Adaptive Particle Swarm Optimization
Posted 3cH0 - Nu1L
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Adaptive Particle Swarm Optimization相关的知识,希望对你有一定的参考价值。
Adaptive Particle Swarm Optimization
自适应粒子群算法
Zhi-Hui Zhan,Student Member , IEEE, Jun Zhang,Senior Member , IEEE, Y un Li,Member , IEEE, a n d
Henry Shu-Hung Chung,Senior Member , IEEE
2009
摘要:
本文提出了一种具有比经典粒子群优化(PSO)更好的搜索效率的自适应粒子群优化(APSO)。更重要的是,它可以以更快的收敛速度对整个搜索空间进行全局搜索。
APSO 包括两个主要步骤。
首先,通过评估种群分布和粒子适应度,执行实时进化状态估计程序以识别以下四种定义的进化状态之一,包括探索、开发、收敛、跳跃状态。它可以在运行时自动控制惯性权重、加速度系数等算法参数,以提高搜索效率和收敛速度。
然后,当进化状态被归类为收敛状态时,执行精英学习策略。该策略将作用于全局最佳粒子以跳出可能的局部最优。
APSO 已经在 12 个单峰和多峰基准函数上进行了全面评估。将研究参数适应和精英学习的影响。结果表明,APSO 在收敛速度、全局最优性、求解精度和算法可靠性方面大大提高了 PSO 范式的性能。由于 APSO 仅向 PSO 范式引入了两个新参数,因此不会引入额外的设计或实现复杂性。
I. INTRODUCTION
为了实现这两个目标,本文提出了一种系统的参数自适应策略和精英学习策略。为了实现自适应,首先设计了一种进化状态估计技术,从而根据已确定的进化状态,利用现有的惯性重量和加速度系数的研究成果,制定出自适应参数控制策略。
本文在已有的惯性权重[13]-[16]和加速度系数[17]-[20]参数设置技术的基础上,提出了一种系统的自适应方案。粒子群算法的参数不仅由ESE控制,还考虑了这些参数在不同状态下的不同影响。此外,从变异[23]、重置[25]、[26]或重新初始化[27]、[28]操作出发,本文提出ELS算法只在全局最优粒子上执行,并且只在收敛状态下执行。这不仅是因为收敛状态最需要ELS,还因为计算开销非常低。此外,自适应ELS将保持种群多样性,以跳出潜在的局部最优。此外,还将对粒子群算法范式中的各种拓扑结构进行测试,以验证APSO算法的有效性,并与其他改进的粒子群算法进行更全面的比较。
II. PSO AND ITS DEVELOPMENTS(粒子群算法及其发展)
A. PSO Framework
(PSO框架)
B. Current Developments of the PSO
(粒子群优化算法的发展现状)
III. ESE FOR PSO
A. Population Distribution Information in PSO(粒子群优化算法中的种群分布信息)
在收敛状态下,从全局最佳粒子到其他粒子的平均距离将是最小的,因为全局最佳粒子往往被群包围。相反,这个平均距离在跳出状态下最大,因为全局最好的可能会远离拥挤的蜂群。
B. ESE
Step 1: At the current position, calculate the mean distance
of each particle i to all the other particles.
(在当前位置,计算每个粒子 i 到其他所有粒子的平均距离)
平均距离可以用欧几里德公式来测量
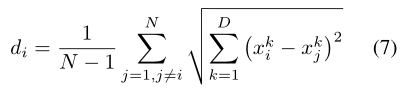
Step 2: Denote diof the globally best particle as dg. Compare all di’s, and determine the maximum and minimum distances dmaxand dmin.
(将全局最佳粒子的 di 表示为dg。比较所有di,并确定最大和最小距离dmax和dmin)
进化因子:
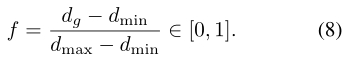
Step 3: Classify f into one of the four sets S1, S2, S3 and S4, which
represent the states of exploration, exploitation, convergence, and jumping out, respectively.
(将f归入S1、S2、S3和S4四个集合中的一个,分别代表探索、开发、收敛和跳跃状态)
状态转换将是不确定的和模糊的,并且不同的算法或应用可能表现出不同的转换特性。因此,建议采用模糊分类。
Case (a)—Exploration:探测
Case (b)—Exploitation:开发
Case (c)—Convergence:收敛
Case (d)—Jumping Out:跳跃
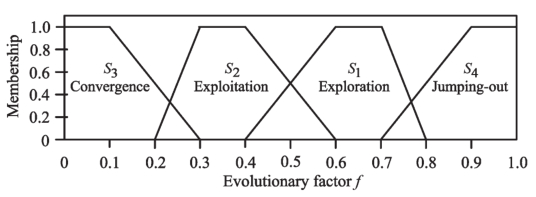
在过渡期,两个成员资格将被激活,并可以被归类为任何一个状态。对于最终分类,这里可以使用两种最常用的去模糊化技术中的任何一种,即,“单件”或“质心”方法[55]。本文采用单例方法,因为它比质心方法更有效,并且易于与状态转移规则库结合实现。
有了规则库,如果之前的状态是S4,则单例将挑出S1而不是S2,因为规则库(包含更改序列)决定了去模糊化时的决策。如果之前的状态是S1,则出于分类稳定性的考虑,也将其分类为S1,即不过度切换状态指示器。然而,如果之前的状态是S2或S3,则具有规则表的单例将把f分类到S2。
IV . APSO
A. Adaptive Control of PSO Parameters(粒子群算法参数的自适应控制)
1) Adaptation of the Inertia Weight(惯性权重的自适应)
利用粒子群算法中的惯性权重ω来平衡全局搜索能力和局部搜索能力。
在本文中,ω被初始化为0.9。由于ω不一定是随时间单调的,而是随 f 单调的,因此,ω将适应以 f 为特征的搜索环境。如前所述,在跳跃或探索状态下,较大的 f 和 ω 将有利于全局搜索。相反,当f较小时,检测到开发或收敛状态,因此,ω减小以利于局部搜索。
2) Control of the Acceleration Coefficients(加速度系数的控制)
基于以下思想,可以对加速度系数进行自适应控制。参数c1代表“自我认知”,它将粒子拉到它自己的历史最佳位置,帮助探索当地的利基环境,并保持种群的多样性。
参数c2代表推动群体收敛到当前全局最佳区域的“社会影响力”,有助于快速收敛。这是两种不同的学习机制,在不同的进化状态下应该给予不同的对待。在本文中,加速度系数被初始化为2.0,并根据进化状态进行自适应控制,并制定了如下策略。
Strategy 1—Increasing c1and Decreasing c2in an Exploration State(在探索状态下增加c1和减少c2)
重要的是在勘探状态下探索尽可能多的最优值。因此,增加c1和减少c2可以帮助粒子单独探索并达到它们自己的历史最佳位置,而不是聚集在可能与局部最优相关的当前最佳粒子周围。
Strategy 2—Increasing c1 Slightly and Decreasing c2 Slightly in an Exploitation State(在开发状态下稍微增加c1,稍微减少c2)
在这种状态下,粒子利用局部信息并朝着由每个粒子的历史最佳位置指示的可能的局部最优小生境进行分组。因此,缓慢增加c1并保持相对较大的值可以强调对pBesti的搜索和利用。同时,在这个阶段,全局最优粒子并不总是位于全局最优区域。因此,缓慢减小c2并保持较小的值可以避免局部最优解的欺骗。此外,开发状态更有可能出现在探索状态之后和收敛状态之前。因此,c1和c2的方向改变应该从探索状态略微改变为收敛状态。
Strategy 3—Increasing c1 Slightly and Increasing c2 Slightly in a Convergence State(在收敛状态下略微增加c1和略微增加c2)
在收敛状态下,群体似乎找到了全局最优区域,因此,应该强调c2的影响,以引导其他粒子到达可能的全局最优区域。因此,应该增加c2的值。另一方面,应减小c1的值,使种群快速收敛。然而,对表I中给出的12个基准函数进行优化的大量实验表明,这样的策略会过早地将这两个参数分别饱和到它们的下界和上界。结果是,群体会被当前最优区域强烈吸引,导致过早收敛,如果当前最优区域是局部最优,这是有害的。为了避免这种情况,c1和c2都略有增加。
注意,稍微增加两个加速度参数最终将具有与减小c1和增加c2相同的预期效果,由于c1和c2之和的上限为4.0(请参阅下一节中讨论的(12)),它们的值将绘制为2.0左右。
Strategy 4—Decreasing c1and Increasing c2 in a Jumping-Out State(在跳跃状态下减少c1并增加c2)
当全局最好的粒子从局部最优跳向更好的最优时,它很可能远离拥挤的集群。一旦这个新区域由一个粒子发现,成为(可能是新的)领导者,其他粒子应该跟随它,尽快飞往这个新的区域。一个较大的c2加上一个相对较小的 c1有助于达到这个目标。
3) Bounds of the Acceleration Coefficients(加速度系数的界)
如前所述,上述对加速度系数的调整不应过于突兀。因此,两代之间的最大增量或减量的界限是|ci(g+ 1) − ci(g)| ≤ δ, i = 1, 2。
B. Effects of Parameter Adaptation(参数适应的影响)
无论是单峰函数还是多峰函数,参数自适应确实大大加快了粒子群算法的速度。
当最好的粒子成为最好的粒子时,全局最好粒子的自我认知和社会影响力学习成分都几乎为零。此外,当惯性权小于1时,它的速度会变得越来越小。标准的学习机制并不能帮助BEST摆脱这个局部最优,因为它的速度接近于0。
C. ELS
GPSO和VPSO在Schwefel函数上单独使用参数自适应的失败表明,为了提高这些搜索算法的全局性,跳出机制是必要的。因此,本文设计了一种“ELS”算法,并将其应用于全局最优粒子,以帮助在搜索到收敛状态时跳出局部最优区域。
与其他粒子不同,全球领导者没有榜样可循。它需要新的动力来提高自己。因此,发展了一种基于扰动的ELS,以帮助BEST将自己推向一个潜在的更好的区域。如果找到了另一个更好的区域,那么其余的蜂群就会跟随领头羊跳出来,汇聚到新的区域。
ELS随机选择gBest历史最佳位置的一个维度,第d个维度用Pd表示。只选择一个维度是因为局部最优可能具有全局最优的一些良好结构,因此应该保护这一点。由于每个维度具有相同的选择概率,因此ELS运算可以被认为是在统计意义上对每个维度执行的。类似于模拟退火,即进化规划或进化策略中的变异操作,精英学习是通过高斯扰动来执行的
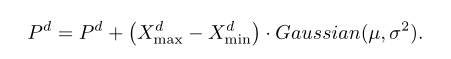
搜索范围[Xdmin,Xdmax]与问题的上下界相同。高斯(μ,σ2)是具有零均值μ和标准差(SDσ)的高斯分布的随机数,被称为“精英学习率”。与一些时变神经网络训练方案类似,建议σ随代数线性减少,代数由σ=σmax−(σmax−σmin)g / G给出,其中σmax和σmin是σ的上下界,代表到达一个新区域的学习规模。
实证研究表明,σmax=1.0和σmin=0.1在大多数测试函数上都具有良好的性能。
Flowchart of ELS forgBestupon convergence state emerging.
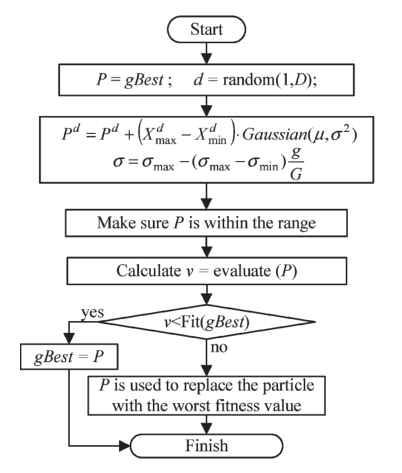
在统计意义上,减小的SD在早期阶段提供了较高的学习率,使其跳出可能的局部最优解,而在后期,较小的学习率引导了Beste改进解。在ELS中,如果且仅当新职位的适合性比当前的最佳职位更好时,才会接受新职位。否则,新位置用于替换群中适应度最差的粒子。
D. Search Behaviors of APSO(APSO的搜索行为)
1) APSO in Unimodal Search Space(单峰搜索空间中的APSO)
在球面函数上研究了APSO在单峰空间中的搜索行为(表I中的f1)。在单峰空间中,对于优化或搜索算法来说,快速收敛和精化解以获得高精度是非常重要的。图9(A)中显示的惯性权重证实,APSO在探索阶段(大约50代人)保持了一个很大的ω,然后在开发之后ω迅速下降,导致收敛,因为领先粒子找到了唯一的全局最优区域,群体跟随它。
2) APSO in Multimodal Search Space(多模态搜索空间中的APSO)
种群标准差
(N、D和X分别是所有粒子的总体大小、维数和平均位置)
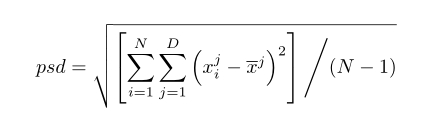
PSD中的变化可以指示种群的多样性水平。如果PSD值较小,则表明种群已紧密收敛到某一区域,种群多样性较低。PSD值越大,表明种群的多样性越高。然而,这并不一定意味着较大的psd总是比较小的psd更好,因为不能收敛的算法也可能出现较大的psd。因此,PSD需要与算法得到的解一起考虑。
实验结果表明,在多峰空间中,APSO算法也能在早期快速找到潜在的最优区域(可能是局部最优),并通过自适应参数策略快速收敛,多样性迅速减小。然而,如果当前最优区域是局部的,则群可以分离并跳出。
因此,由于ELS处于收敛状态,APSO可以适当增加种群的多样性,以寻求更好的区域。这种具有自适应种群多样性的行为对于全局搜索算法避免陷入局部最优值和在多峰空间中寻找全局最优值具有重要意义。
V. BENCHMARK TESTS AND COMPARISONS(基准测试和比较)
A. Benchmark Functions and Algorithm Configuration
(基准函数和算法配置)
B. Comparisons on the Solution Accuracy
(求解的精度比较)
C. Comparisons on the Convergence Speed
(收敛速度的比较)
D. Comparisons on the Algorithm Reliability
(算法可靠性比较)
E. Comparisons Using t-Tests
(使用t检验进行比较)
VI. ANALYSIS OF PARAMETER ADAPTATION AND ELITIST LEARNING(参数适应与精英学习分析)
A. Merits of Parameter Adaptation and Elitist Learning(参数自适应和精英学习的优点)
结果表明,在不进行参数自适应控制的情况下,APSO在只进行精英学习的情况下,仍然可以很好地求解多峰函数。然而,APSO在求解单峰函数时存在精度较低的问题。由于算法很容易找到单峰函数的全局最优区域,然后对解进行精化,因此收敛速度较慢可能导致精度较低。另一方面,仅有参数自适应而没有ELS的APSO很难跳出局部最优解,从而导致多峰函数的性能较差。但是,它仍然可以很好地解决单峰问题。
注意,这两种简化的APSO算法通常都优于既不涉及自适应参数也不涉及精英学习的标准PSO。然而,完整的Apso对于任何测试过的问题都是最强大、最健壮的。这一点在f4的测试结果中最为明显。这些结果与第四-B节的结果一起证实了这样的假设,即参数自适应加快了算法的收敛速度,精英学习有助于群体跳出局部最优解并找到更好的解。
B. Sensitivity of the Acceleration Rate(加速度灵敏度)
本文研究了由边界δ反映的加速度对APSO性能的影响。为此,学习率σ是固定的(例如,APSO最大=σ最小=0.5),并且APSO的其他参数保持与第V-A节中的相同。该调查包括6个δ测试策略,前3个策略分别将其值固定为0.01、0.05和0.1,其余3个策略分别在[0.01,0.05]、[0.05,0.1]和[0.01,0.1]内使用均匀分布随机生成其值。根据在30个独立试验中找到的解决方案的平均值,结果显示在表X中。
由此可见,APSO对加速率δ不是很敏感,六种加速率都提供了不错的性能。这可能是因为使用了加速度系数和饱和度的界限来限制它们的和(12)。因此,给定c1和c2的有界值以及它们的和受(12)的限制,δ的范围[0.05,0.1]内的任意值应该是APSO算法可以接受的。
C. Sensitivity of the Elitist Learning Rate(精英学习率的敏感性)
结果表明,如果σ很小(例如,0.1%),那么学习率不足以跳出局部最优值,这在7的性能中是显而易见的。然而,所有其他允许更大σ的设置都提供了几乎同样出色的性能,尤其是σ从1.0时变到0.1时变的策略。可以看出,较小的σ更有助于引导粒子的细化,而较大的σ更有助于引导粒子脱离现有位置,从而跳出局部最优。这证实了这样一种直觉,即应该在早期阶段适应跳跃,以避免局部最优和早熟收敛,而在后期阶段的小扰动应该有助于改进全局解,正如本文所建议的那样。
VII. CONCLUSION
本文将粒子群算法推广到APSO。粒子群算法的这一进展是由进化进化算法(ESE)实现的,它利用了种群分布和相对粒子适应度的信息,与进化策略中的内部模型有着相似的精神。基于这些信息,定义了进化因子,并用模糊分类方法计算进化因子,这有利于有效和高效的ESE方法,因此也是一种自适应算法。
如基准测试所示,惯性权重和加速系数的自适应控制使得该算法非常有效,在获得单峰和多峰函数的可接受解所需的FE数目和CPU时间方面都提供了显著提高的收敛速度。与人工神经网络中类似于竞争学习的加速界控制相结合,还设计了一种加速率控制来辅助APSO中的参数渐变。
在此基础上,提出了一种基于高斯扰动的ELS算法,该算法能引导群体跳出任何可能的局部最优解,并精化收敛解。开发了一种时变学习率,它与模拟退火中的神经网络训练或模拟退火玻尔兹曼学习(Boltzmann)具有相似的精神,以进一步帮助实现双重学习目标。ELS大大提高了全局解的准确性,这在基准测试中是显而易见的。
基于ESE的参数自适应技术不同于现有的仅基于世代数的被动参数变化方案。这一技术和精英学习技术也使改进的PSO算法在解决单峰和多峰问题时非常可靠,如表VIII中详细说明的t检验结果和表IX中详细说明的比较所示。虽然APSO作为一个整体为PSO范式引入了两个新的参数,即加速速率和学习率,但它们很容易设置,并且不会增加程序设计或实现的负担。因此,在收敛速度、全局最优性、解的准确性和算法的可靠性方面,APSO仍然与标准PSO一样简单和易于使用,但性能却有很大提高。
预计APSO将对粒子群算法在现实世界优化和搜索问题中的应用产生影响。进一步的工作包括研究基于ESE的拓扑结构自适应控制,以及将ESE技术应用于其他进化计算算法。结果将在适当时候公布。
Others:
模糊分类:


规则库
模拟退火
进化计算
精英学习策略(ELS)
进化状态估计(ESE)
“没有免费午餐”定理
以上是关于Adaptive Particle Swarm Optimization的主要内容,如果未能解决你的问题,请参考以下文章