分布式事务--CAPBASE理论基础
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务--CAPBASE理论基础相关的知识,希望对你有一定的参考价值。
一、CAP
CAP是研究分布式的一个比较经典的理论。
CAP就是Consistency、Availability、Partition Tolerence的简称。
也就是一致性,可用性,分区容忍性。
1、一致性
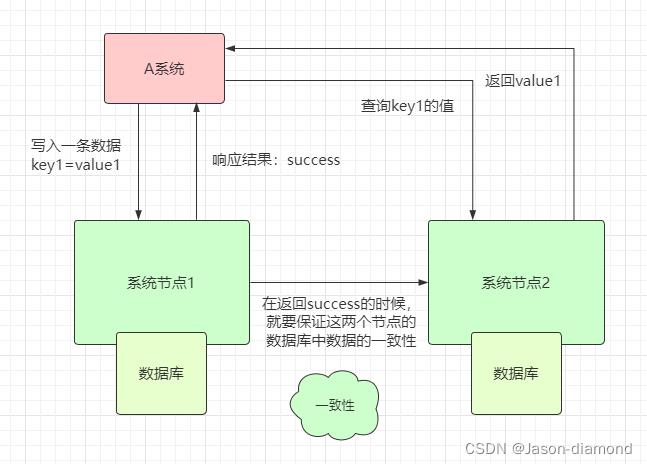
1.1、一致性分类:
1、强一致性:就是图中的那种。
2、弱一致性:节点数据如果同步了,你就能查到,没同步,就查不到,结果具有不确定性。
3、最终一致性:过一段时间,等节点之间数据同步之后,就可以查到。
2、可用性
客户端往分布式系统的各个节点发送请求,都是可以获取到响应的,写入、查询等操作都是成功的。
2.1、不可用:
客户端往分布式系统中的各个节点发送请求的时候,获取不到响应结果,那么系统就是不可用了。
2.2、可用性级别:
99%,一年中只能有80小时左右是可以允许访问失败的
99.9%,一年中大概有8小时左右是可以访问失败
99.99%,一年中有大概不到1小时是可以访问失败的
99.999%,一年中有大概不到5分钟是可以访问失败的
99.9999%,一年中只能有大概不到1分钟可以访问失败
很多行业大部分的系统,其实99%可用性都没到,每年总得故障几次。能做到99.9%的系统就算是比较牛的了,毕竟一年内就几个小时不可用。
3、分区容忍性
3.1、分区partition/network partition
网络分区 => 分布式系统之间的网络环境出了故障,分布式系统的各个节点之间现在已经无法进行通信了。
遇到网络分区故障,类似于脑裂,然后系统还是可以正常对外提供服务的。
3.2、不具备分区容忍性
一旦网络故障,整套系统崩溃,你哪怕给各个节点发送消息,全部失败,整套系统甚至会宕机。
4、CAP => CP or AP
一个分布式系统不可能同时兼备一致性、可用性、分区容忍性,要么是CP(一致性 + 分区容忍性),要么就是AP(可用性 + 分区容忍性)。
基于这套理论,redis、mongodb、hbase等分布式系统,都是参照着CAP理论来设计的,有些系统是CP,有些系统是AP。
5、保证CP
1、现在网络发生故障,client向节点A发送一个插入请求,节点A将数据插入。
2、节点A发现节点B之间网络不通了,无法进行数据同步。
3、client向节点B查询数据,由于当前节点之间网络不通,直接给client返回:当前系统处于不一致状态,不能查询。
这样就保证了一致性,不会让client看到不一致的状态,同时不能保证Available。
6、AP
同样的场景下,要保证两个节点都要可用的,所以client如果在节点A能够查询这条数据,但是如果请求到了节点B就查不到了。
6.1、场景:
电商、12306,这种业务类系统,一般都是AP。
查询的商品或者火车票库存可能都是旧数据,但是当你买的时候,肯定就是要查询库存,不影响使用。
二、BASE
Basicly Available、Soft State、Eventual Consistency,也就是基本可用、软状态、最终一致性。
1、基本可用:
- 正常情况下查询,负载均衡到各个节点去查的,多节点抗高并发,如果发生网络故障,可以选择降级。
- 如果流量太大了,直接返回一个空,让你稍后再来查询。
2、软状态:
多个节点都是可用的,但是可能一会能查到,一会就查不到了。
3、最终一致性:
一旦故障或者延迟解决了,数据过了一段时间最终一定是可以同步到其他节点的,数据最终一定是可以处于一致性的。
以上是关于分布式事务--CAPBASE理论基础的主要内容,如果未能解决你的问题,请参考以下文章