kafka学习笔记了解消息队列
Posted HappyTeemo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka学习笔记了解消息队列相关的知识,希望对你有一定的参考价值。
kafka是什么
你可以将它作为消息队列使用,点对点或者发布订阅的模式都可以。
你也可以将它作为消息引擎使用,实现信息流的管理。
总之,他是传递消息的一个工具。
那么,我们首先要知道的问题就是:
- 它是怎么传递消息的。
- 它的优势在哪里。
- 它该怎么使用,怎么写代码。
- 使用的过程中,需要注意什么。
下面我们慢慢来看。
什么是消息队列
消息队列是一种异步的服务间通信方式,适用于无服务器和微服务架构。 消息在被处理和删除之前一直存储在队列上。 每条消息仅可被一位用户处理一次。 消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。
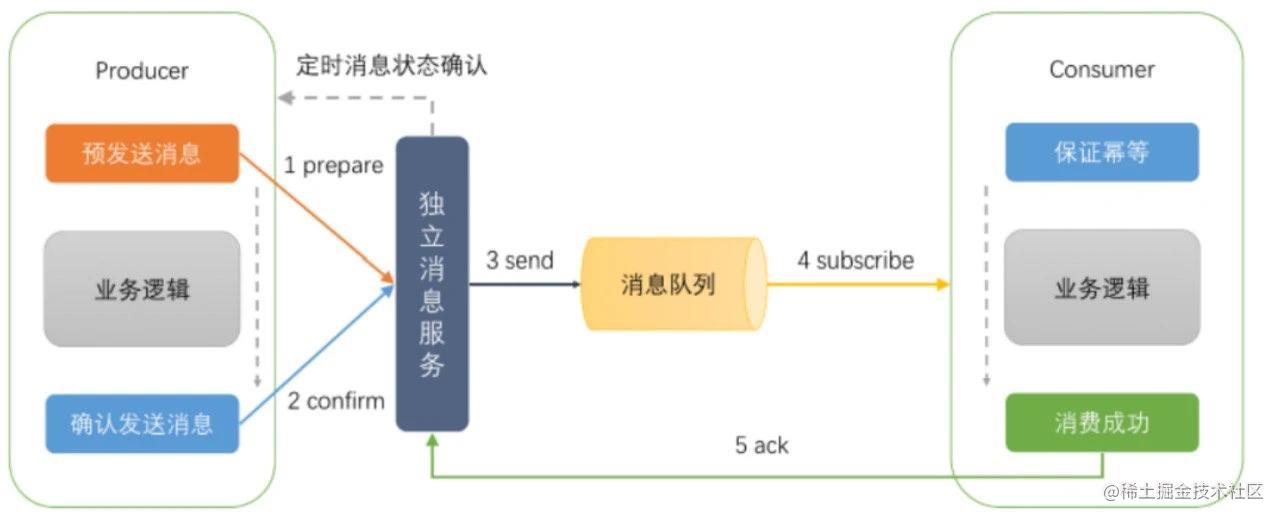
只要是用队列的形式将消息临时存储起来,然后一边写,一边读,就可以看做是个消息队列。写入的一方我们成为生产者,读取的一端我们成为消费者。
消息队列有两种模式:点对点(一对一)和发布订阅(一对多或多对多)。
为什么要使用消息队列
- 削峰填谷
这个可能是使用最多的情况。当上游的流量冲击过大, 想要不被打垮,要么抛弃这些流量,要么存储这些流量。很显然,存起来在大多数时候是更好地选择,注意这里是大多数,有时候一些具有时效性的场景,抛弃可能反而更好。
将流量存起来,在空闲的时候慢慢消费,缓冲上下游的瞬时突发流量,使其更平滑,增加系统的可用性,这就是削峰填谷。
- 解耦
通常我们的代码是存在调用链的,如果是一个单体里面,直接函数调用,等待返回就好了。但是在分布式、微服务中,我们可能不知道上下游的改动或者可靠性。
举个例子,A服务产生了一个事件,比如注册,调用了BCD三个服务,比如发短信、初始化用户缓存等操作。那么问题就来了:
- 如果需要添加E或者删除C,我们需要修改A的代码。
- 如果B挂了,ACD需要等它重启好了再开始工作么?如果不等,怎么补发消息?
- 如果D处理的很慢,ABC需要等待它么?
如果我们使用发布订阅模型,将它们解耦,A只用发布消息,BCD去订阅消息,添加E只要它去添加订阅即可。A不用关心消费者的速度或者是否存在,消息的存储由消息队列负责,等它们自己重启了再去消费即可。
- 异步
和解耦的案例很像,我们可以将ABCD这种顺序执行的事情改成A发完消息后就返回,BCD自己异步消费的模式,这样就使得A不用被不重要的事情拖慢处理速度。
消息队列的缺点
程序的世界是没有银弹的,凡事有利必然有弊。
- 可用性在初期是降低的。因为加入了新系统,必然会带来不稳定,尤其是消息队列往往会成为系统的核心,崩溃后带来的问题是范围极大的。但是一旦建设好了,整体的可用性会增加。
- 复杂度增加。需要解决消息丢失、重复消费、顺序性等问题。
- 一致性问题。也叫幂等性,即生产者生产的消息,消费者应该必然且只消费一次,哪怕多次消费,也应该和只消费了一次一样。
消息队列的三大难题:
- 消息重复消费。 即一条消息只应被消费一次。
- 消息丢失。 即消息应该被收到且消费。
- 消息的顺序消费。 即消息应该被顺序消费。
这三个会在后面的篇章里面单独讲,因为每一个都有难度。
还有个比较简单的问题:消息积压。
消息队列也只是添加了一个池子,仿佛三峡大坝,也是有上限的。当它快承受不了的时候,我们成为消息积压。
解决起来比较简单:
- 紧急扩容消费者,加快消费速度。
- 过期的消息抛弃。
- 根据消息的紧急程度,优先消费重要的。
消息的两种模型 Pull VS Push
Pull模式即消费者自己拉取,这样做的好处是消费者可以决定自己的速度。缺点是消费者需要轮训有没有新消息,如果消费者太慢,可能会反压上游。
Push模式就比较粗暴了,和发短信一样,直接消息队列推送,并不会管消费者的死活。这种方式显而易见会导致消息丢失,但是好处就是消息队列压力很小。
现在还有人用Redis写消息队列么?
答案是有的。虽然市面上已经有很多消息队列的程序,但是最简单的,还是Redis。
先说好处吧:
- 简单,这个毋庸置疑。
- 可用性,Redis从你要使用的开始,就要保证它的可用性,这样我们就不用再为引进新的系统而承受一次不稳定。
可以说这两点就足以秒杀千言万语了,事实上,在业务量不大的时候,它不失为一种选择。
可它的缺点也很致命:
- 如果消息很大,Redis的内存会暴涨。
- 如果消费者慢了,或者下游挂了,Redis的内存会暴涨。
- 一旦消息数量上亿了, 你的钱包还够用么?
- 如果Redis扛不住了,重启了,消息面临着丢失。
- 无法回放,无法还原当时的信息流现场。
kafka登场
既然Redis不靠谱,我们就要选择一个靠谱的。kafka当然只是一种选择,隔壁的RabbitMQ一样优秀。
那我们来看看它的优势:
- kafka是将消息存储在硬盘上,以追加写和零拷贝来提升效率。这样带来的好处就是廉价、高效、可靠,可以无限回放。(很适合做海量的消息存储和分析,硬盘比内存便宜太多了)
- 保障了单个partition上的消息顺序。
- 通过消息分区,分布式消费,使得扩容很简单,同时多副本保障了可用性。
- 具有消息压缩功能,极大节省了带宽。(消息队列的瓶颈绝对在带宽上,而不是硬盘、CPU或者内存上。)
结语
好了,先说这么多,下一章开始了解kafka的基本概念,如果你喜欢的话帮忙点赞一下,你的支持是我最大的动力。
以上是关于kafka学习笔记了解消息队列的主要内容,如果未能解决你的问题,请参考以下文章