[源码解析] PyTorch 分布式 ----- DistributedDataParallel 之进程组
Posted 罗西的思考
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[源码解析] PyTorch 分布式 ----- DistributedDataParallel 之进程组相关的知识,希望对你有一定的参考价值。
[源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
0x00 摘要
本文是 PyTorch 分布式系列的第七篇, 介绍 DistributedDataParallel 所依赖的进程组概念。
本系列其他文章如下:
[源码解析]PyTorch如何实现前向传播(1) --- 基础类(上)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎
[源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构
[源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 分布式(1)------历史和概述
[源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[源码解析] PyTorch 分布式(4)------分布式应用基础概念
[源码解析] PyTorch分布式(5) ------ DistributedDataParallel 总述&如何使用
[源码解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
0x01 回顾
1.1 基础概念
关于分布式通信,PyTorch 提供的几个概念是:进程组,后端,初始化,Store。
- 进程组 :DDP是真正的分布式训练,可以使用多台机器来组成一次并行运算的任务。为了能够让 DDP 的各个worker之间通信,PyTorch 设置了进程组这个概念。
- 后端 :后端这个概念是一个逻辑上的概念。本质上后端是一种IPC通信机制。对于用户来说,就是采用那种方式来进行集合通信,从代码上看,就是走什么流程(一系列流程),以及后端使用 ProcessGroupMPI 还是 ProcessGroupGloo .....。
- 初始化 : 虽然有了后端和进程组的概念,但是如何让 worker 在建立进程组之前发现彼此? 这就需要一种初始化方法来告诉大家传递一个信息:如何联系到其它机器上的进程?
- Store : 可以认为是分布式键值存储,这个存储在组中的进程之间共享信息以及初始化分布式包 (通过显式创建存储来作为
init_method的替代)。
1.2 初始化进程组
在调用任何 DDP 其他方法之前,需要使用torch.distributed.init_process_group()进行初始化进程组。
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
import os
def setup(rank, world_size):
os.environ[\'MASTER_ADDR\'] = \'localhost\'
os.environ[\'MASTER_PORT\'] = \'12355\'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
该方法会初始化默认分布式进程组和分布式包。此方法会阻塞,直到所有进程都加入,函数定义如下:
init_process_group ( backend ,
init_method = None ,
timeout = default_pg_timeout ,
world_size =- 1 ,
rank =- 1 ,
store = None ,
group_name = \'\' ,
pg_options = None )
初始化进程组有两种主要方法:
- 明确指定 store,rank 和 world_size。
- 指定 init_method(一个 URL 字符串),它指示在哪里/如何发现对等点。
如果两者都没有指定,init_method则假定为“env://”。
因此大家可以看到,store 和 init_method 是互斥的。
参数具体如下:
- 后端 – 要使用的后端。有效值包括
mpi,gloo,和nccl。该字段应作为小写字符串(例如"gloo")给出,也可以通过Backend属性(例如Backend.GLOO)访问 。如果在nccl后端每台机器上使用多个进程,则每个进程必须对其使用的每个 GPU 具有独占访问权限,因为在进程之间共享 GPU 可能会导致死锁。 - init_method – 指定如何初始化进程组的 URL。如果未指定
init_method或store指定,则默认为“env://” 。与store互斥。 - world_size – 参与作业的进程数。如果
store指定,则 world_size 为必需。 - rank – 当前进程的等级(它应该是一个介于 0 和
world_size-1之间的数字)。如果store指定,则 rank 为必需。 - store – 所有 worker 都可以访问的键/值存储,用于交换连接/地址信息。与
init_method互斥。 - timeout – 针对进程组执行的操作超时。默认值等于 30 分钟。这适用于
gloo后端。对于nccl,这仅在环境变量NCCL_BLOCKING_WAIT或NCCL_ASYNC_ERROR_HANDLING设置为 1 时 适用。 - group_name – 组名。
- pg_options ( Process Group Options , optional ) – 进程组选项,指定在构建特定进程组期间需要传入哪些附加选项。
0x02 概念与设计
2.1 功能
默认情况下,集合通信在默认组(也称为world)上运行,并要求所有进程都进入分布式函数调用。但是,一些工作可以从更细粒度的通信中受益。这就是分布式组发挥作用的地方。new_group() 函数可用于创建一个新分布式组,这个新组是所有进程的任意子集。new_group() 返回一个不透明的组句柄,此句柄可以作为group参数提供给所有集合函数(集合函数是分布式函数,用于在某些编程模式中交换信息)。
2.2 本质
抛开概念,从代码看其本质。进程组就是给每一个训练的 process 建立一个通信thread。主线程(计算线程)在前台进行训练,这个通信 thread 在后台做通信。我们以 ProcessGroupMPI 为例,是在通信线程之中另外添加了一个 queue,做buffer 和 异步处理。这样,进程组中所有进程都可以组成一个集体在后台进行集合通信操作。
比如下面,左侧worker之中就有两个线程,计算线程负责计算梯度,然后要求通信线程与其它worker进行交换梯度。
+---------------------------------------------------------------+ +--------------+
| Worker Process | | Other Worker |
| | | |
| +----------------------+ +-----------------------+ | | +----------+ |
| | Computation thread | | Communication thread | | | | Comm | |
| | | | | | | | thread | |
| | | | | | | | | |
| | Main Thread | | workerThread_ | | | | | |
| | | | | | | | | |
| | | | | | | | | |
| | Gradient computation | | | | | | | |
| | + | | | | | | | |
| | | | | | + | + | | | |
| | | | | | /| | |\\ | | | |
| | v | /|_|\\ | | / +-+----+ \\ | | | |
| | Does All+Reduce |/ grad\\| Does communication |/ Gradient \\| | | |
| | |\\ _ /| |\\ /| | | |
| | | \\| |/ | | \\ +-+----+ / | | | |
| | | | | \\| | |/ | | | |
| | | | | + | + | | | |
| | | | | | | | | |
| | | | | | | | | |
| +----------------------+ +-----------------------+ | | +----------+ |
| | | |
+---------------------------------------------------------------+ +--------------+
0x03 使用
既然知道了进程组的本质,我们接下来看看如何使用进程组。
首先,在 _ddp_init_helper 之中会生成 dist.Reducer,进程组会作为 Reducer 的参数之一传入。
def _ddp_init_helper(self, parameters, expect_sparse_gradient, param_to_name_mapping):
"""
Initialization helper function that does the following:
(1) bucketing the parameters for reductions
(2) resetting the bucketing states
(3) registering the grad hooks
(4) Logging constructin-time DDP logging data
(5) passing a handle of DDP to SyncBatchNorm Layer
"""
self.num_iterations = 0
# The bucket size limit is specified in the constructor.
# Additionally, we allow for a single small bucket for parameters
# that are defined first, such that their gradients don\'t spill into
# a much larger bucket, adding unnecessary latency after gradient
# computation finishes. Experiments showed 1MB is a reasonable value.
bucket_indices = dist._compute_bucket_assignment_by_size(
parameters[0],
[dist._DEFAULT_FIRST_BUCKET_BYTES, self.bucket_bytes_cap],
expect_sparse_gradient[0],
)
# Note: reverse list of buckets because we want to approximate the
# order in which their gradients are produced, and assume they
# are used in the forward pass in the order they are defined.
self.reducer = dist.Reducer(
parameters,
list(reversed(bucket_indices)),
self.process_group, # 这里使用了
expect_sparse_gradient,
self.bucket_bytes_cap,
self.find_unused_parameters,
self.gradient_as_bucket_view,
param_to_name_mapping,
)
其次,在 Reducer 构建函数之中,会把进程组配置给 Reducer 的成员变量 process_group_ 之上。
Reducer::Reducer(
std::vector<std::vector<at::Tensor>> replicas,
std::vector<std::vector<size_t>> bucket_indices,
c10::intrusive_ptr<c10d::ProcessGroup> process_group,
std::vector<std::vector<bool>> expect_sparse_gradients,
int64_t bucket_bytes_cap,
bool find_unused_parameters,
bool gradient_as_bucket_view,
std::unordered_map<size_t, std::string> paramNames)
: replicas_(std::move(replicas)),
process_group_(std::move(process_group)), // 在这里
最后,当需要对梯度做 all-reduce 时候,则会调用 process_group_->allreduce(tensors) 进行处理。
现在,我们就知道如何使用进程组了。
void Reducer::all_reduce_bucket(Bucket& bucket) {
std::vector<at::Tensor> tensors;
tensors.reserve(bucket.replicas.size());
for (const auto& replica : bucket.replicas) {
tensors.push_back(replica.contents);
}
if (comm_hook_ == nullptr) {
bucket.work = process_group_->allreduce(tensors); // 这里会进行调用
} else {
GradBucket grad_bucket(
next_bucket_,
tensors[0],
// Since currently we do not support single-process multiple-device
// mode, we can assume only one replica in the bucket.
bucket.replicas[0].offsets,
bucket.replicas[0].lengths,
bucket.replicas[0].sizes_vec);
bucket.future_work = comm_hook_->runHook(grad_bucket);
}
}
0x04 构建
4.1 Python 世界
4.1.1 rendezvous
从 init_process_group 源码之中看,几种构建实现在细节上有所不同,我们只是看gloo和mpi。
-
gloo利用 rendezvous 设置了master地址。
-
MPI不需要 rendezvous,而是利用mpirun启动。
两种方法都生成了一个 ProcessGroup 赋值给 default_pg,然后用 default_pg 设置 GroupMember.WORLD。
def _update_default_pg(pg):
GroupMember.WORLD = group.WORLD = pg
具体 init_process_group 代码如下:
def init_process_group(backend,
init_method=None,
timeout=default_pg_timeout,
world_size=-1,
rank=-1,
store=None,
group_name=\'\',
pg_options=None):
"""
Initializes the default distributed process group, and this will also
initialize the distributed package.
There are 2 main ways to initialize a process group:
1. Specify ``store``, ``rank``, and ``world_size`` explicitly.
2. Specify ``init_method`` (a URL string) which indicates where/how
to discover peers. Optionally specify ``rank`` and ``world_size``,
or encode all required parameters in the URL and omit them.
If neither is specified, ``init_method`` is assumed to be "env://".
"""
global _pg_group_ranks
global _backend
global _default_pg_init_method
if store is not None:
assert world_size > 0, \'world_size must be positive if using store\'
assert rank >= 0, \'rank must be non-negative if using store\'
elif init_method is None:
init_method = "env://"
backend = Backend(backend)
if backend == Backend.MPI:
default_pg = _new_process_group_helper( # 生成了一个 ProcessGroup 赋值给 default_pg
-1,
-1,
[],
Backend.MPI,
None,
group_name=group_name,
timeout=timeout)
_update_default_pg(default_pg) # 用 default_pg 设置 GroupMember.WORLD
else:
# backward compatible API
if store is None:
rendezvous_iterator = rendezvous( # 先生成一个store
init_method, rank, world_size, timeout=timeout
)
store, rank, world_size = next(rendezvous_iterator)
store.set_timeout(timeout)
default_pg = _new_process_group_helper( # 再进行构建 ProcessGroup
world_size,
rank,
[],
backend,
store,
pg_options=pg_options,
group_name=group_name,
timeout=timeout)
_update_default_pg(default_pg) # 用 default_pg 设置 GroupMember.WORLD
_pg_group_ranks[GroupMember.WORLD] = {i: i for i in range(GroupMember.WORLD.size())} # type: ignore[attr-defined, index]
_backend = _pg_map[GroupMember.WORLD][0] # type: ignore[index]
_default_pg_init_method = init_method
# barrier at the end to ensure that once we return from this method, all
# process groups including global variables are updated correctly on all
# ranks.
if backend == Backend.MPI:
# MPI backend doesn\'t use store.
barrier()
else:
# Use store based barrier here since barrier() used a bunch of
# default devices and messes up NCCL internal state.
_store_based_barrier(rank, store, timeout)
# Set sequence numbers for gloo and nccl process groups.
if get_backend(default_pg) in [Backend.GLOO, Backend.NCCL]:
default_pg._set_sequence_number_for_group()
4.1.2 _new_process_group_helper
各种后端都会使用 _new_process_group_helper 进行具体构建,_new_process_group_helper 其实就是调用了不同的C++实现,比如 ProcessGroupGloo, ProcessGroupMPI, ProcessGroupNCCL。
def _new_process_group_helper(world_size,
rank,
group_ranks,
backend,
store,
pg_options=None,
group_name=None,
timeout=default_pg_timeout):
"""
Create a new distributed process group.
This function must be called by ALL processes in the global group, even if
the calling process is not part of the newly created group. In that case,
this function returns GroupMember.NON_GROUP_MEMBER.
This function is called with ``group_ranks == []`` for the default group.
"""
global _pg_map
global _group_count
global _pg_names
if not group_name:
group_name = str(_group_count)
_group_count += 1
# The list of group ranks is empty if we\'re creating the default group.
is_default_group = (len(group_ranks) == 0)
backend = Backend(backend)
pg: Union[ProcessGroupGloo, ProcessGroupMPI, ProcessGroupNCCL]
if backend == Backend.MPI:
pg = ProcessGroupMPI.create(group_ranks) # 构建了 ProcessGroupMPI
if not pg:
return GroupMember.NON_GROUP_MEMBER
_pg_map[pg] = (Backend.MPI, None)
_pg_names[pg] = group_name
else:
# If this is a subgroup (which means group_ranks is specified),
# we check if the current process is a member of the new group.
if not is_default_group:
global_rank = _get_default_group().rank()
if global_rank not in group_ranks:
return GroupMember.NON_GROUP_MEMBER
# Use the group name as prefix in the default store, such that
# a single store can be reused by multiple groups.
prefix_store = PrefixStore(group_name, store)
if backend == Backend.GLOO:
pg = ProcessGroupGloo( # 构建了 ProcessGroupGloo
prefix_store,
rank,
world_size,
timeout=timeout)
_pg_map[pg] = (Backend.GLOO, store)
_pg_names[pg] = group_name
elif backend == Backend.NCCL:
if pg_options is not None:
assert isinstance(pg_options, ProcessGroupNCCL.Options), \\
"Expected pg_options argument to be of type ProcessGroupNCCL.Options"
else:
# default pg_options for NCCL
pg_options = ProcessGroupNCCL.Options()
pg_options.is_high_priority_stream = False
pg_options._timeout = timeout
pg = ProcessGroupNCCL( # 构建了 ProcessGroupNCCL
prefix_store,
rank,
world_size,
pg_options)
_pg_map[pg] = (Backend.NCCL, store)
_pg_names[pg] = group_name
else:
pg = getattr(Backend, backend.upper())(
prefix_store,
rank,
world_size,
timeout)
_pg_map[pg] = (backend, store)
_pg_names[pg] = group_name
return pg
目前流程如下:
+
|
|
v
init_process_group
+
|
|
+------------+-------------+
| |
| |
v v
Backend.MPI Backend.GLOO & Backend.NCCL
+ +
| |
| |
| v
| store = rendezvous()
| +
| |
| |
+------------+-------------+
|
|
v
_new_process_group_helper
+
|
|
|
+------------------------------------------------------+
| | |
| | |
v v v
ProcessGroupMPI ProcessGroupGloo(store) ProcessGroupNCCL(store)
4.1.3
我们以 ProcessGroupMPI 为例来看看,可以看到ProcessGroupMPI的基类是ProcessGroup。
class ProcessGroupMPI(ProcessGroup):
def __init__(
self,
rank: int,
size: int,
pgComm: int,
): ...
@staticmethod
def create(ranks: List[int]) -> ProcessGroupMPI: ...
ProcessGroup 定义了若干集合通信函数,但是均未实现,不过从其注释之中,我们可以看到派生类会有多种重载实现。
class ProcessGroup(__pybind11_builtins.pybind11_object):
# no doc
def allgather(self, *args, **kwargs): # real signature unknown; restored from __doc__
"""
allgather(*args, **kwargs)
Overloaded function.
1. allgather(self: torch._C._distributed_c10d.ProcessGroup, output_tensors: List[List[at::Tensor]], input_tensors: List[at::Tensor], opts: torch._C._distributed_c10d.AllgatherOptions = <torch._C._distributed_c10d.AllgatherOptions object at 0x000001A9460233F0>) -> c10d::ProcessGroup::Work
2. allgather(self: torch._C._distributed_c10d.ProcessGroup, output_tensors: List[at::Tensor], input_tensor: at::Tensor) -> c10d::ProcessGroup::Work
"""
pass
def allgather_coalesced(self, output_lists, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__
""" allgather_coalesced(self: torch._C._distributed_c10d.ProcessGroup, output_lists: List[List[at::Tensor]], input_list: List[at::Tensor], opts: torch._C._distributed_c10d.AllgatherOptions = <torch._C._distributed_c10d.AllgatherOptions object at 0x000001A946023370>) -> c10d::ProcessGroup::Work """
pass
def allreduce(self, *args, **kwargs): # real signature unknown; restored from __doc__
"""
allreduce(*args, **kwargs)
Overloaded function.
1. allreduce(self: torch._C._distributed_c10d.ProcessGroup, tensors: List[at::Tensor], opts: torch._C._distributed_c10d.AllreduceOptions = <torch._C._distributed_c10d.AllreduceOptions object at 0x000001A946023570>) -> c10d::ProcessGroup::Work
2. allreduce(self: torch._C._distributed_c10d.ProcessGroup, tensors: List[at::Tensor], op: torch._C._distributed_c10d.ReduceOp = <ReduceOp.SUM: 0>) -> c10d::ProcessGroup::Work
3. allreduce(self: torch._C._distributed_c10d.ProcessGroup, tensor: at::Tensor, op: torch._C._distributed_c10d.ReduceOp = <ReduceOp.SUM: 0>) -> c10d::ProcessGroup::Work
"""
pass
而无论哪个ProcessGroup的派生类,都指向了C++世界,比如在 torch/csrc/distributed/c10d/init.cpp 之中有如下代码:
// Define static create function instead of a constructor, because
// this function may return null. This happens if this process is not
// part of a sub group that is to be created.
processGroupMPI.def_static(
"create",
[](std::vector<int> ranks) {
return ::c10d::ProcessGroupMPI::createProcessGroupMPI(ranks);
},
py::call_guard<py::gil_scoped_release>());
因此可见,最后调用到的是 createProcessGroupMPI,于是我们直接去C++世界看看。
4.2 C++ 世界
4.2.1 ProcessGroupMPI 定义
ProcessGroupMPI 定义位于 torch/lib/c10d/ProcessGroupMPI.cpp。这里相当于做了一个工作队列,以及异步操作。几个注意点如下:
- ProcessGroupMPI 类上的所有函数都应在组中的进程之间以相同的顺序调用。这是我们能够保证跨进程匹配相同调用的唯一方法。
- ProcessGroupMPI 类提供的所有MPI函数都在工作线程上异步调度。因此,ProcessGroupMPI 依赖于MPI实现,该实现用于提供 MPI_THREAD_SERIALIZED 的最小线程支持值。也就是说,进程可以是多线程的,多个线程可以进行MPI调用,但一次只能进行一个:MPI调用不是从两个不同的线程同时进行的(所有MPI调用都是序列化的)。但是,如果使用 MPI_THREAD_SERIALIZED,ProcessGroupMPI将只支持单个进程组。换句话说,全局创建的进程组不能超过1个。
- 如果希望使用多个ProcessGroupMPI,它要求MPI实现的线程支持值为MPI\\u thread\\u multiple,也就是说,多个线程可以调用MPI,没有任何限制。
- 还要注意,ProcessGroupMPI只支持单个张量操作。换句话说,输入张量向量的大小应始终为1。
- 如果使用的MPI是CUDA-aware MPI,则可以支持CUDA tensor,并且ProcessGroupMPI将自动检测此支持。
// ProcessGroupMPI implements MPI bindings for c10d.
//
// All functions on this class are expected to be called in the same
// order across processes in the group. This is the only way that we
// can guarantee to match up the same calls across processes.
//
// All MPI functions provided by this class is asynchronously scheduled on a
// Worker thread. Therefore, ProcessGroupMPI requires the MPI implementation
// that is used to have a minimum thread support value of MPI_THREAD_SERIALIZED.
// That is, The process may be multi-threaded, and multiple threads may make
// MPI calls, but only one at a time: MPI calls are not made concurrently from
// two distinct threads (all MPI calls are serialized). However, with
// MPI_THREAD_SERIALIZED, ProcessGroupMPI will only support a singe process
// group. In other words, no more than 1 process group can be created globally.
//
// If you would like to use multiple ProcessGroupMPI, it requres your MPI
// implemenation to have a thread support value of MPI_THREAD_MULTIPLE, that is,
// multiple threads may call MPI, with no restriction.
//
// Also note that ProcessGroupMPI only supports a single Tensor operation. In
// other words, the size of the input Tensor vector should always be 1.
//
// CUDA tensor can be supported if the MPI used is CUDA-aware MPI, and
// ProcessGroupMPI will automatically detect this support.
class ProcessGroupMPI : public ProcessGroup {
public:
class WorkMPI : public ProcessGroup::Work {
public:
explicit WorkMPI(
std::vector<at::Tensor> outputTensors,
const char* profilingTitle = nullptr,
const c10::optional<std::vector<at::Tensor>>& inputTensors =
c10::nullopt)
: ProcessGroup::Work(-1, OpType::UNKNOWN, profilingTitle, inputTensors),
outputTensors_(std::move(outputTensors)),
future_(c10::make_intrusive<at::ivalue::Future>(
c10::ListType::create(c10::TensorType::get()))) {}
std::vector<at::Tensor> result() override;
c10::intrusive_ptr<c10::ivalue::Future> getFuture() override;
protected:
friend class ProcessGroupMPI;
private:
void finishWorkMPI();
void finishWorkMPIError(std::exception_ptr eptr);
std::vector<at::Tensor> outputTensors_;
c10::intrusive_ptr<at::ivalue::Future> future_;
};
class AsyncWork : public ProcessGroup::Work {
public:
AsyncWork(
MPI_Request request,
std::vector<at::Tensor> outputTensors,
const char* profilingTitle = nullptr,
const c10::optional<std::vector<at::Tensor>>& inputTensors =
c10::nullopt);
virtual ~AsyncWork();
bool isCompleted() override;
bool isSuccess() const override;
int sourceRank() const override;
bool wait(std::chrono::milliseconds timeout = kUnsetTimeout) override;
void abort() override;
std::vector<at::Tensor> result() override;
protected:
void populateException();
private:
const std::vector<at::Tensor> outputTensors_;
MPI_Request request_;
MPI_Status status_;
};
// Constructor will spawn up the worker thread loop
explicit ProcessGroupMPI(int rank, int size, MPI_Comm pgComm);
virtual ~ProcessGroupMPI();
protected:
using WorkType =
std::tuple<std::unique_ptr<WorkEntry>, c10::intrusive_ptr<WorkMPI>>;
// Worker thread loop
void runLoop();
// Helper function that is called by the destructor
void destroy();
c10::intrusive_ptr<ProcessGroup::Work> enqueue(
std::unique_ptr<WorkEntry> entry,
const char* profilingTitle = nullptr,
const c10::optional<std::vector<at::Tensor>>& inputTensors = c10::nullopt);
bool stop_;
std::mutex pgMutex_;
std::thread workerThread_;
std::deque<WorkType> queue_;
std::condition_variable queueProduceCV_;
std::condition_variable queueConsumeCV_;
// Global states
static void initMPIOnce();
static void mpiExit();
static std::once_flag onceFlagInitMPI;
static std::mutex pgGlobalMutex_;
static int mpiThreadSupport_;
MPI_Comm pgComm_;
};
4.2.2 初始化
createProcessGroupMPI 方法完成了进程组的初始化,其主要是调用了 MPI 编程常见套路,比如initMPIOnce,MPI_Comm_create,MPI_Barrier之类。
c10::intrusive_ptr<ProcessGroupMPI> ProcessGroupMPI::createProcessGroupMPI(
std::vector<int> ranks) {
// Once initialization
initMPIOnce();
MPI_Comm groupComm = MPI_COMM_WORLD;
int rank = -1;
int size = -1;
{
std::lock_guard<std::mutex> globalLock(pgGlobalMutex_);
// If no ranks are specified, assume we\'re creating the root group
if (!ranks.empty()) {
MPI_Group worldGroup;
MPI_Group ranksGroup;
MPI_CHECK(MPI_Comm_group(MPI_COMM_WORLD, &worldGroup));
MPI_CHECK(
MPI_Group_incl(worldGroup, ranks.size(), ranks.data(), &ranksGroup));
constexpr int kMaxNumRetries = 3;
bool groupComm_updated = false;
MPI_Barrier(MPI_COMM_WORLD);
for (int i = 0; i < kMaxNumRetries; ++i) {
if (MPI_Comm_create(MPI_COMM_WORLD, ranksGroup, &groupComm)) {
groupComm_updated = true;
break;
}
}
MPI_CHECK(groupComm_updated);
MPI_CHECK(MPI_Group_free(&worldGroup));
MPI_CHECK(MPI_Group_free(&ranksGroup));
}
// Fetch rank and world size for this group (MPI_COMM_WORLD or new)
if (groupComm != MPI_COMM_NULL) {
MPI_CHECK(MPI_Comm_rank(groupComm, &rank));
MPI_CHECK(MPI_Comm_size(groupComm, &size));
}
}
// If this process is not part of the group, we don\'t construct a
// process group instance. This is in line with the semantics of the
// other process group types.
if (groupComm == MPI_COMM_NULL) {
return c10::intrusive_ptr<ProcessGroupMPI>(); // 生成
}
return c10::make_intrusive<ProcessGroupMPI>(rank, size, groupComm); // 生成
}
4.2.2.1 initMPIOnce
调用了 MPI_Init_thread API 初始化了 MPI 执行环境。
void ProcessGroupMPI::initMPIOnce() {
// Initialize MPI environment
std::call_once(onceFlagInitMPI, []() {
MPI_CHECK(MPI_Init_thread(
nullptr, nullptr, MPI_THREAD_SERIALIZED, &mpiThreadSupport_));
if (mpiThreadSupport_ < MPI_THREAD_SERIALIZED) {
throw std::runtime_error(
"Used MPI implementation doesn\'t have the "
"minimum level of threading support: "
"MPI_THREAD_SERIALIZED. This is required by "
"c10d package");
}
if (std::atexit(ProcessGroupMPI::mpiExit)) {
throw std::runtime_error("Fail to register the MPI exit handler");
}
});
4.2.2.2 ProcessGroupMPI
ProcessGroupMPI 构建方法之中 生成了 workerThread_,其运行 runLoop。
ProcessGroupMPI::ProcessGroupMPI(int rank, int size, MPI_Comm pgComm)
: ProcessGroup(rank, size), stop_(false), pgComm_(pgComm) {
if (pgComm_ == MPI_COMM_NULL) {
throw std::runtime_error("pgComm_ must not be MPI_COMM_NULL");
}
// Start the worker thread accepting MPI calls
workerThread_ = std::thread(&ProcessGroupMPI::runLoop, this);
}
4.2.3 运行
4.2.3.1 执行封装
这里有两个封装,WorkEntry 封装计算执行,WorkMPI封装计算执行结果(因为计算是异步的)。具体如下:
WorkEntry 是执行方法的封装,或者说每次需要执行的集合通信操作,都要封装在这里。
struct WorkEntry {
explicit WorkEntry(
std::vector<at::Tensor>* srcPtr,
std::vector<at::Tensor>* dstPtr,
std::function<void(std::unique_ptr<WorkEntry>&)> run)
: dst(dstPtr ? *dstPtr : std::vector<at::Tensor>()),
run(std::move(run)) {
if (srcPtr) {
src = *srcPtr;
}
}
// Not copyable
WorkEntry(const WorkEntry&) = delete;
// Not copy assignable
WorkEntry& operator=(const WorkEntry&) = delete;
// For input and output tensors (in-place), we will always use src
std::vector<at::Tensor> src;
// Copy of user provided outputs.
const std::vector<at::Tensor> dst;
// src rank returned, for recv only
int* srcRank = nullptr;
std::function<void(std::unique_ptr<WorkEntry>&)> run;
};
WorkMPI 是执行结果的封装。
class WorkMPI : public ProcessGroup::Work {
public:
explicit WorkMPI(
std::vector<at::Tensor> outputTensors,
const char* profilingTitle = nullptr,
const c10::optional<std::vector<at::Tensor>>& inputTensors =
c10::nullopt)
: ProcessGroup::Work(-1, OpType::UNKNOWN, profilingTitle, inputTensors),
outputTensors_(std::move(outputTensors)),
future_(c10::make_intrusive<at::ivalue::Future>(
c10::ListType::create(c10::TensorType::get()))) {}
std::vector<at::Tensor> result() override;
c10::intrusive_ptr<c10::ivalue::Future> getFuture() override;
protected:
friend class ProcessGroupMPI;
private:
void finishWorkMPI();
void finishWorkMPIError(std::exception_ptr eptr);
std::vector<at::Tensor> outputTensors_;
c10::intrusive_ptr<at::ivalue::Future> future_;
};
在往工作queue插入时候,实际插入的是二元组(WorkEntry, WorkMPI),我们后续会讲解如何使用。
4.2.3.2 allreduce
以allreduce 为例,看看如何处理。就是把 MPI_Allreduce 封装到 WorkEntry 之中,然后插入到 queue。
后续 runLoop 之中就是取出 WorkEntry,然后运行 MPI_Allreduce。
c10::intrusive_ptr<ProcessGroup::Work> ProcessGroupMPI::allreduce(
std::vector<at::Tensor>& tensors,
const AllreduceOptions& opts) {
checkSingleTensor(tensors);
std::function<void(std::unique_ptr<WorkEntry>&)> runFunc =
[opts, this](std::unique_ptr<WorkEntry>& entry) {
auto data = (entry->src)[0];
c10::DeviceGuard guard(data.device());
std::unique_lock<std::mutex> globalLock(pgGlobalMutex_);
MPI_CHECK(MPI_Allreduce( // 封装了此函数
MPI_IN_PLACE,
data.data_ptr(),
data.numel(),
mpiDatatype.at(data.scalar_type()),
mpiOp.at(opts.reduceOp),
pgComm_));
};
auto entry = std::make_unique<WorkEntry>(&tensors, &tensors, std::move(runFunc));
return enqueue(
std::move(entry),
"mpi:all_reduce",
c10::optional<std::vector<at::Tensor>>(tensors));
}
4.2.3.3 enqueue
enqueue 方法是往queue插入二元组(WorkEntry, WorkMPI),里面的 entry->dst 就是 计算结果存放到 WorkMPI 之中。
c10::intrusive_ptr<ProcessGroup::Work> ProcessGroupMPI::enqueue(
std::unique_ptr<WorkEntry> entry,
const char* profilingTitle,
const c10::optional<std::vector<at::Tensor>>& inputTensors) {
// 生成 WorkMPI,把 entry->dst 就是 计算结果存放到 WorkMPI 之中
auto work = c10::make_intrusive<WorkMPI>(entry->dst, profilingTitle, inputTensors);
std::unique_lock<std::mutex> lock(pgMutex_);
// 插入二元组
queue_.push_back(std::make_tuple(std::move(entry), work));
lock.unlock();
queueProduceCV_.notify_one();
return work;
}
4.2.3.4 runLoop
主循环runLoop方法就是不停的取出entry来处理。
void ProcessGroupMPI::runLoop() {
std::unique_lock<std::mutex> lock(pgMutex_);
while (!stop_) {
if (queue_.empty()) {
queueProduceCV_.wait(lock);
continue;
}
auto workTuple = std::move(queue_.front());
queue_.pop_front();
auto& workEntry = std::get<0>(workTuple); // 进行计算
auto& work = std::get<1>(workTuple); // 拿到WorkMPI
lock.unlock();
queueConsumeCV_.notify_one();
try {
workEntry->run(workEntry);
work->finishWorkMPI(); // 会等待WorkMPI的计算结果
} catch (...) {
work->finishWorkMPIError(std::current_exception());
}
lock.lock();
}
}
finishWorkMPI 会标示并且进行通知。
void ProcessGroupMPI::WorkMPI::finishWorkMPI() {
future_->markCompleted(at::IValue(outputTensors_));
finish();
}
基类代码如下:
void ProcessGroup::Work::finish(std::exception_ptr exception) {
std::unique_lock<std::mutex> lock(mutex_);
completed_ = true;
exception_ = exception;
if (recordFunctionEndCallback_) {
recordFunctionEndCallback_();
recordFunctionEndCallback_ = nullptr;
}
lock.unlock();
cv_.notify_all();
}
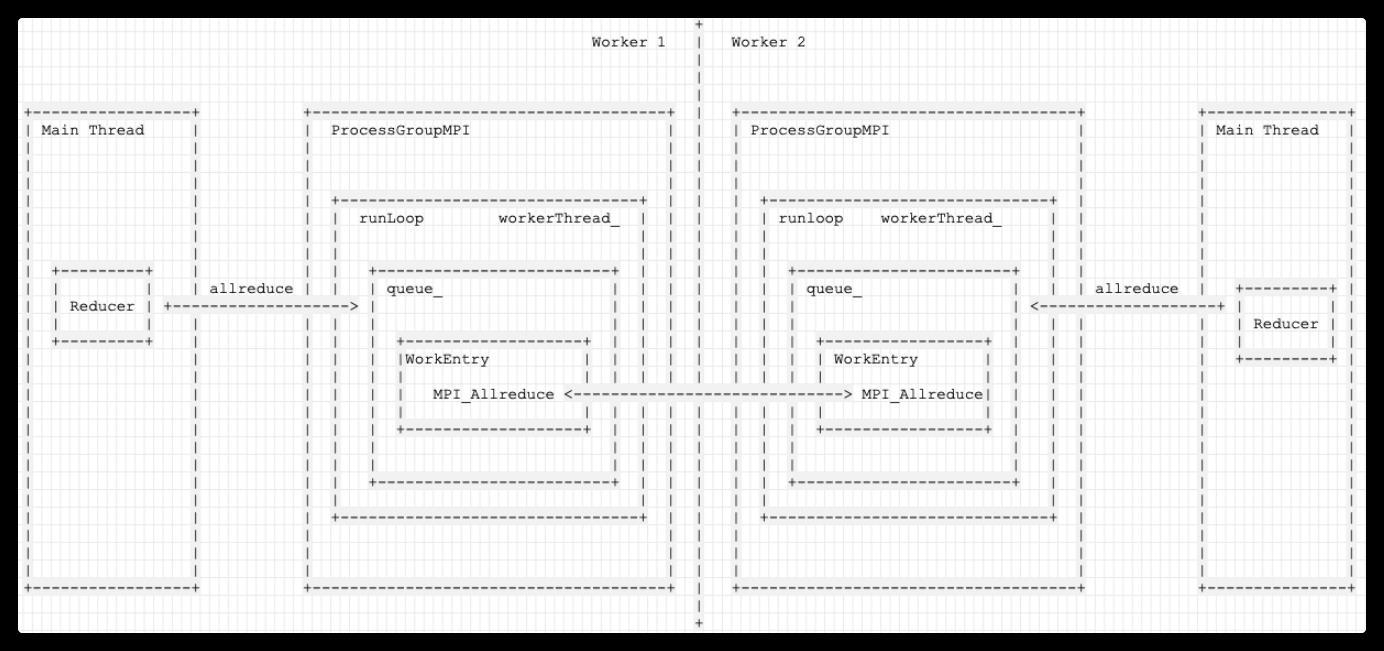
具体如下图:
+
Worker 1 | Worker 2
|
|
|
+-----------------+ +--------------------------------------+ | +------------------------------------+ +---------------+
| Main Thread | | ProcessGroupMPI | | | ProcessGroupMPI | | Main Thread |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | +--------------------------------+ | | | +------------------------------+ | | |
| | | | runLoop workerThread_ | | | | | runloop workerThread_ | | | |
| | | | | | | | | | | | |
| | | | | | | | | | | | |
| +---------+ | | | +-------------------------+ | | | | | +-----------------------+ | | | |
| | | | allreduce | | | queue_ | | | | | | | queue_ | | | allreduce | +---------+ |
| | Reducer | +-------------------> | | | | | | | | | <-------------------+ | | |
| | | | | | | | | | | | | | | | | | | Reducer | |
| +---------+ | | | | +-------------------+ | | | | | | | +-----------------+ | | | | | | |
| | | | | |WorkEntry | | | | | | | | | WorkEntry | | | | | +---------+ |
| | | | | | | | | | | | | | | | | | | | |
| | | | | | MPI_Allreduce <-----------------------------> MPI_Allreduce| | | | | |
| | | | | | | | | | | | | | | | | | | | |
| | | | | +-------------------+ | | | | | | | +-----------------+ | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | +-------------------------+ | | | | | +-----------------------+ | | | |
| | | | | | | | | | | | |
| | | +--------------------------------+ | | | +------------------------------+ | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
+-----------------+ +--------------------------------------+ | +------------------------------------+ +---------------+
|
|
+
手机如下:
4.4 封装
PyTorch 对各种 process group 做了封装,这样用户就可以调用 GroupMember.WORLD 来完成各种操作,但是用户是无感的。
def _get_default_group():
"""
Getting the default process group created by init_process_group
"""
if not is_initialized():
raise RuntimeError("Default process group has not been initialized, "
"please make sure to call init_process_group.")
return GroupMember.WORLD
又比如,在 torch/distributed/distributed_c10d.py 之中如下方法可以看到 all_to_all 和 all_gather 之类的函数,其注释有很详细的用法(这里因为篇幅所限略去),大家有兴趣可以自行学习。
def all_to_all(output_tensor_list,
input_tensor_list,
group=None,
async_op=False):
"""
Each process scatters list of input tensors to all processes in a group and
return gathered list of tensors in output list.
Args:
output_tensor_list (list[Tensor]): List of tensors to be gathered one
per rank.
input_tensor_list (list[Tensor]): List of tensors to scatter one per rank.
group (ProcessGroup, optional): The process group to work on. If None,
the default process group will be used.
async_op (bool, optional): Whether this op should be an async op.
Returns:
Async work handle, if async_op is set to True.
None, if not async_op or if not part of the group.
"""
if _rank_not_in_group(group):
return
opts = AllToAllOptions()
_check_tensor_list(output_tensor_list, "output_tensor_list")
_check_tensor_list(input_tensor_list, "input_tensor_list")
if group is None:
default_pg = _get_default_group()
work = default_pg.alltoall(output_tensor_list, input_tensor_list, opts)
else:
work = group.alltoall(output_tensor_list, input_tensor_list, opts)
if async_op:
return work
else:
work.wait()
all_gather 代码如下:
def all_gather(tensor_list,
tensor,
group=None,
async_op=False):
"""
Gathers tensors from the whole group in a list.
Complex tensors are supported.
Args:
tensor_list (list[Tensor]): Output list. It should contain
correctly-sized tensors to be used for output of the collective.
tensor (Tensor): Tensor to be broadcast from current process.
group (ProcessGroup, optional): The process group to work on. If None,
the default process group will be used.
async_op (bool, optional): Whether this op should be an async op
Returns:
Async work handle, if async_op is set to True.
None, if not async_op or if not part of the group
"""
_check_tensor_list(tensor_list, "tensor_list")
_check_single_tensor(tensor, "tensor")
if _rank_not_in_group(group):
return
tensor_list = [t if not t.is_complex() else torch.view_as_real(t) for t in tensor_list]
tensor = tensor if not tensor.is_complex() else torch.view_as_real(tensor)
if group is None:
default_pg = _get_default_group()
work = default_pg.allgather([tensor_list], [tensor])
else:
work = group.allgather([tensor_list], [tensor])
if async_op:
return work
else:
work.wait()
至此,进程组介绍完毕,下一篇我们分析DDP的论文,敬请期待。
0xFF 参考
pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel
https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
DISTRIBUTED TRAINING WITH UNEVEN INPUTS USING THE JOIN CONTEXT MANAGER
以上是关于[源码解析] PyTorch 分布式 ----- DistributedDataParallel 之进程组的主要内容,如果未能解决你的问题,请参考以下文章