五大分布式场景解决方案
Posted 女友在高考
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五大分布式场景解决方案相关的知识,希望对你有一定的参考价值。
一、一致性Hash算法
Hash算法,散列函数,顾名思义,它是一个函数。如果把它定义成 hash(key) ,其中 key 表示元素的键值,则 hash(key) 的值表示经过散列函数计算得到的散列值。
常见的Hash算法如:MD5、SHA-1
Hash算法在分布式场景中的应用,主要分为两类:
- 请求的负载均衡
如nginx的ip_hash策略,可以让同一个客户端,每次都路由到同一个目标服务器,可以实现会话粘滞,避免处理session共享问题。
具体步骤就是使用hash算法根据ip计算hash值,然后根据目标服务器数量取模。
2. 分布式存储
以分布式存储redis集群为例,有redis1、redis2、redis3三台服务器,那么对某一个key进行存储呢?就需要针对key进行hash处理,index=hash(key)%3,使用index锁定存储服务器的具体节点。
普通Hash算法存在的问题
普通的Hash算法存在一个问题,以ip_hash为例,如果说后台有3台tomcat,tomcat2宕机了,那么hash(ip)%3变成了hash(ip)%2,这样就造成了所有的用户都需要重新计算。原本路由到tomcat1和tomcat3的那部分ip用户也会受影响。
一致性Hash算法
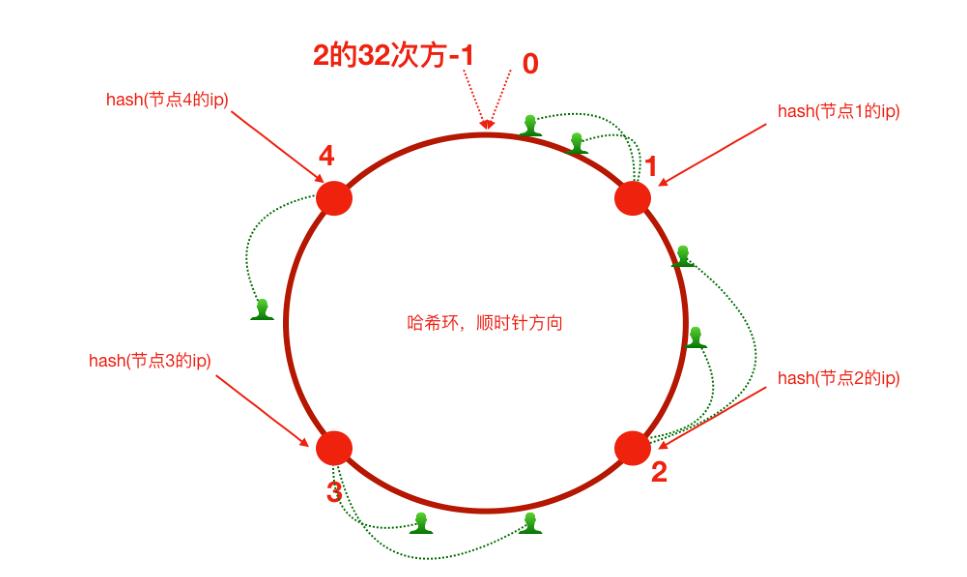
首先我们想象有一个环,这个环起始点是0,结束点是2的32次方-1。这样我们把服务器的ip求hash取得一个值,就能对应到环上某一个位置。针对客户端用户也是一样,根据客户端ip进行hash求值,也能对应到环上某一个位置,然后如何确定一个客户端路由到哪个服务器呢?
就按照顺时针放行找到最近的服务器节点。
如果还是上面的场景,3台tomcat应用,tomcat2宕机了。那么原来tomcat1和tomcat3的用户不会受影响,而原本应该落到tomat2上的应用会全部落到tomcat1或者tomcat3上。
那这个算法就没有问题了吗?
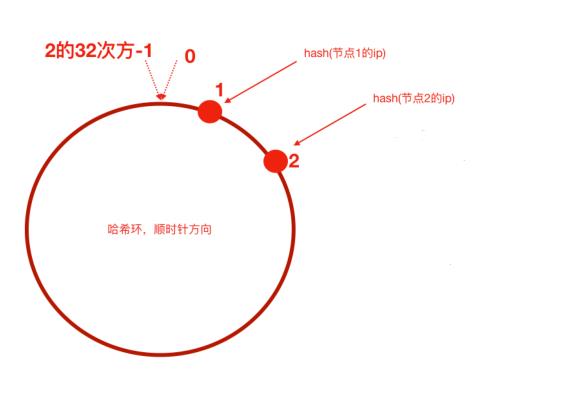
如果服务端节点比较少,如上图所示,那么就会出现数据倾斜问题,大量的请求会路由到节点1,只有少部分能路由到节点2.
为了解决这个问题,一致性hash算法引入了虚拟节点机制。可以对每个服务器节点计算多个hash。具体做法可以在每个服务器ip或主机名后面增加编号来实现。
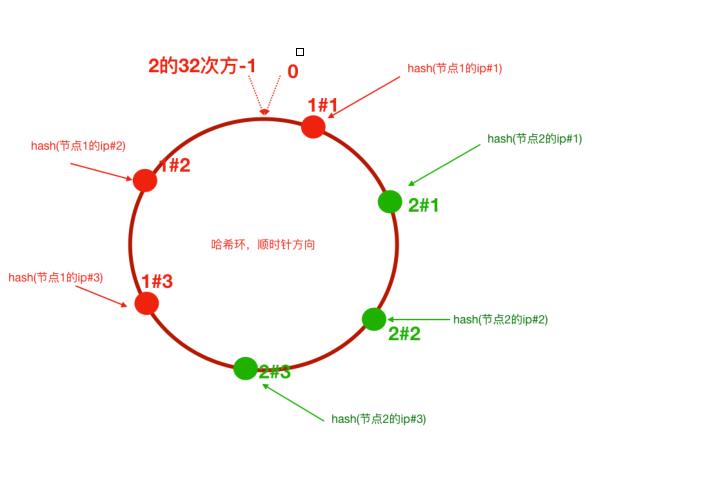
简易的一致性hash算法代码如下(仅供学习使用,不能用于生产):
/**
* ⼀致性Hash算法实现(含虚拟节点)
*/
public class ConsistentHashWithVirtual
public static void main(String[] args)
String[] clients=new String[]"10.177.2.1","10.192.2.1","10.98.45.4";
String[] tomcatServers = new String[]
"123.111.0.0","123.101.3.1","111.20.35.2","123.98.26.3";
//虚拟节点数
int virtualCount=20;
TreeMap<Integer,String> serverMap=new TreeMap<>();
for (String server:tomcatServers)
int serverHash = Math.abs(server.hashCode());
serverMap.put(serverHash,server);
for (int i = 0; i < virtualCount; i++)
int virtualHash=Math.abs((server+"#"+virtualCount).hashCode());
serverMap.put(virtualHash,"虚拟"+server);
for (String client:clients)
int clientHash = Math.abs(client.hashCode());
//获取一个子集。其所有对象的 key 的值大于等于 fromKey
SortedMap<Integer, String> sortedMap =serverMap.tailMap(clientHash);
if(sortedMap.isEmpty())
Integer firstKey = serverMap.firstKey();
String server = serverMap.get(firstKey);
System.out.println("客户端:"+client+" 路由到:"+server);
else
Integer firstKey = sortedMap.firstKey();
String server = sortedMap.get(firstKey);
System.out.println("客户端:"+client+" 路由到:"+server);
二、集群时钟同步
集群时钟不同步,指的是集群里各个服务器的时间不一致。因为系统时钟不一致,数据就会混乱。
集群时钟同步思路:
- 服务器都能联网的情况
使用linux的定时任务,每隔一段时间执行一次ntpdate命令同步时间。
#使⽤ ntpdate ⽹络时间同步命令
ntpdate -u ntp.api.bz #从⼀个时间服务器同步时间
如果ntpdate 命令不存在,可以用如下命令安装
yum install -y ntp
-
选取集群中的一个服务器节点A作为时间服务器(如果这台服务器能够访问互联网,可以让这台服务器和网络时间保持同步,如果不能就手动设置一个时间。)
2.1 设置好服务器A的时间
2.2 把服务器A配置为时间服务器(修改/etc/ntp.conf文件)1、如果有 restrict default ignore,注释掉它 2、添加如下⼏⾏内容 restrict 172.17.0.0 mask 255.255.255.0 nomodify notrap # 放开局 域⽹同步功能,172.17.0.0是你的局域⽹⽹段 server 127.127.1.0 # local clock fudge 127.127.1.0 stratum 10 3、重启⽣效并配置ntpd服务开机⾃启动 service ntpd restart chkconfig ntpd on2.2 集群中其他节点就可以从A服务器同步时间了
ntpdate 172.17.0.17
三、分布式ID
- 数据库方式
- redis方式
- UUID方式
- 雪花算法
雪花算法代码:
/**
* 官方推出,Scala编程语言来实现的
* Java前辈用Java语言实现了雪花算法
*/
public class IdWorker
//下面两个每个5位,加起来就是10位的工作机器id
private long workerId; //工作id
private long datacenterId; //数据id
//12位的序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence)
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0)
throw new IllegalArgumentException(String.format("worker Id can\'t be greater than %d or less than 0",maxWorkerId));
if (datacenterId > maxDatacenterId || datacenterId < 0)
throw new IllegalArgumentException(String.format("datacenter Id can\'t be greater than %d or less than 0",maxDatacenterId));
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作id需要左移的位数,12位
private long workerIdShift = sequenceBits;
//数据id需要左移位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳,初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId()
return workerId;
public long getDatacenterId()
return datacenterId;
public long getTimestamp()
return System.currentTimeMillis();
//下一个ID生成算法
public synchronized long nextId()
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp)
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
//获取当前时间戳如果等于上次时间戳
//说明:还处在同一毫秒内,则在序列号加1;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) // 0 - 4095
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0)
timestamp = tilNextMillis(lastTimestamp);
else
sequence = 0;
//将上次时间戳值刷新
lastTimestamp = timestamp;
/**
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp)
long timestamp = timeGen();
while (timestamp <= lastTimestamp)
timestamp = timeGen();
return timestamp;
//获取系统时间戳
private long timeGen()
return System.currentTimeMillis();
public static void main(String[] args)
IdWorker worker = new IdWorker(21,10,0);
for (int i = 0; i < 100; i++)
System.out.println(worker.nextId());
关于分布式ID的更多详细内容,可以看我的另一篇博客:分布式主键
四、分布式调度
调度,也就是我们所说的定时任务。定时任务的使用场景很多,如订单超时取消,定时备份数据等等。
那么分布式调度是什么意思呢?
有两层含义:
- 运行在分布式集群环境下的调度任务(同一个定时任务程序部署多份,只应该有一个定时任务在执行)
- 同一个大的定时任务可以拆分为多个小任务在多个机器上同时执行
在介绍分布式调度框架之前,我们先来回顾一下普通的定时任务框架Quartz.
任务调度框架Quartz回顾
- 引入pom依赖
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
- 代码编写
public class QuartzMain
public static void main(String[] args) throws SchedulerException
Scheduler scheduler = createScheduler();
JobDetail job = createJob();
Trigger trigger = createTrigger();
scheduler.scheduleJob(job,trigger);
scheduler.start();
/**
* 创建任务调度器
*/
public static Scheduler createScheduler() throws SchedulerException
SchedulerFactory schedulerFactory=new StdSchedulerFactory();
return schedulerFactory.getScheduler();
/**
* 创建一个任务
* @return
*/
public static JobDetail createJob()
JobBuilder jobBuilder=JobBuilder.newJob(DemoJob.class);
jobBuilder.withIdentity("jobName","myJob");
return jobBuilder.build();
/**
* 创建一个作业任务时间触发器
* @return
*/
public static Trigger createTrigger()
CronTrigger trigger=TriggerBuilder.newTrigger()
.withIdentity("triggerName","myTrigger")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?")).build();
return trigger;
public class DemoJob implements Job
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException
System.out.println("任务执行");
System.out.println(new Date().toLocaleString());
System.out.println(Thread.currentThread().getName());
try
Thread.sleep(30000);
catch (InterruptedException e)
e.printStackTrace();
分布式调度框架Elastic-Job
Elastic-Job介绍
Elastic-Job是当当网开源的一个分布式调度解决方案,是基于Quartz二次开发的,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。我们要学习的是 Elastic-Job-Lite,它定位为轻量级⽆中⼼
化解决⽅案,使⽤Jar包的形式提供分布式任务的协调服务,⽽Elastic-Job-Cloud⼦项⽬需要结合Mesos以及Docker在云环境下使⽤
Elastic-Job的github地址:https://github.com/elasticjob
主要功能介绍:
- 分布式调度协调
在分布式环境中,任务能够按照指定的调度策略执行,并且能够避免同一个任务多实例的重复执行。
- 丰富的调度策略
- 弹性扩容缩容
当集群中增加一个实例,塔应当也能够被选举并执行任务;当集群中减少一个实例时,它所执行的任务能被转移到别的实例来执行。
- 失效转移
某实例在任务执行失败后,会被转移到其他实例执行
- 错过执行作业重触发
若因某种原因导致作业错过执行,自动记录错过执行的作业,并在上次作业完成后自动触发。
- 支持并行调度
支持任务分片,任务分片是指将一个任务分为多个小任务在多个实例中执行
- 作业分片一致性
当任务被分片后,保证同一分片在分布式环境中仅一个执行实例
Elastic-Job-Lite应用
Elastic-Job依赖于Zookeeper进行分布式协调,需要安装Zookeeper软件(3.4.6版本以上)。
引入pom
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
- 只有一个分片任务的场景
public class ElasticJobMain
public static void main(String[] args) throws SQLException
ZookeeperConfiguration zookeeperConfiguration=new ZookeeperConfiguration("localhost:2181","data-archive-job");
CoordinatorRegistryCenter coordinatorRegistryCenter=new ZookeeperRegistryCenter(zookeeperConfiguration);
coordinatorRegistryCenter.init();
//shardingTotalCount设置为1时,启动多个实例,只能有一个实例执行
JobCoreConfiguration jobCoreConfiguration=JobCoreConfiguration.newBuilder("jobName",
"0/2 * * * * ?",1).build();
SimpleJobConfiguration simpleJobConfiguration=new SimpleJobConfiguration(jobCoreConfiguration,BackupJob.class.getName());
JobScheduler jobScheduler = new JobScheduler(coordinatorRegistryCenter, LiteJobConfiguration.newBuilder(simpleJobConfiguration).build());
jobScheduler.init();
public class BackupJob implements SimpleJob
@Override
public void execute(ShardingContext shardingContext)
String sql="select * from t_order limit 1";
try
List<Map<String, Object>> list = JdbcUtils.executeQuery(InitData.dataSource, sql);
if(!list.isEmpty())
Map<String, Object> objectMap = list.get(0);
System.out.println(objectMap);
String insertSql="insert into t_order_bak (id,code,amt,create_time,user_id) values(?,?,?,?,?)";
Collection<Object> values = objectMap.values();
List<Object> params=new ArrayList<>();
params.addAll(values);
JdbcUtils.execute(InitData.dataSource,insertSql,params);
//删除原来的
String deleteSql="delete from t_order where id=?";
Object id = objectMap.get("id");
JdbcUtils.execute(InitData.dataSource,deleteSql, Arrays.asList(id));
System.out.println("数据:"+id+"备份完成");
catch (SQLException e)
e.printStackTrace();
- 任务分片的情况
public class ElasticJobMain
public static void main(String[] args) throws SQLException
ZookeeperConfiguration zookeeperConfiguration=new ZookeeperConfiguration("localhost:2181","data-archive-job");
CoordinatorRegistryCenter coordinatorRegistryCenter=new ZookeeperRegistryCenter(zookeeperConfiguration);
coordinatorRegistryCenter.init();
//shardingTotalCount设置为3,shardingItemParameters为传入的分片参数,0=后面的值就是0分片将会取到的参数。如0=abc,那么0分片
//对应shardingContext.getShardingParameter()取到的就是abc
JobCoreConfiguration jobCoreConfiguration=JobCoreConfiguration.newBuilder("jobName2",
"0/2 * * * * ?",3).shardingItemParameters("0=0,1=1,2=2")
.build();
SimpleJobConfiguration simpleJobConfiguration=new SimpleJobConfiguration(jobCoreConfiguration,BackupJob.class.getName());
JobScheduler jobScheduler = new JobScheduler(coordinatorRegistryCenter, LiteJobConfiguration.newBuilder(simpleJobConfiguration).build());
jobScheduler.init();
public class BackupJob implements SimpleJob
@Override
public void execute(ShardingContext shardingContext)
int shardingItem = shardingContext.getShardingItem();
System.out.println("当前分片:"+shardingItem);
String shardingParameter = shardingContext.getShardingParameter();
System.out.println("获取分片参数:"+shardingParameter);
String sql="select * from t_order where user_id = ? limit 1";
try
List<Map<String, Object>> list = JdbcUtils.executeQuery(InitData.dataSource, sql,shardingParameter);
if(!list.isEmpty())
Map<String, Object> objectMap = list.get(0);
System.out.println(objectMap);
String insertSql="insert into t_order_bak (id,code,amt,create_time,user_id) values(?,?,?,?,?)";
Collection<Object> values = objectMap.values();
List<Object> params=new ArrayList<>();
params.addAll(values);
JdbcUtils.execute(InitData.dataSource,insertSql,params);
//删除原来的
String deleteSql="delete from t_order where id=?";
Object id = objectMap.get("id");
JdbcUtils.execute(InitData.dataSource,deleteSql, Arrays.asList(id));
System.out.println("数据:"+id+"备份完成");
catch (SQLException e)
e.printStackTrace();
五、Session共享
Session问题原因分析
出现这个问题的原因,从根本上来说是因为HTTP协议是无状态的协议。客户端和服务端在某次会话中产生的数据不会被保留下来,所以第二次请求服务端无法认识到你曾经来过。后来出现了两种用于保持Http状态的技术,就是Cookie和Session。
当集群中有多台服务器时,你在服务器1上登录了,服务器1的session里有了你的数据,下一次请求如果nginx把你路由到其他服务器,那你又需要登录了,因为其他服务器上没有存得有你的数据。
解决Session一致性方案
- 方案一:Nginx的ip_hash策略
同一个客户端ip的请求都会被路由到同一个目标服务器
- 优点:配置简单,不入侵应用
- 缺点:服务器重启Session丢失,单点故障问题
- 方案二:Session复制(不推荐)
多个Tomcat之间通过修改配置文件,达到Session之间的复制
- 优点:不入侵应用,便于扩展,服务器重启不会造成Session丢失
- 缺点:性能低,内存消耗,延迟性
- 方案三:Session集中存储(推荐)
- 优点:能适应各种负载均衡策略,服务器重启不会造成Session丢失
- 缺点:对应用有入侵,引入了和Redis的交互代码
Redis Session共享
Spring Session使得基于Redis的Session共享非常简单。
- 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
- 配置redis
spring.redis.database=0
spring.redis.host=127.0.0.1
spring.redis.port=6379
- 添加注解
在启动类上增加@EnableRedisHttpSession
以上是关于五大分布式场景解决方案的主要内容,如果未能解决你的问题,请参考以下文章