Java中List集合的浅析
Posted 空心小木头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中List集合的浅析相关的知识,希望对你有一定的参考价值。
一、介绍
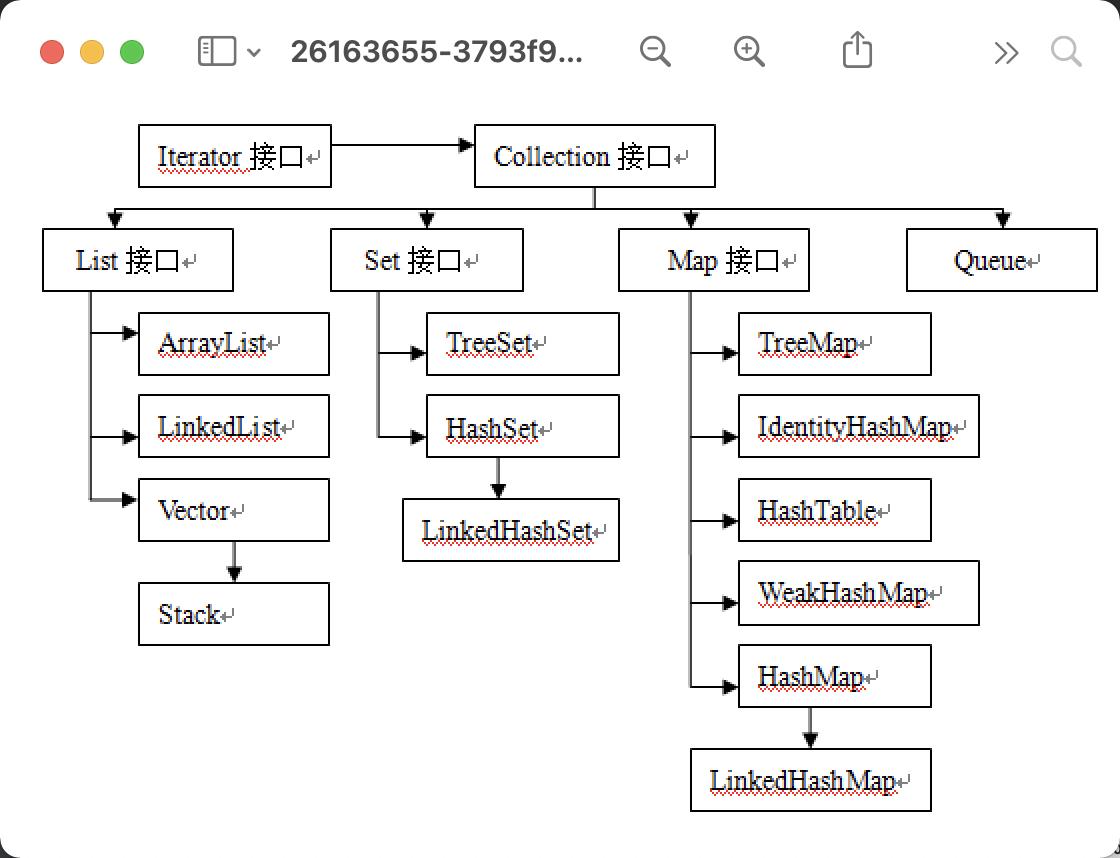
从上图可以得知,Java集合的整体都是继承了Collection接口,而Collection子类里又分了四类,本文将就其中的List接口及其子类进行深入研究。
List集合有几大特点:
1、List集合类中的元素都是有序的(添加和取出的顺序是一致的)
2、List集合类里的元素都有其对应的索引,即支持索引
3、List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
4、List的实现类有:ArrayList、LinkedList、Vector
二、ArrayList
ArrayList是由数组来实现存储数据的,在存储方法基本等同于Vector,唯一的区别就是ArrayList是线程不安全的,Vector是线程安全的,但这种线程不安全的设计让ArrayList的执行效率变高了,我们从一段例子去分析一下ArrayList的底层源码:
class Test{ public static void main(String[] args) { ArrayList list = new ArrayList(); for(int i = 1;i <= 10; i++){ list.add(i); } } }
这样一段代码是往list中间添加10个元素,我们利用debug来走看看ArrayList添加元素的实现方式:
1、自动装箱,由于list里面要存对象,而我们给的是常量,所以会自动帮我们封装成对应的对象:
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
注意这里之所以要判断,是因为 int 变量在 [-128,127]之间时,JDK就会分配给我们一个已经存在的Integer对象,而在这个范围外才会new一个对象
2、添加函数
public boolean add(E e) { modCount++; add(e, elementData, size); return true; }
这里的e就是我们要加入的对象,modCount是我们修改的次数,而add函数就是真正的添加函数
3、add函数
private void add(E e, Object[] elementData, int s) { if (s == elementData.length) elementData = grow(); elementData[s] = e; size = s + 1; }
add函数有三个参数,第一个参数E e是我们想要加入的对象,第二个参数Object[] elementData则是用于存储对象的数值,第三个int s则是数组下一个为空的位置
可以看到ArrayList之所以能够装不同的对象,因为它将这些对象都当作了Object来装入(Obejct是所有对象的父类)
在add函数体里面执行了两件事:
- 判断此时s是否等于数组的length:这里要注意s是数组下一个为空的下标,若此时s与数组的length相等,则代表数组已经装满,如果数组装满,则执行grow,这个grow就是对数组进行扩容
- 如果s不等于数组的length,代表可以装,将e加入到数组的s位置,然后size++
那我们就得了解一件事情,数组的长度初值是多少?扩容方式又是这样的?
其这与我们定义的方式有关,如果用无参构造,数组长度到初值就为0
若用有参数构造,数组的初始长度就可以利用参数传入
上述例子我们用的是无参数构造,所以这里初始的长度就是0,所以一开始就要进行扩容,我们继续往下看是如何扩容的:
4、数组扩容
private Object[] grow(int minCapacity) { return elementData = Arrays.copyOf(elementData, newCapacity(minCapacity)); } private Object[] grow() { return grow(size + 1); }
首先看这两个函数,这两个函数的意思就是我们要把扩容前数组到信息拷贝到扩容后到数组,底层是利用数组到拷贝进行数据的转移
而真正返回扩容后到数组是 newCapacity(minCapacity)函数
newCapacity(minCapacity)函数:
private int newCapacity(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity <= 0) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) return Math.max(DEFAULT_CAPACITY, minCapacity); if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); } private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
这里的代码略显复杂,大致可以分为几个方面:
1、当我们是从0初始化数组进行扩容的时候:
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) return Math.max(DEFAULT_CAPACITY, minCapacity);
在这两句,底层就会分配给我们一个DEFAULT_CAPACITY = 10的数组,也就是说从0开始扩容第一次得到是10的数组
2、当我们不是第一从0扩容:
int newCapacity = oldCapacity + (oldCapacity >> 1); return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity);
看这几段代码,这里出现一个带符号右移1位的操作,也就是将 newCapacity 赋值为 oldCapacity 的1.5倍,而这里newCapacity是新数组到长度,而oldCapacity是旧数组到长度。
所以这里我们可以得出结论,之后到每次扩容都会扩容到以前的1.5倍,扩容后即将数组返回
现在我们基本上说完了ArrayList加入元素的机制,总结一下:
1、ArrayList维护了一个Object类型的数组elementData[]
2、当创建ArrayList对象时,如果用到无参构造,则数组的初始长度为0,第一次扩容默认到10,之后一次扩1.5倍
3、当用的是有参构造时,则可以利用参数指定数组初始长度,之后再扩容同样是1.5倍
4、扩容后的数组利用Arrays.copyOf()方法将以前到数据拷贝过来
5、ArrayList是线程不安全的
三、LinkedList
LinkedList底层是用一个双向链表实现的,它可以添加任何类型的对象,同样是线程不安全的,我们先看一个例子:
class Test{ public static void main(String[] args) { LinkedList list = new LinkedList(); for(int i = 1;i < 15; i++){ list.add(i); } } }
这是一段往LinkedList添加元素的代码,我们同样利用debug来看一下他的执行过程:
1、自动装箱,LinkedList同样需要存入对象,在添加int类型的变量时也需要进行装箱,封装成Integer对象:
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
这里再解释一下:注意这里之所以要判断,是因为 int 变量在 [-128,127]之间时,JDK就会分配给我们一个已经存在的Integer对象,而在这个范围外才会new一个对象
2、在链表末端添加元素
public boolean add(E e) { linkLast(e); return true; }
这是add函数的原型,如果添加成功则返回true,而真正起作用的是 linkLast(e) 函数
注意:这里我们利用的是add方法,前面说过,Linklist底层实质是一个双向链表,是可以从前面插入和后面插入的,add方法默认调用是linkLast(e)方法,所以add默认是插入在链表的末端,传入的参数就是我们要插入的元素
linkLast()方法(末尾插入元素):
void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
这就是这个方法的全貌,其中last是一个类变量,它指向的链表的最末端,如果刚开始的链表为空,last就为null:
transient Node<E> last;
我们还可以观察到Node是这个链表的节点元素,我们同样看一下Node的组成:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
Node节点大概是由以下几部分组成:
1、E item:E是范型,item用来保存这个范型的对象
2、两个指针 next 和 pre 分别指向这个节点的前驱和后继
3、一个有参构造器
了解完这些,相信这个链表的组成已经十分清晰了,上面是非常典型的在末尾插入元素的链表操作
我们说过,维护的是一个双向链表(从Node的组成就看出来),我们再来看一下在链表前端插入的代码:
private void linkFirst(E e) { final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; }
这两种插入方式都是十分基础的方式,在这里就不赘述了
我们同样总结一下LinkedList的特点:
1、LinkList底层维护的是一个双向链表
2、可以添加任何对象,线程不安全(没有锁)
3、LinkList中的Node节点指向前驱和后继
4、LinkList可以从前端和后端插入,add方法默认是后端插入
四、Vector
Vector与上述两种容器最大的区别就是它是线程安全的,支持线程同步和互斥,Vector底层维护的是一个对象数组,这一点和ArrayList完全一致
在Java1.0/1.1中Vector是唯一可以自我扩展的容器,所以被大量使用,但放在现在已经过时了,因为在Java1.2就引用了集合,导致Vector的位置很尴尬,同时很多设计也不如现在的ArrayList,在Java编程思想中有这样一句话:“在写新程序时,绝不应该利用旧的容器”。
相同的还有Stack,Stack是继承了Vector而实现的,所以它现在也是过时类,不过是为了支持一些旧的代码,所以没有移出
所以我这里就对Vector不再说明
五、总结
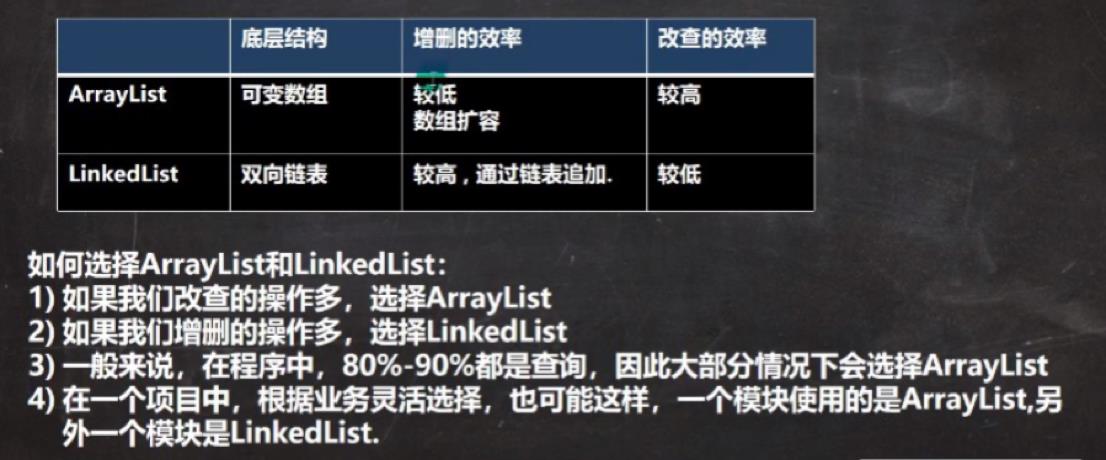
我们来比较一下List下的几个容器,以便在合适的时候选择合适的容器:

以上是关于Java中List集合的浅析的主要内容,如果未能解决你的问题,请参考以下文章