JDBC第三天~JDBC之事务批处理自动生成主键连接池重构设计
Posted 一乐乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDBC第三天~JDBC之事务批处理自动生成主键连接池重构设计相关的知识,希望对你有一定的参考价值。
JDBC第三天~JDBC之事务、批处理、自动生成主键、连接池、重构设计JDBC第三天学习:
一、事务Transaction(简写tx):
在数据库中,事务是指:一组逻辑操作,无论成或败,都作为一个整体进行工作,要么全部执行,要么全部不执行。
■ 引入背景:银行转账突遇断电的bug
1,处理事务的两个动作:
■ 提交commit:当整个事务中,所有的逻辑操作都是正常执行成功。 --》提交事务
■ 回滚rollback:当整个事务中,有一个或多个逻辑操作执行失败。 --》回滚事务,撤销该事务中所有的操作,恢复到最初的状态。
2,面试常考的ACID属性:
① 原子性:事务是应用中不可再分的最小逻辑执行单位体,要么都执行,要么都不执行。
② 一致性:事务结束后,数据库内的数据是合法正确的;(数据不被破坏)【‘数据守恒’】
③ 隔离性:并发执行的事务之间彼此相互独立、互相不干扰
④ 持久性:事务提交后,数据是永久性的、不可回滚。
3,处理事务操作的模板:
1):在一组逻辑操作之前:设置事务为手动提交(即取消自动提交) Connection对象.setAutoCommit(false);
2): 进行一组逻辑操作之后:进行事务的提交:connecton对象.commit();
3): 若该过程遇到了异常,则回滚:connection对象.rollback();
注意:
1,在jdbc事务中是默认提交的,在执行DML或DDL操作时就已经提交事务了。
2,对于CRUD操作,只有DML操作才需要事务,查询不需要事务。
3,细节:以后但凡发现自己设计到事务的代码测试通过了,但是数据库表中的数据不被。--》事务没有提交
4,Mysql中,InnoDB支持外键,支持事务;MyISAM不支持外键,不支持事务。
二、批量处理(batch)
1,jdbc批处理语句的方法:
■ addBatch(); 添加需要批量处理的SQL语句或者参数;
■ executeBatch(); 执行批量处理语句;
2,通常我们会遇到两种情况需要执行sql语句的情况:
■ 多条sql语句的批量处理:statement
■ 一个sql语句的批量传参:preparedment
3,结论:对于MySql服务器:既不支持PreparedStatement的性能优化,也不支持JDBC中的批量操作。
但是,在新的JDBC驱动中,我们可以通过设置参数来支持批处理操作。【对PreparedStatement有效】
url=jdbc:mysql://localhost:3306/数据库名称?rewriteBatchedStatements=true
三、开发中获取自动生成主键
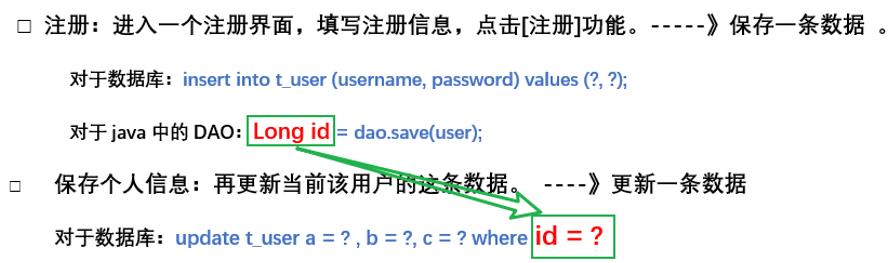
☆问题:为什么需要获取自动生成主键?
举例:注册时,需要你填写的个人信息非常多,容易引起用户的反感,所以改成两个页面【快速注册+完善个人信息】:
■ 在开发中,获取自动生成主键的案例还有很多,比如单据和单据明细之间的关系。
|
■ 如何获取自动生成的主键? 1):先找找原先代码的接口对象是否有提过对应的方法? // 贾琏欲执事 Connection conn = null; Statement st = null; conn = JdbcUtil.getConn(); //① 先在接口对象 connection中找一下,无 st = conn.createStatement(); //② 则再接口对象 statement中找,发现了statement的执行接口方法: ③ int executeUpdate(String sql, int autoGenerateKeys );中这个参数autoGenerateKeys[int 类型,很有可能是常数],然发现果然,且其中一个常数值是 ④ Statement.RETURN_GENERATED_KEYS, 然后再找一个发现有个方法: ⑤ getGeneratekeys(); 便是咱要的获取主键的最终方法
st.executeUpdate(sql.toString()); |
|
2):自动生成主键具体实现的步骤:
//设置可以获取自动生成的主键 st.executeUpdate(sql.toString(), Statement.RETURN_GENERATED_KEYS); //去获取自动生成的主键 ResultSet keyRs = st.getGeneratedKeys(); if(keyRs.next()) { Long id = keyRs.getLong(1);//获取第一列 System.out.println(id); return id; } |
四、连接池(也叫数据源DataSource)
● 连接池 Connection Pool:
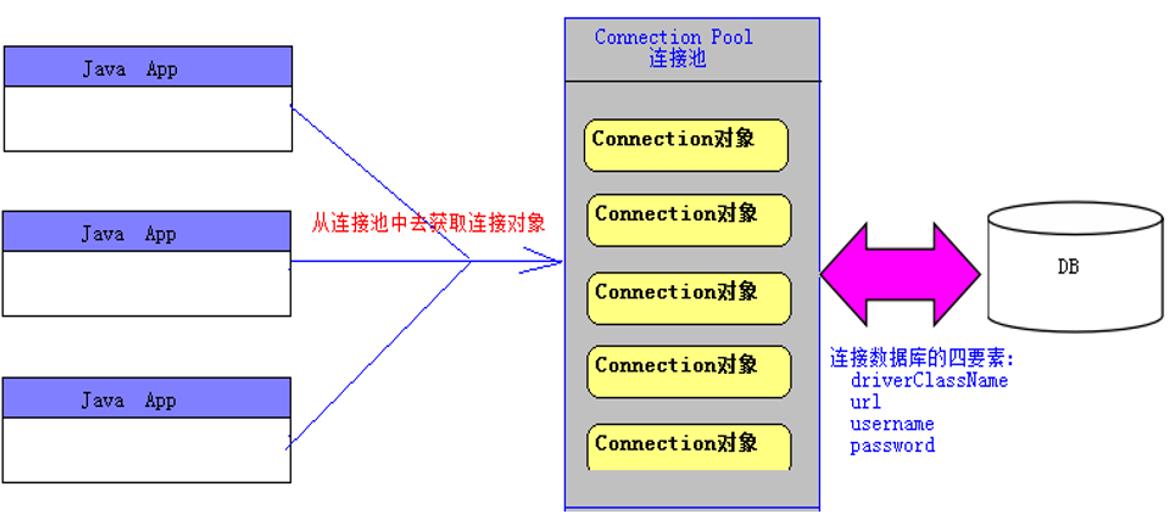
1、连接池的属性:提高连接池的性能 (缓存思想)
1):连接数据库的四要素
2):初始化连接数 [假如你想买票,卖票的窗口应该先存在吧]
3):最大的连接数和最小的连接数 [例如某块地(规划要建立成一个学校),不能全部都建立成操场吧,对于操场数量应该设定一定范围吧
4):最大的空闲时间和最大等待时间 [最大空闲时间:当你占着资源,在一定时间内都没有什么动作,总不能让你一直“占着茅坑不拉si吧”,就自动释放连接了; 最大的等待时间:等了一定时间,就提示你没有了]
2、连接池(数据源javax.sql.DataSource)概述:
注意:DataSource 和 JDBC 一样,仅仅只是接口,sun公司不自己提供实现,由第三方组织提供。
1):常用的连接池:
■ druid(德鲁伊):阿里巴巴提供的,号称世界最好的连接池
■ DBCP:Spring 推荐的
■ C3P0:Hibernate推荐的,已经过时了,性能比较差
2)使用数据源(连接池)和不使用的区别:
■ 获取连接的方式不同、释放资源的方式不同。

3)学习连接池操作(主要重点是学习如何创建DataSource对象)
Connection conn = DataSource对象.getConnection(); //不同数据库连接池,其实就是在创建DataSource的方式上有所不同。
-------------------------------------------------------------------------------------------------------------------
❀ 开发中需要的jar包,到maven仓库中下载:https://mvnrepository.com/
1、dbcp:
● 下载:commons-dbcp和 commons-pool的jar包【注意是jar包,不是zip包】
2、druid:
● 下载:druid 的jar包
ps:文档:https://github.com/alibaba/druid/wiki 使用起来非常类似DBCP连接池
经过对比,Druid数据源(连接池)更加优秀,以后使用它即可
---------------------------------------------------------------------------------------------------------------
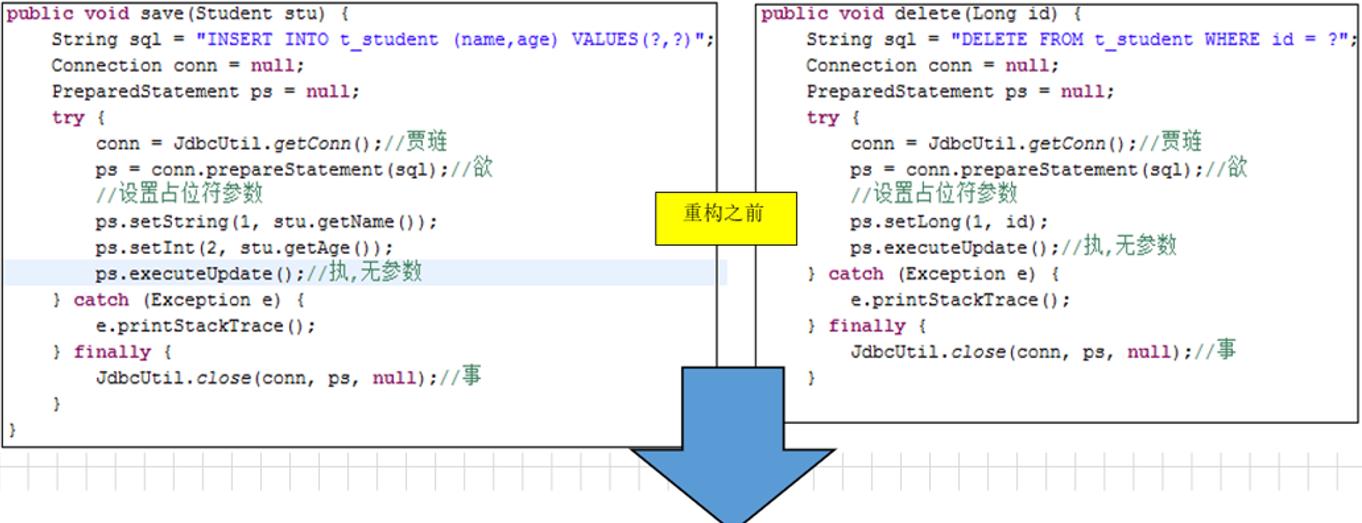
五、重构设计:
■重构思想:至少是两段代码,因为一段代码,我们看不出相同与不同。
■ 重构精髓:把多段代码共同的结构和代码提取出来,达到复用。
□ 相同的代码抽取出去之后,不同的代码,通过类型最终可以找到共同点,处理为参数
□ 这里以模板工具类JdbcTemplate 中的更新方法为例:
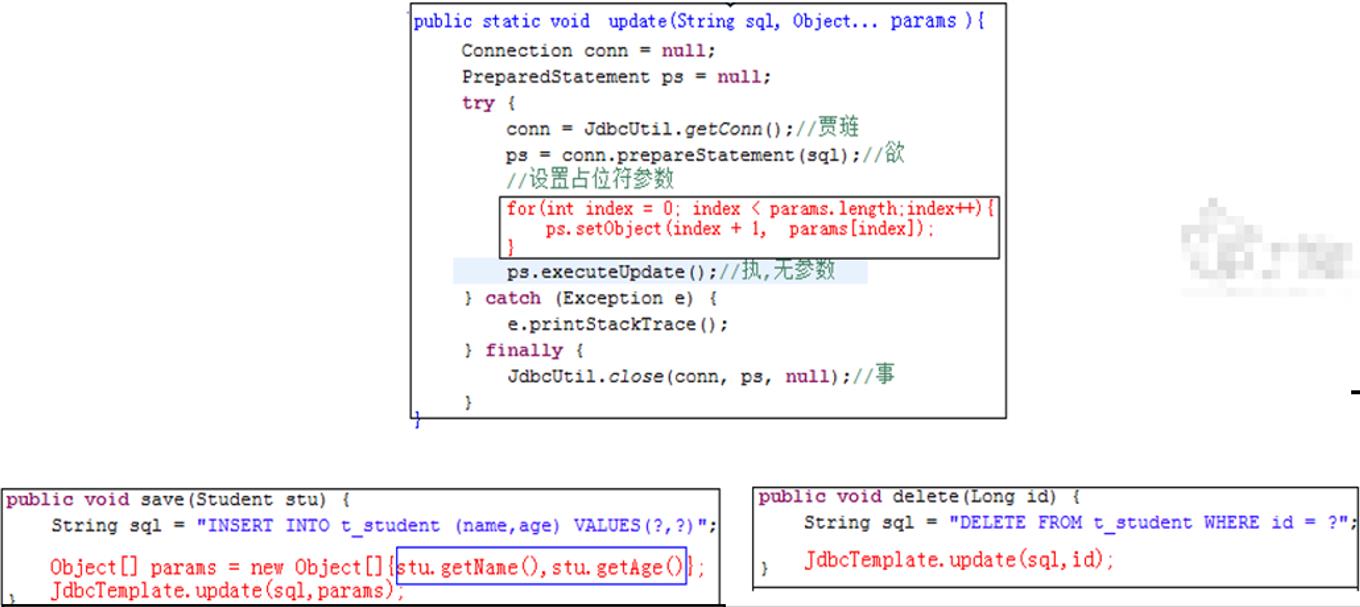
☆ 问题 :JdbcTemplate模板类中查询方法结果集处理写死了:
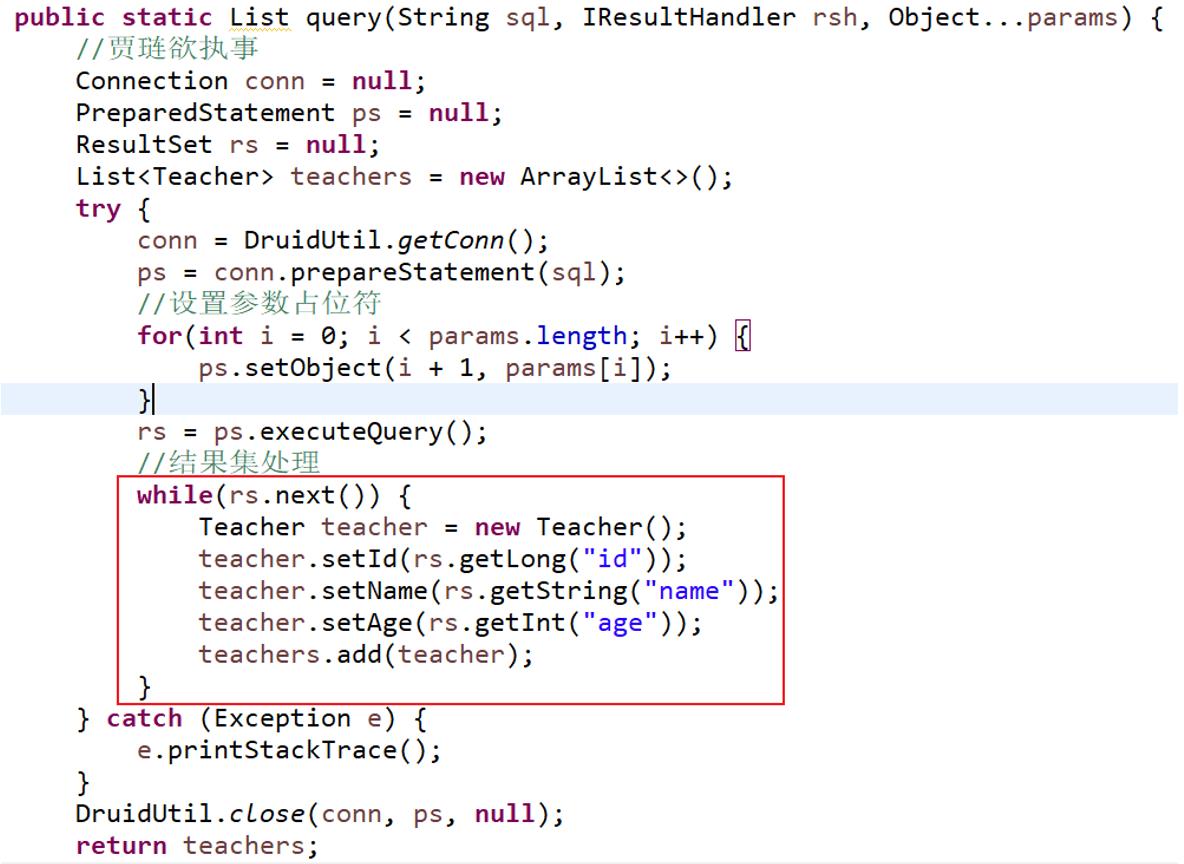
☆解决:把结果集的处理行为交个每个对象的DAO实现类来做
【为了避免不同的DAO 实现类定义的处理结果集的方法名不同,我们定义了一个接口 IResultSetHandler来规范】
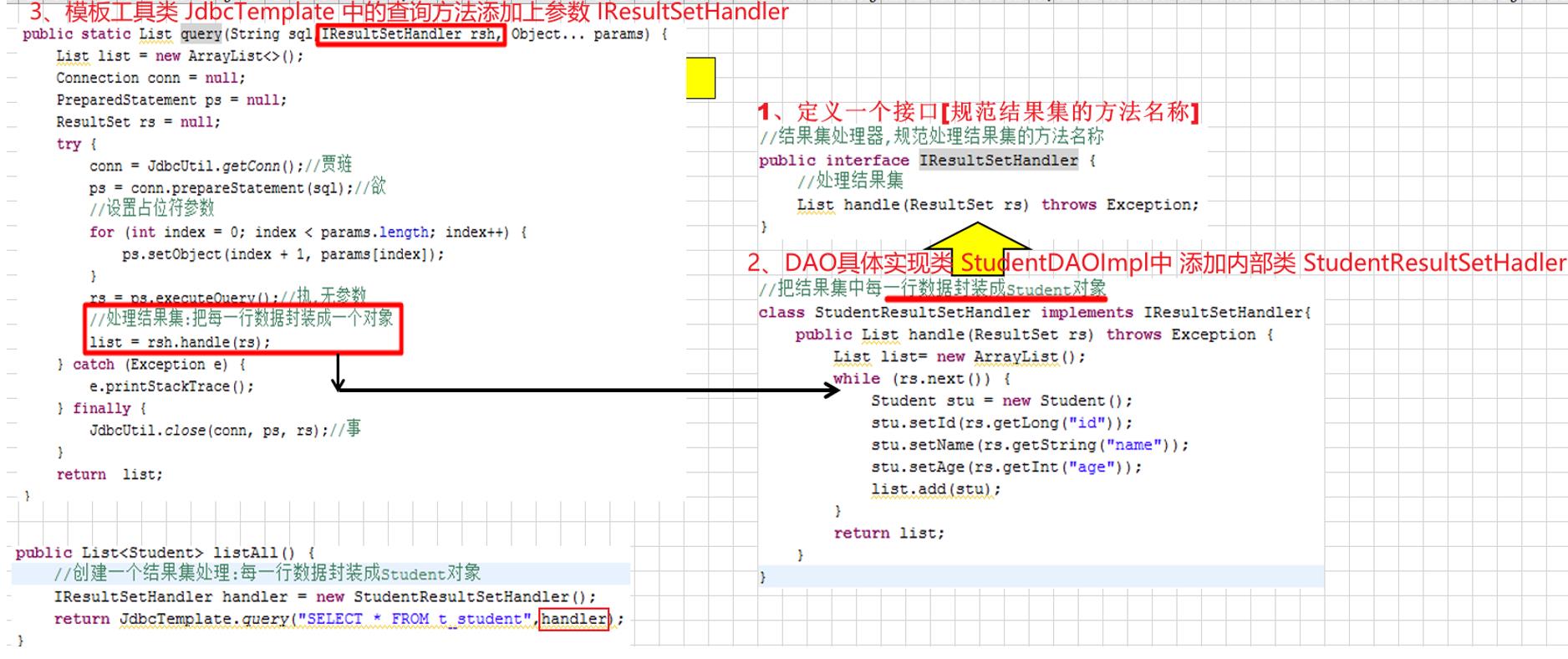
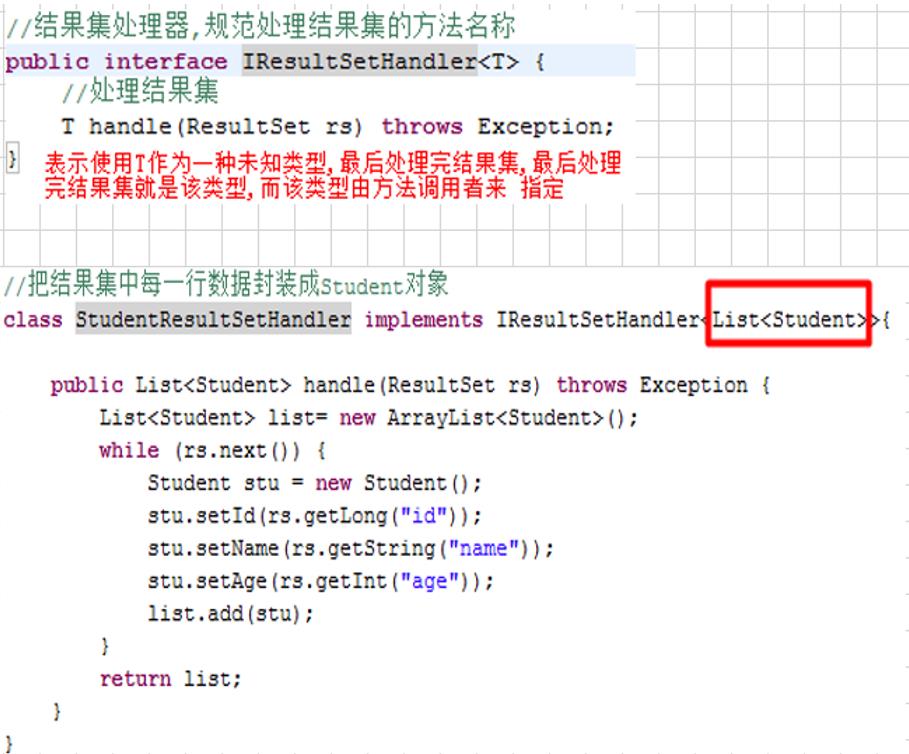
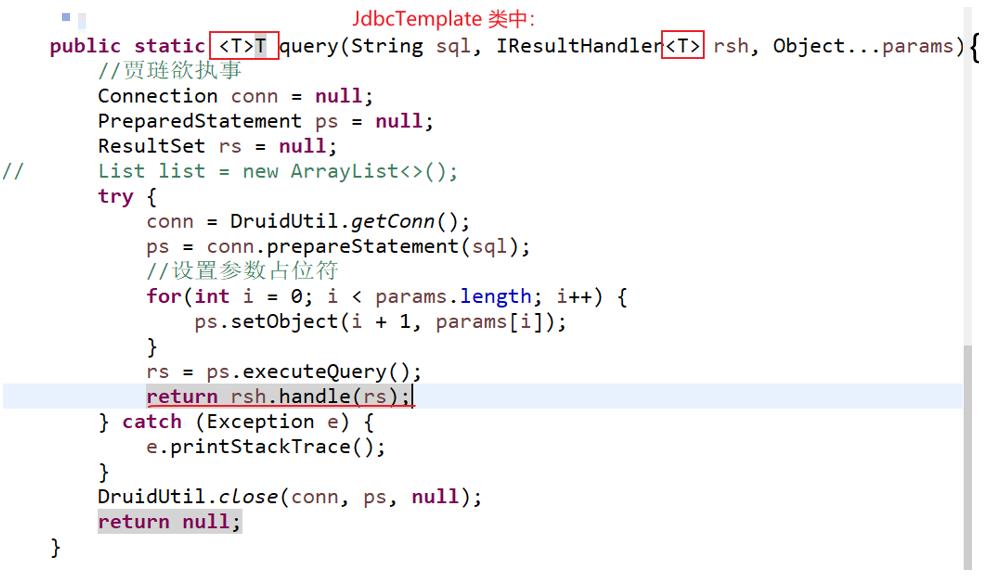
☆ 隐蔽性不合理的设计:重构一开始设计jdbcTemplate中查询模板,返回的结果为List集合就不太合理,例如查询的是学生的总数量,就一个整型数值的结果,没必要存储到List集合,然后再取出来。
☆ 解决:泛型
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
☆ 让我们回到问题☆ :模板中查询方法结果集处理写死了:
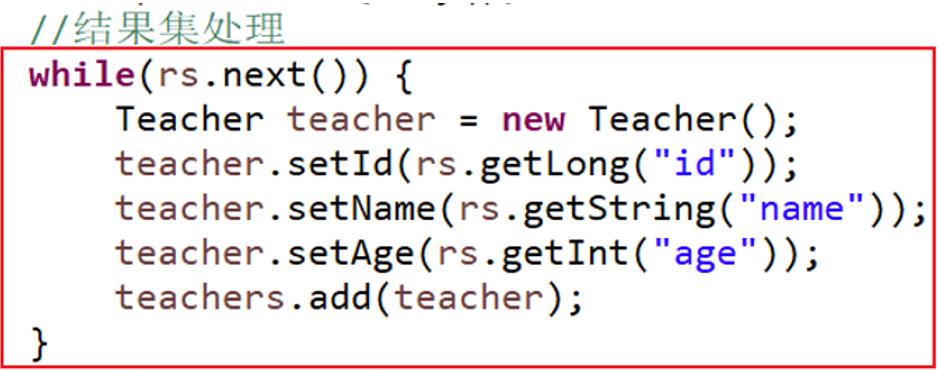
■ 分析:
- 上面我们采用的解决方法是:把结果集的处理行为交个每个对象的DAO实现类来做
【为了避免不同的DAO 实现类定义的处理结果集的方法名不同,我们定义了一个接口 IResultSetHandler来规范】
+ 以及通过了泛型解决了隐蔽设计中的不合理问题(重构一开始设计jdbcTemplate中查询模板,返回的结果为List集合就不太合理)
- 但是交给每个DAO实现类来做,则有多少个DAO实现类就需要定义多少个具体的结果集处理类,而且结果集处理的步骤都是相同的,【步骤重复----解决:编写一个通用的结果处理器类】
□ 结果集处理的步骤:
① 创建对应类的一个对象;
② 取出结果集中当前光标所在行的某一列的数据;
③ 调用该对象的setter方法,把某一列的数据设置进去。
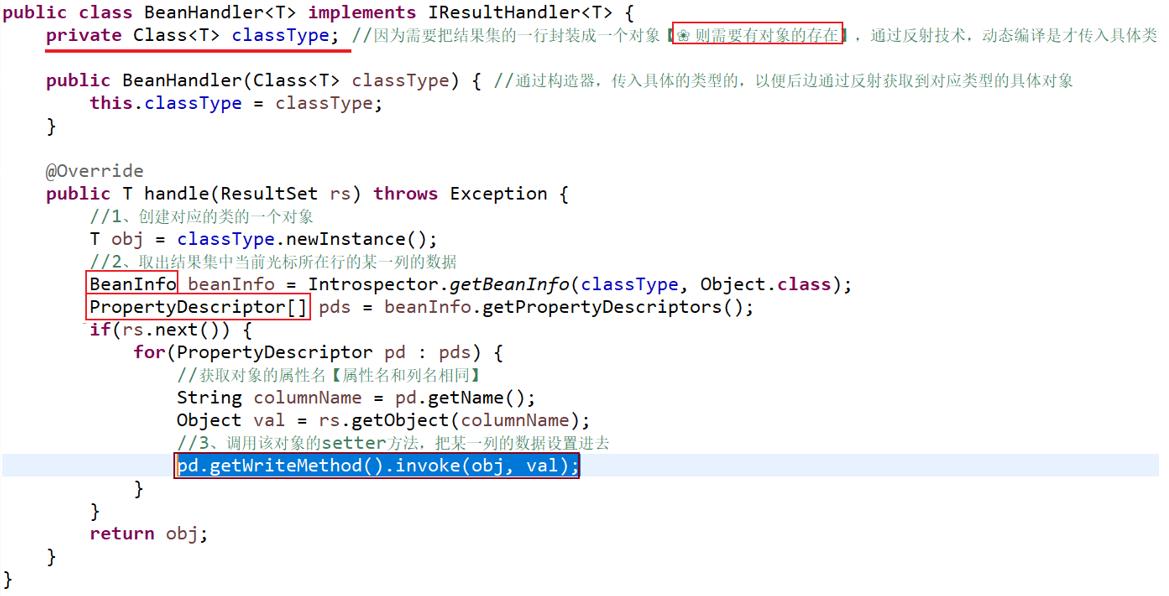
❀解决:编写通用结果集处理器类【通过反射的子集javaBeans (即java.beans 接口) 实现】
--- 因为之前写死的是因为直接把处理结果集写成了具体对象-----通过反射技术,动态编译(这里采用反射的子集 java.beans).
----可以把不同表中的每一行数据,封装成不同类型的对象;
■注意/规范:
1、规定表中的列名必须和对象的属性名相同;
2、规定表中的类型必须和java中的类型匹配。
|
■ 使用java.beans 来解决该问题的步骤: ① 通过反射,类.newInstance() 创建一个对应类的对象obj; ② 创建BeanInfo 对象(即javaBean的实例):通过Introspector.getBeanInfo(类,Object.class); ③ 通过BeanInfo对象.getPropertyDescriptors(),获取到 javaBean对象中的所有的属性,存储到 PropertiesDescriptors[ ] 数组中(PropertiesDesciptors--属性描述器) ④ 遍历获取到各个属性名,相应的得到结果集的列的值val,然后(调用该对象setter方法,把某一列的数设置进行),即 通过属性描述器 Properties对象.getWriteMethod().invoke(obj对象, val ); |
以上是关于JDBC第三天~JDBC之事务批处理自动生成主键连接池重构设计的主要内容,如果未能解决你的问题,请参考以下文章
spring3: 对JDBC的支持 之 Spring提供的其它帮助 SimpleJdbcInsert/SimpleJdbcCall/SqlUpdate/JdbcTemplate 生成主键/批量处理(