c++中mapmultimapunordered_mapunordered_multimap的区别
Posted 良知犹存
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c++中mapmultimapunordered_mapunordered_multimap的区别相关的知识,希望对你有一定的参考价值。

前言:
c++的各种容器使用的时候很方便,但是如果作为一个初学者,看到一堆库要记住也是很头疼的,而且很多库名称会很相似,所以我们要很好的使用这些库的时候,我们需要了解清楚它们底层实现的原理,这样我们使用中就更加得心应手。
今天给大家分享一下map、multimap、unordered_map、unordered_multimap,看上去是不是很相似,今天就来描述几者的区别。
作者:良知犹存
转载授权以及围观:欢迎关注微信公众号:羽林君
或者添加作者个人微信:become_me
几种容器的初步介绍:
map简介
map是STL的一个关联容器,map 容器中所有的元素都会根据元素对应的键值来排序,而键值key 是唯一值,并不会出现同样的键值key,也就是说假设已经有一个键值key 存在map 里,当同样的键值key 再insert 资料时,新的资料就会覆盖掉原本key 的资料。
map 的实作方式通常是用红黑树(red-black tree)实作的,这样它可以保证可以在O(log n)时间内完成搜寻、插入、删除,n为元素的数目。
常用函数
| 函数名 | 作用 |
|---|---|
| begin | 返回一个指向集合中第一个元素的迭代器 |
| end | 返回指向末尾的迭代器 |
| empty | 如果set为空,则返回true |
| size | 返回集合中元素的数量 |
| insert | 在集合中插入元素 |
| erase | 从集合中擦除元素 |
| swap | 交换集合的内容 |
| clear | 删除集合中的所有元素 |
| emplace | 构造新元素并将其插入到集合中 |
| find | 搜索具有给定键的元素 |
| count | 获取与给定键匹配的元素数 |
注意: 这里map的键值 key是不可以重复的,在实际使用中,如果用map[key] = xxx,其中key已经存在的情况下,key对应的元素会被覆盖掉,如果是用insert方式进行覆盖则会失败。
下面代码里面用到了 first和second
map.first:第一个称为(key)键值
map.second:第二个称为(key)键值对应的数值(value)
#include <iostream>
#include <map>
using namespace std;
int main()
std::map<int, std::string> studentMap =
1, "Tom",
7, "Mali",
15, "John";
for(auto i:studentMap2)
cout<<i.first<<" "
<<i.second;
cout<<endl;
std::pair<std::map<int, std::string>::iterator, bool> retPair;
retPair = studentMap.insert(std::pair<int, std::string>(15, "Bob"));
for(auto i:studentMap)
cout<<i.first<<" "
<<i.second;
cout<<endl;
studentMap[15] = "Lily";
for(auto i:studentMap)
cout<<i.first<<" "
<<i.second;
cout<<endl;
cout<<endl;
studentMap.erase(15);
for(auto i:studentMap)
cout<<i.first<<" "
<<i.second;
cout<<endl;
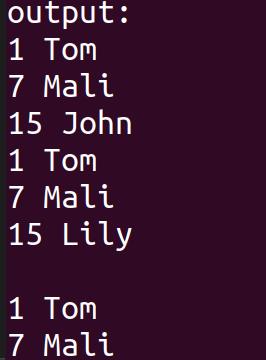
输出结果如图所示:
multimap简介
multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key, value>,其中多个键值对之间的key是可以重复的,multimap在底层用二叉搜索树(红黑树)来实现。
在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。和map最大的区别,multimap中的key是可以重复的。
常用函数参照map函数使用
#include <iostream>
#include <map>
using namespace std;
int main()
std::multimap<string, std::string> studentMap2 =
"first", "Tom",
"second", "Mali",
"third", "John";
studentMap2.insert(std::pair<std::string, std::string>("first", "Bob"));
cout<< "output:"<<endl;
for (std::multimap<std::string, std::string>::iterator it = studentMap2.begin(); it != studentMap2.end(); it++)
std::cout << (*it).first << ", " << (*it).second << "\\n";
std::cout << studentMap2.count("first") <<std::endl; // 输出为2
以上代码可以进行debug 进行查看,一个键值对应多个元素,对应数据排列的情况如下:
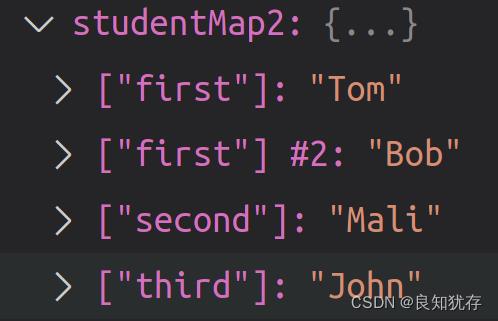
冲突的元素会使用元素链接的方式保存。
注意: multimap中没有重载operator[]操作。
所以我们无法使用 multimap[key]进行访问数据,是因为multimap的key可以对应多个数据,所以下标访问是没有意义的。
unordered_map简介
unordered_map 内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。容器中每个元素都是 key/value,每个 key 仅可出现一次。
unordered_map 特点就是搜寻效率高,利用键值与哈希函数(hash function)计算出哈希值而快速的查找到对应的元素,时间复杂度为常数级别O(1), 而额外空间复杂度则要高出许多。unordered_map 与map 的使用方法基本上一样,都是key/value 之间的映射,只是他们内部采用的资料结构不一样。所以对于需要高效率查询的情况可以使用unordered_map 容器。而如果对记忆体消耗比较敏感或者资料存放要求排序的话则可以用map 容器。
常用函数参照map函数使用
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
std::unordered_map < std::string , int > studentUMap3 =
"Tom" , 1 ,
"Ann" , 4 ,
"Job" , 2
;
studentUMap3.insert(std::pair<std::string, int>("Job", 5));
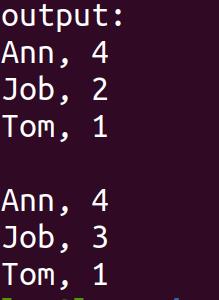
cout<< "output:"<<endl;
for (auto it = studentUMap3.begin(); it != studentUMap3.end(); it++)
std::cout << (*it).first << ", " << (*it).second << "\\n";
cout<<endl;
studentUMap3["Job"] = 3;
for (auto it = studentUMap3.begin(); it != studentUMap3.end(); it++)
std::cout << (*it).first << ", " << (*it).second << "\\n";
unordered_map用法和map基本一致,但是考虑的访问的速度有要求的情况下,我们优先使用,unordered_map;要是考虑到空间大小对程序影响的时候,我们优先使用map。
unordered_multimap简介
unordered_multimap 是一个封装哈希表的无序容器。容器中每个元素都是 key/value,每个 key 可重复出现。
同map和unordered_map区别一样,multimap通过key访问单个元素的速度通常也比unordered_multimap容器慢。
常用函数参照map函数使用
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
std::unordered_multimap < int , int > studentUMap4;
studentUMap4.insert(std::pair<int, int>(1, 333));
studentUMap4.insert(std::pair<int, int>(3, 555));
studentUMap4.insert(std::pair<int, int>(5, 666));
studentUMap4.insert(std::pair<int, int>(5, 5));
cout<< "output:"<<endl;
for (auto it = studentUMap4.begin(); it != studentUMap4.end(); it++)
std::cout << (*it).first << ", " << (*it).second << "\\n";
std::cout <<"count:"<< studentUMap4.count(5) <<std::endl;
std::cout <<"size: "<< studentUMap4.size() <<std::endl;
std::cout <<"empty?"<< studentUMap4.empty()<<"\\n" <<std::endl;
std::unordered_multimap < int , int >studentUMap5;
studentUMap5.swap(studentUMap4);
std::cout <<"count:"<< studentUMap4.count(5) <<std::endl;
std::cout <<"size: "<< studentUMap4.size() <<std::endl;
std::cout <<"empty?"<< studentUMap4.empty()<<"\\n" <<std::endl;
std::cout <<"count:" <<studentUMap5.count(5)<<"\\n" <<std::endl;
studentUMap5.clear();
std::cout <<"size: " <<studentUMap5.size() <<std::endl;
std::cout <<"empty?"<<studentUMap5.empty() <<std::endl;
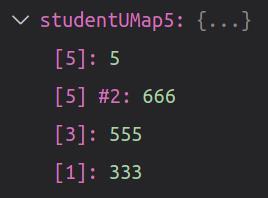
重复元素对应的debug显示
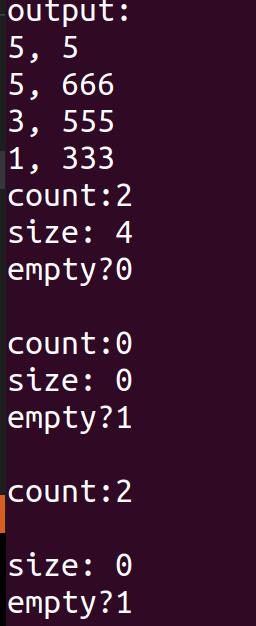
代码执行输出显示
区别介绍
首先这几个容器都是关联容器,其中无论是有序关联容器还是有序关联容器都是基于(set:集合 key map:映射表 [key : value])
来自
wiki
关联容器是指C++标准模板库中的一套类模板,实现了有序关联数组。可用于存放任意数据类型的元素。C++标准中定义的关联容器有: set, map, multiset, multimap。关联容器类似于C++中的无序关联容器。差别为:
- 关联容器是红黑树实现,无序关联容器是哈希表实现。
- 关联容器保证按键值有序遍历,因此可以做范围查找,而无序关联容器不可以。
- 关联支持一些导航类的>>操作,如求出给定键最邻近的键,最大键、最小键操作。
- 关联容器的迭代器不会失效,除非所指元素被删除。
- 无序关联容器的iterator在修改元素时可能会失>>效。所以对关联容器的遍历与修改在一定程度上可并行
- 哈希表查找时候要算hash,这个最坏时间复杂度是O(key的长度);基于比较的有序关联容器通常只使用>头几个字符进行比较
关联容器不支持顺序容器的位置相关的操作,例如 push_front 或 push_back 操作。原因是关联容器中>的元素是根据关键字来存储的,这些操作对于关联容器没有意义。
关联容器也不支持构造函数或插入操作这些接收一个元素值和一个数量值的操作。
因为map和multimap unordered_map和unordered_multimap两两区分时候,从底层实现来说,区别不是很大,所以我们先进行map与multimap的区别,再进行map和unordered_map区别比较。其他的类比即可。
最直观的区别:
map和unordered_map;//key不允许重复,是单重映射表
multimap和unordered_multimap;//key允许重复,是多重映射表
实现机制的区别:
map和unordered_map的区别:内部实现机理不同
-
map :map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找、删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树 (又名儿茶查找树、二叉排序树–特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根结点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
map和multimap的区别在于,map不允许相同key值存在,multimap则允许相同的key值存在。 -
unordered_map :unordered_map内部实现了一个哈希表 (也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序都是无序的。unordered_map 和 unordered_multimap 都是基于哈希表实现的,而且冲突策略采用的是链地址法。
使用的角度
空间占用率和效率上
unorder_map占用的内存更加高一点,unorder_map内部采用hash表,map内部采用的是红黑树,内存占有率的问题转化成hash表 VS 红黑树,还是unorder_map内存要高一点.
但是unorder_map采用哈希表搜索,搜寻效率高,利用键值与哈希函数(hash function)计算出哈希值而快速的查找到对应的元素,时间复杂度为常数级别O(1)
在关键字类型的元素没有明显的序的情况下,或者在某些应用中,维护元素有序的代价非常高昂,采用无序容器代替map来说效果会好。
结语
这就是我对map、multimap、unordered_map、unordered_multimap几者的分享,有机会可以给大家一起分享一下set, multiset 和 unordered_set, unordered_multiset的使用与区别。如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。
作者:良知犹存,白天努力工作,晚上原创公号号主。公众号内容除了技术还有些人生感悟,一个认真输出内容的职场老司机,也是一个技术之外丰富生活的人,摄影、音乐 and 篮球。关注我,与我一起同行。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
推荐阅读
【3】CPU中的程序是怎么运行起来的 必读
本公众号全部原创干货已整理成一个目录,回复[ 资源 ]即可获得。
以上是关于c++中mapmultimapunordered_mapunordered_multimap的区别的主要内容,如果未能解决你的问题,请参考以下文章