MappedByteBuffer 详解(图解+秒懂+史上最全)
Posted 疯狂创客圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MappedByteBuffer 详解(图解+秒懂+史上最全)相关的知识,希望对你有一定的参考价值。
文章很长,而且持续更新,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源:
- 免费赠送 经典图书 : 极致经典 + 社群大片好评 《 Java 高并发 三部曲 》 面试必备 + 大厂必备 + 涨薪必备
- 免费赠送 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 (加尼恩领取)
- 免费赠送 经典图书 : 《SpringCloud、Nginx高并发核心编程》 面试必备 + 大厂必备 + 涨薪必备 (加尼恩领取)
- 免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 (加尼恩领取)
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:seata AT模式实战(图解+秒懂+史上最全) |
| 13:seata 源码解读(图解+秒懂+史上最全) | 14:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团... 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
背景:
下一个视频版本,从架构师视角,尼恩为大家彻底介绍 rocketmq 高可用、高并发中间件的原理与实操。
给大家底层的解读清楚 rocketmq 架构设计、源码设计、工业级高可用实操,含好多复杂度非常高、又非常核心的概念,比如 零复制、延迟容错、工业级RPC框架 ,以横扫全网和史无前例的方式,帮助大家彻底掌握、深入骨髓的掌握 rocketmq, 成为明年3月份征服面试官的神器
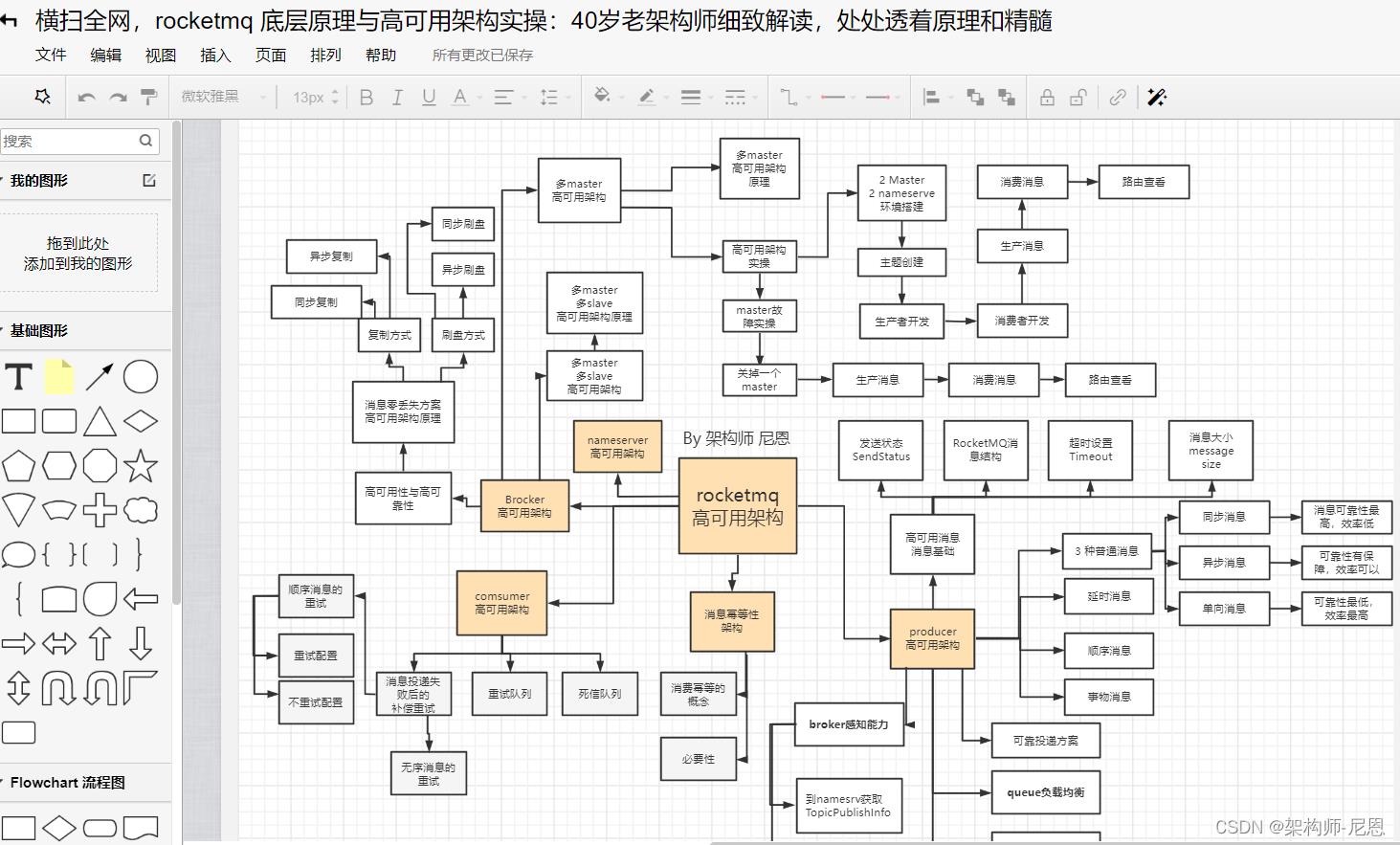
问题:why 高可用、高并发中间件的原理、源码与实操:
实际的开发过程中,很多小伙伴聚焦crud开发,环境出了问题,都不能启动。
作为开发人员,未来的高级开发、架构师,或者未来想走向高端开发,必须掌握高可用、高并发中间件的原理,掌握其实操。
本系列博客的具体内容,请参见 Java 高并发 发烧友社群:疯狂创客圈
MappedByteBuffer(图解+秒懂+史上最全)
这里 作为 rocketmq 高可用、高并发中间件的原理、源码与实操的前置知识,以博文的方式: 给大家介绍一下 MappedByteBuffer
java nio中引入了一种基于MappedByteBuffer操作大文件的方式,其读写性能极高,本文会介绍其性能如此高的内部实现原理。
内存管理
在深入MappedByteBuffer之前,先看看计算机内存管理的几个术语:
- MMU:CPU的内存管理单元。
- 物理内存:即内存条的内存空间。
- 虚拟内存:计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
- 交换空间:操作系统反映构建并使用虚拟内存的硬盘空间大小而创建的文件,在windows下,即pagefile.sys文件,其存在意味着物理内存被占满后,将暂时不用的数据移动到硬盘上。
- 缺页中断:当程序试图访问已映射在虚拟地址空间中但未被加载至物理内存的一个分页时,由MMC发出的中断。如果操作系统判断此次访问是有效的,则尝试将相关的页从虚拟内存文件中载入物理内存。
为什么会有虚拟内存和物理内存的区别?
如果正在运行的一个进程,它所需的内存是有可能大于内存条容量之和的,如内存条是256M,程序却要创建一个2G的数据区,那么所有数据不可能都加载到内存(物理内存),必然有数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,再调度进入物理内存。
什么是虚拟内存地址和物理内存地址?
假设你的计算机是32位,那么它的地址总线是32位的,也就是它可以寻址00xFFFFFFFF(4G)的地址空间,但如果你的计算机只有256M的物理内存0x0x0FFFFFFF(256M),同时你的进程产生了一个不在这256M地址空间中的地址,那么计算机该如何处理呢?
回答这个问题前,先说明计算机的内存分页机制。
计算机会对虚拟内存地址空间(32位为4G)进行分页(page),对物理内存地址空间(假设256M)进行分帧(page frame),页和页帧的大小一样,所以虚拟内存页的个数势必要大于物理内存页帧的个数。
在计算机上有一个页表(page table),就是映射虚拟内存页到物理内存页的,更确切的说是页号到页帧号的映射,而且是一对一的映射。
问题来了,虚拟内存页的个数 > 物理内存页帧的个数,岂不是有些虚拟内存页的地址永远没有对应的物理内存地址空间?
不是的,操作系统是这样处理的。操作系统有个页面失效(page fault)功能。操作系统找到一个最少使用的页帧,使之失效,并把它写入磁盘,随后把需要访问的页放到页帧中,并修改页表中的映射,保证了所有的页都会被调度。
现在来看看什么是虚拟内存地址和物理内存地址:
- 虚拟内存区域:由页号(与页表中的页号关联)和偏移量(页的小大,即这个页能存多少数据)组成。
举个例子,有一个虚拟地址它的页号是4,偏移量是20,那么他的寻址过程是这样的:
首先到页表中找到页号4对应的页帧号(比如为8),如果页不在内存中,则用失效机制调入页,接着把页帧号和偏移量传给MMC组成一个物理上真正存在的地址,最后就是访问物理内存的数据了。
Java中基础MMap的使用
MappedByteBuffer是什么?从继承结构上看,MappedByteBuffer继承自ByteBuffer,内部维护了一个逻辑地址address。
将共享内存和磁盘文件建立联系的是文件通道类:FileChannel。
该类的加入是JDK为了统一对外部设备(文件、网络接口等)的访问方法,并且加强了多线程对同一文件进行存取的安全性。
这里只是用它来建立共享内存用,它建立了共享内存和磁盘文件之间的一个通道。
FileChannel提供了map方法把文件映射到虚拟内存,通常情况可以映射整个文件,如果文件比较大,可以进行分段映射。
大致的步骤:
-
首先通过 RandomAccessFile获取文件通道。
-
然后,通过channel进行内存映射,获取一个虚拟内存区域VMA
//通过RandomAccessFile获取FileChannel。
try (FileChannel channel = new RandomAccessFile(decodePath, "rw").getChannel();) {
//通过channel进行内存映射,获取一个虚拟内存区域VMA
MappedByteBuffer mapBuffer = channel.map(FileChannel.MapMode.PRIVATE, 0, length);
....
channel.map方法的参数:
- 映射类型
MapMode mode:内存映像文件访问的方式,FileChannel中的几个常量定义,共三种:
- MapMode.READ_ONLY:只读,试图修改得到的缓冲区将导致抛出异常。
- MapMode.READ_WRITE:读/写,对得到的缓冲区的更改最终将写入文件;但该更改对映射到同一文件的其他程序不一定是可见的。
- MapMode.PRIVATE:私用,可读可写,但是修改的内容不会写入文件,只是buffer自身的改变,这种能力称之为”copy on write”。
- position:文件映射时的起始位置。
- length:映射区的长度。长度单位为字节。长度单位为字节
示例1:通过MappedByteBuffer读取文件
package com.crazymakercircle.iodemo.fileDemos;
import com.crazymakercircle.NioDemoConfig;
import com.crazymakercircle.util.IOUtil;
import com.crazymakercircle.util.Logger;
import java.io.*;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
/**
* Created by 尼恩@ 疯创客圈
*/
public class FileMmapDemo {
/**
* 演示程序的入口函数
*
* @param args
*/
public static void main(String[] args) {
doMmapDemo();
}
/**
* 读取
*/
public static void doMmapDemo() {
String sourcePath = NioDemoConfig.MMAP_FILE_RESOURCE_SRC_PATH;
String decodePath = IOUtil.getResourcePath(sourcePath);
Logger.debug("decodePath=" + decodePath);
mmapWriteFile(decodePath);
}
/**
* 读取文件内容并输出
*
* @param fileName 文件名
*/
public static void mmapWriteFile(String fileName) {
//向文件中存1M的数据
int length = 1024;//
try (FileChannel channel = new RandomAccessFile(fileName, "rw").getChannel();) {
//一个整数4个字节
MappedByteBuffer mapBuffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, length);
for (int i = 0; i < length; i++) {
mapBuffer.put((byte) (Integer.valueOf(\'a\') + i % 26));
}
for (int i = 0; i < length; i++) {
if (i % 50 == 0) System.out.println("");
//像数组一样访问
System.out.print((char) mapBuffer.get(i));
}
mapBuffer.force();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出的结果
decodePath=/E:/refer/crazydemo/netty_redis_zookeeper_source_code/NioDemos/target/classes//mmap.demo.log
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwx
yzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuv
wxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrst
uvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqr
stuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnop
qrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmn
opqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijkl
mnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghij
klmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefgh
ijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef
ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd
efghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzab
cdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwx
yzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuv
wxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrst
uvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqr
stuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnop
qrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmn
opqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijkl
mnopqrstuvwxyzabcdefghijDisconnected from the target VM, address: \'127.0.0.1:50970\', transport: \'socket\'
Process finished with exit code 0
示例2:通过MappedByteBuffer读取私用映射
私用,可读可写,但是修改的内容不会写入文件,只是buffer自身的改变,这种能力称之为”copy on write”。
/**
* 读取文件内容并输出
*
*/
public static void mmapPrivate() {
String sourcePath = NioDemoConfig.MMAP_FILE_RESOURCE_SRC_PATH;
String decodePath = IOUtil.getResourcePath(sourcePath);
Logger.debug("decodePath=" + decodePath);
//向文件中存1M的数据
int length = 1024;//
try (FileChannel channel = new RandomAccessFile(decodePath, "rw").getChannel();) {
//一个整数4个字节
MappedByteBuffer mapBuffer = channel.map(FileChannel.MapMode.PRIVATE, 0, length);
for (int i = 0; i < length; i++) {
mapBuffer.put((byte) (Integer.valueOf(\'a\') + i % 26));
}
for (int i = 0; i < length; i++) {
if (i % 50 == 0) System.out.println("");
//像数组一样访问
System.out.print((char) mapBuffer.get(i));
}
mapBuffer.force();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
执行程序,可以看到文件并没有写入的内容。
实例3:通过MMap共享内存
共享内存对应应用开发的意义
对熟知UNIX系统应用开发的程序员来说,IPC(InterProcess Communication)机制是非常熟悉的,
IPC基本包括共享内存、信号灯操作、消息队列、信号处理等部分,是开发应用中非常重要的必不可少的工具。
在所有的IPC中, 其中共享内存是关键,对于数据共享、系统快速查询、动态配置、减少资源耗费等均有独到的优点。
对应UNIX系统来说,共享内存分为一般普通共享内存和文件映射共享内存两种,而对应 Windows,实际上只有映像文件共享内存一种。
所以java应用中也是只能创建映像文件共享内存。
Java中的共享内存场景
在java语言中,基本上没有提及共享内存这个概念,但是,在某一些应用中,共享内存确实非常有用。
例如采用java语言的分布式应用系统中,存在着大量的分布式共享对象,很多时候需要查询这些对象的状态,以查看系统是否运行正常或者了解这些对象的目前的一些统计数据和状态。
如果采用网络通信的方式,显然会增加应用的额外负担,也增加了一些不必要的应用编程。
而如果采用共享内存的方式,则可以直接通过共享内存查看对象的状态数据和统计数据,从而减少了一些不必要的麻烦。
共享内存的使用有如下几个特点:
- 可以被多个进程打开访问;
- 读写操作的进程在执行读写操作时其他进程不能进行写操作;
- 多个进程可以交替对某一共享内存执行写操作;
- 一个进程执行了内存的写操作后,不影响其他进程对该内存的访问。同时其他进程对更新后的内存具有可见性。
- 在进程执行写操作时如果异常退出,对其他进程写操作禁止应自动解除。
- 相对共享文件,数据访问的方便性和效率有
共享内存在java中的实现
在jdk1.4中提供的类MappedByteBuffer为我们实现共享内存提供了较好的方法。
该缓冲区实际上是一个磁盘文件的内存映像。二者的变化将保持同步,即内存数据发生变化会立刻反映到磁盘文件中,这样会有效的保证共享内存的实现。
将共享内存和磁盘文件建立联系的是文件通道类:FileChannel。
该类的加入是JDK为了统一对外部设备(文件、网络接口等)的访问方法,并且加强了多线程对同一文件进行存取的安全性。
这里只是用它来建立共享内存用,它建立了共享内存和磁盘文件之间的一个通道。
打开一个文件建立一个文件通道可以用RandomAccessFile类中的方法getChannel。
该方法将直接返回一个文件通道。
该文件通道由于对应的文件设为随机存取文件,一方面可以进行读写两种操作,另一方面使用它不会破坏映像文件的内容(如果用FileOutputStream直接打开一个映像文件会将该文件的大小置为0,当然数据会全部丢失)。
为什么用 FileOutputStream和FileInputStream则不能理想的实现共享内存的要求呢?
因为这两个类同时实现自由的读写操作要困难得多。
如何保障写入的互斥性
由于只有一个文件能拥有写的权限,可以通过分布式锁的方式,保障排他性。
如果在同一个机器上有一种简单的互斥方式:
- 采用文件锁的方式。
共享内存在java中的应用的参考代码
package com.crazymakercircle.iodemo.sharemem;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileLock;
import java.util.Properties;
import com.crazymakercircle.NioDemoConfig;
import com.crazymakercircle.util.IOUtil;
/**
* 共享内存操作类
*/
public class ShareMemory {
String sourcePath = NioDemoConfig.MEM_SHARE_RESOURCE_SRC_PATH;
String decodePath = IOUtil.getResourcePath(sourcePath);
int fsize = 1024; //文件的实际大小
MappedByteBuffer mapBuf = null; //定义共享内存缓冲区
FileChannel fc = null; //定义相应的文件通道
FileLock fl = null; //定义文件区域锁定的标记。
Properties p = null;
RandomAccessFile randomAccessFile = null; //定义一个随机存取文件对象
public ShareMemory() {
try {
// 获得一个只读的随机存取文件对象 "rw" 打开以便读取和写入。如果该文件尚不存在,则尝试创建该文件。
randomAccessFile = new RandomAccessFile(decodePath, "rw");
//获取相应的文件通道
fc = randomAccessFile.getChannel();
//将此通道的文件区域直接映射到内存中。
mapBuf = fc.map(FileChannel.MapMode.READ_WRITE, 0, fsize);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* @param pos 锁定区域开始的位置;必须为非负数
* @param len 锁定区域的大小;必须为非负数
* @param buff 写入的数据
* @return
*/
public synchronized int write(int pos, int len, byte[] buff) {
if (pos >= fsize || pos + len >= fsize) {
return 0;
}
//定义文件区域锁定的标记。
FileLock fl = null;
try {
//获取此通道的文件给定区域上的锁定。
fl = fc.lock(pos, len, false);
if (fl != null) {
mapBuf.position(pos);
ByteBuffer bf1 = ByteBuffer.wrap(buff);
mapBuf.put(bf1);
//释放此锁定。
fl.release();
return len;
}
} catch (Exception e) {
if (fl != null) {
try {
fl.release();
} catch (IOException e1) {
System.out.println(e1.toString());
}
}
return 0;
}
return 0;
}
/**
* @param pos 锁定区域开始的位置;必须为非负数
* @param len 锁定区域的大小;必须为非负数
* @param buff 要取的数据
* @return
*/
public synchronized int read(int pos, int len, byte[] buff) {
if (pos >= fsize) {
return 0;
}
//定义文件区域锁定的标记。
FileLock fl = null;
try {
fl = fc.lock(pos, len, false);
if (fl != null) {
//System.out.println( "pos="+pos );
mapBuf.position(pos);
if (mapBuf.remaining() < len) {
len = mapBuf.remaining();
}
if (len > 0) {
mapBuf.get(buff, 0, len);
}
fl.release();
return len;
}
} catch (Exception e) {
if (fl != null) {
try {
fl.release();
} catch (IOException e1) {
System.out.println(e1.toString());
}
}
return 0;
}
return 0;
}
/**
* 完成,关闭相关操作
*/
protected void finalize() throws Throwable {
if (fc != null) {
try {
fc.close();
} catch (IOException e) {
System.out.println(e.toString());
}
fc = null;
}
if (randomAccessFile != null) {
try {
randomAccessFile.close();
} catch (IOException e) {
System.out.println(e.toString());
}
randomAccessFile = null;
}
mapBuf = null;
}
/**
* 关闭共享内存操作
*/
public synchronized void closeSMFile() {
if (fc != null) {
try {
fc.close();
} catch (IOException e) {
System.out.println(e.toString());
}
fc = null;
}
if (randomAccessFile != null) {
try {
randomAccessFile.close();
} catch (IOException e) {
System.out.println(e.toString());
}
randomAccessFile = null;
}
mapBuf = null;
}
}
map过程核心原理
接下去通过分析源码,了解一下map过程的内部实现。
- 通过RandomAccessFile获取FileChannel。
public final FileChannel getChannel() {
synchronized (this) {
if (channel == null) {
channel = FileChannelImpl.open(fd, path, true, rw, this);
}
return channel;
}
}
上述实现可以看出,由于synchronized ,只有一个线程能够初始化FileChannel。
通过FileChannel.map方法,把文件映射到虚拟内存,并返回逻辑地址address,实现如下:
**只保留了核心代码**
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
int pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
long mapSize = size + pagePosition;
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
}
上述代码可以看出,最终map通过native函数map0完成文件的映射工作。
- 如果第一次文件映射导致OOM,则手动触发垃圾回收,休眠100ms后再次尝试映射,如果失败,则抛出异常。
- 通过newMappedByteBuffer方法初始化MappedByteBuffer实例,不过其最终返回的是DirectByteBuffer的实例,实现如下:
static MappedByteBuffer newMappedByteBuffer(int size, long addr, FileDescriptor fd, Runnable unmapper) {
MappedByteBuffer dbb;
if (directByteBufferConstructor == null)
initDBBConstructor();
dbb = (MappedByteBuffer)directByteBufferConstructor.newInstance(
new Object[] { new Integer(size),
new Long(addr),
fd,
unmapper }
return dbb;
}
// 访问权限
private static void initDBBConstructor() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
Class<?> cl = Class.forName("java.nio.DirectByteBuffer");
Constructor<?> ctor = cl.getDeclaredConstructor(
new Class<?>[] { int.class,
long.class,
FileDescriptor.class,
Runnable.class });
ctor.setAccessible(true);
directByteBufferConstructor = ctor;
}});
}
由于FileChannelImpl和DirectByteBuffer不在同一个包中,所以有权限访问问题,通过AccessController类获取DirectByteBuffer的构造器进行实例化。
DirectByteBuffer是MappedByteBuffer的一个子类,其实现了对内存的直接操作。
get过程
MappedByteBuffer的get方法最终通过DirectByteBuffer.get方法实现的。
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
private long ix(int i) {
return address + (i << 0);
}
map0()函数返回一个地址address,这样就无需调用read或write方法对文件进行读写,通过address就能够操作文件。底层采用unsafe.getByte方法,通过(address + 偏移量)获取指定内存的数据。
- 第一次访问address所指向的内存区域,导致缺页中断,中断响应函数会在交换区中查找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则从硬盘上将文件指定页读取到物理内存中(非jvm堆内存)。
- 如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘的虚拟内存中。
性能分析
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。
但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么?
- read()是系统调用,首先将文件从硬盘拷贝到内核空间的一个缓冲区,再将这些数据拷贝到用户空间,实际上进行了两次数据拷贝;
- map()也是系统调用,但没有进行数据拷贝,当缺页中断发生时,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝。
所以,采用内存映射的读写效率要比传统的read/write性能高。
总结
- MappedByteBuffer使用虚拟内存,因此分配(map)的内存大小不受JVM的-Xmx参数限制,但是也是有大小限制的。
- 如果当文件超出1.5G限制时,可以通过position参数重新map文件后面的内容。
- MappedByteBuffer在处理大文件时的确性能很高,但也存在一些问题,如内存占用、文件关闭不确定,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
javadoc中也提到:A mapped byte buffer and the file mapping that it represents remain valid until the buffer itself is garbage-collected.
以上是关于MappedByteBuffer 详解(图解+秒懂+史上最全)的主要内容,如果未能解决你的问题,请参考以下文章