, 9, 7, 5, -1
C.1, 3, 4, 9, 5, 0, 8
D.1, 3, 4, 9, 5, 0, 2
开放定址法如下图所示:

h2作为增量函数
若N个关键词被散列映射到同一个单元,并且用分离链接法解决冲突,则找到这N个关键词所用的比较次数为:
(2分)
A.N(N+1)/2
B.N(N−1)/2
C.N+1
D.N
找到第一个关键字用1次,第二个关键字用2次。。。
一共用1+2+3+...n = (1+n) * n / 2次
给定散列表大小为11,散列函数为H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的5个元素。问:此时该散列表的平均不成功查找次数是多少?
(2分)
A.26/11
B.5/11
C.1
D.不确定
和之前的做法一样,6+5+4+3+2+1+1+1+1+1+1/11 = 26/11;
现有长度为 7、初始为空的散列表HT,散列函数H(k)=k%7,用线性探测再散列法解决冲突。将关键字 22, 43, 15 依次插入到HT后,查找成功的平均查找长度是:
(2分)
A.1.5
B.1.6
C.2
D.3
这里计算查找成功,要注意是
22%7 = 1,43%7 = 1,15%7 = 1;
一共比较了1+2+3次,除以元素个数是6/3 = 2
设有一组关键字 92,81, 58,21,57,45,161,38,117 ,散列函数为 h(key)=key%13,采用下列双散列探测方法解决第 i 次冲突:h(key)=(h(key)+i×h 2 (key))%13,其中 h 2 (key)=(key%11)+1。试在 0 到 12 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为 __(2分)
A.1.6
B.1.56
C.1.44
D.1.33
这题我只能说,算的人都麻了好吧
92%13 = 1,比较一次
81%13 = 3,比较一次
58%13 = 6,比较一次
21%13 = 8, 比较一次
57%13 = 5,比较一次
45%13 = 6,产生冲突,h2(45) = 2
h(45) = 6+2=8,产生冲突
h(45) = 6+2*2 = 10,比较3次
161%13 = 5,产生冲突,h2(161) = 8
5+8%13 = 0;比较2次
38%13 = 12,比较一次
117%13 = 0,产生冲突,h2(117) = 8;
0+8 = 8,产生冲突
0+16%13 = 3,产生冲突
0+24%13 = 11,比较4次
一共比较了5+3+2+1+4 = 15;
15/9 = 1.6
已知一个长度为16的顺序表L,其元素按关键字有序排列。若采用二分查找法查找一个L中不存在的元素,则关键字的比较次数最多是:
A.4
B.5
C.6
D.7
二分查找最坏比较次数是log2N + 1
填空题
假定查找有序表A[1..12]中每个元素的概率相等,则进行二分查找时的平均查找长度为37/12
可以唯一的标识一个记录的关键字称为主关键字。
直接定址法法构造的哈希函数肯定不会发生冲突。
哈希表是通过将查找码按选定的
哈希函数和解决冲突的方法,把结点按查找码转换为地址进行存储的线性表。哈希方法的关键是
选择好的哈希函数和 处理冲突的方法。一个好的哈希函数其转换地址应尽可能均匀,而且函数运算应尽可能简单
。
排序
判断题
对N个记录进行归并排序,归并趟数的数量级是O(NlogN)
F
数量级是是O(logn);
要从50个键值中找出最大的3个值,选择排序比堆排序快。
T
在数据量较小的情况下,选择排序比堆排序要快一些
单选题
对N个记录进行归并排序,空间复杂度为:
(1分)
A.O(logN)
B.O(N)
C.O(NlogN)
D.O(N^2)
归并排序的空间复杂度是O(N);
对N个记录进行快速排序,在最坏的情况下,其时间复杂度是
(1分)
A.O(N)
B.O(NlogN)
C.O(N^2)
D.O(N^2logN)
快排的最坏时间复杂度是N^2
对于10个数的简单选择排序,最坏情况下需要交换元素的次数为:
(2分)
A.9
B.36
C.45
D.100
简单选择排序比较次数为O(N^2),移动次数为O(N);
将序列 2, 12, 16, 88, 5, 10, 34 排序。若前2趟排序的结果如下:
第1趟排序后:2, 12, 16, 10, 5, 34, 88
第2趟排序后:2, 5, 10, 12, 16, 34, 88
则可能的排序算法是:
(2分)
A.冒泡排序
B.归并排序
C.插入排序
D.快速排序
在内部排序时,若选择了归并排序而没有选择插入排序,则可能的理由是:
归并排序的程序代码更短
归并排序占用的空间更少
归并排序的运行效率更高
(2分)
A.仅 2
B.仅 3
C.仅 1、2
D.仅 1、3
对初始数据序列 8, 3, 9, 11, 2, 1, 4, 7, 5, 10, 6 进行希尔排序。若第一趟排序结果为( 1, 3, 7, 5, 2, 6, 4, 9, 11, 10, 8 ),第二趟排序结果为( 1, 2, 6, 4, 3, 7, 5, 8, 11, 10, 9 ),则两趟排序采用的增量(间隔)依次是:
(2分)
A.3, 1
B.3, 2
C.5, 2
D.5, 3
希尔排序具体做法参考之前写的博客,这里不再赘述
快速排序方法在( )情况下最不利于发挥其长处。
(2分)
A.要排序的数据量太大
B.要排序的数据中含有多个相同值
C.要排序的数据个数为奇数
D.要排序的数据已基本有序
设一组初始记录关键字序列(5,8,6,3,2),以第一个记录关键字5为基准进行一趟从大到小快速排序的结果为( )。
(2分)
A.2,3,5,8,6
B.2,3,5,6,8
C.3,2,5,8,6
D.3,2,5,8,6
对序列15,9,7,8,20,-1,4进行排序,进行一趟后数据的排列变为9,15,7,8,20,-1,4,则采用的是( )排序.
(2分)
A.选择
B.希尔
C.直接插入
D.冒泡
如果是选择排序,序列最后一定是最大或者最小的值,如果是希尔排序,那么序列变化一定是一组一组地变
如果是冒泡排序,最后一个数一定是最大最小值
综上只有直接插入排序符合要求
对同一待排序序列分别进行折半插入排序和直接插入排序, 两者之间可能的不同之处是____。
(2分)
A.排序的总趟数
B.元素的移动次数
C.使用辅助空间的数量
D.元素之间的比较次数
按排序过程中依据的原则分类,快速排序属于( )
(2分)
A.插入类的排序方法
B.选择类的排序方法
C.交换类的排序方法
D.归并类的排序方法
排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一“趟”。下列序列中,不可能是快速排序第二趟结果的是:
(2分)
A.5, 2, 16, 12, 28, 60, 32, 72
B.2, 16, 5, 28, 12, 60, 32, 72
C.2, 12, 16, 5, 28, 32, 72, 60
D.5, 2, 12, 28, 16, 32, 72, 60
以上就是PTA部分数据结构题目的答案和解析,有不正确的地方或者需要添加题解的地方欢迎在评论区指出
以上是关于PTA数据结构和答案解析的主要内容,如果未能解决你的问题,请参考以下文章