故障公告突然猛增的巨量请求冲垮一共92核CPU的k8s集群
Posted 博客园官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了故障公告突然猛增的巨量请求冲垮一共92核CPU的k8s集群相关的知识,希望对你有一定的参考价值。
非常抱歉,今天下午2点左右开始,博客站点突然猛增的巨量请求让k8s集群的节点服务器不堪重负,造成网站无法正常访问,由此给您带来麻烦,请您谅解。
当时k8s集群一共6台node服务器,2台32核64G,2台8核64G,1台8核16G,1台4核6G,博客站点一共跑了19个pod,如果不是突然猛增的巨量请求,可以稳稳撑住。
但是今天下午的请求排山倒海,比昨天还要高(昨天GA统计的UV超过1000万,其中有很多异常请求),服务器CPU们拼尽全力也无法扛住,最终兵败如山倒。
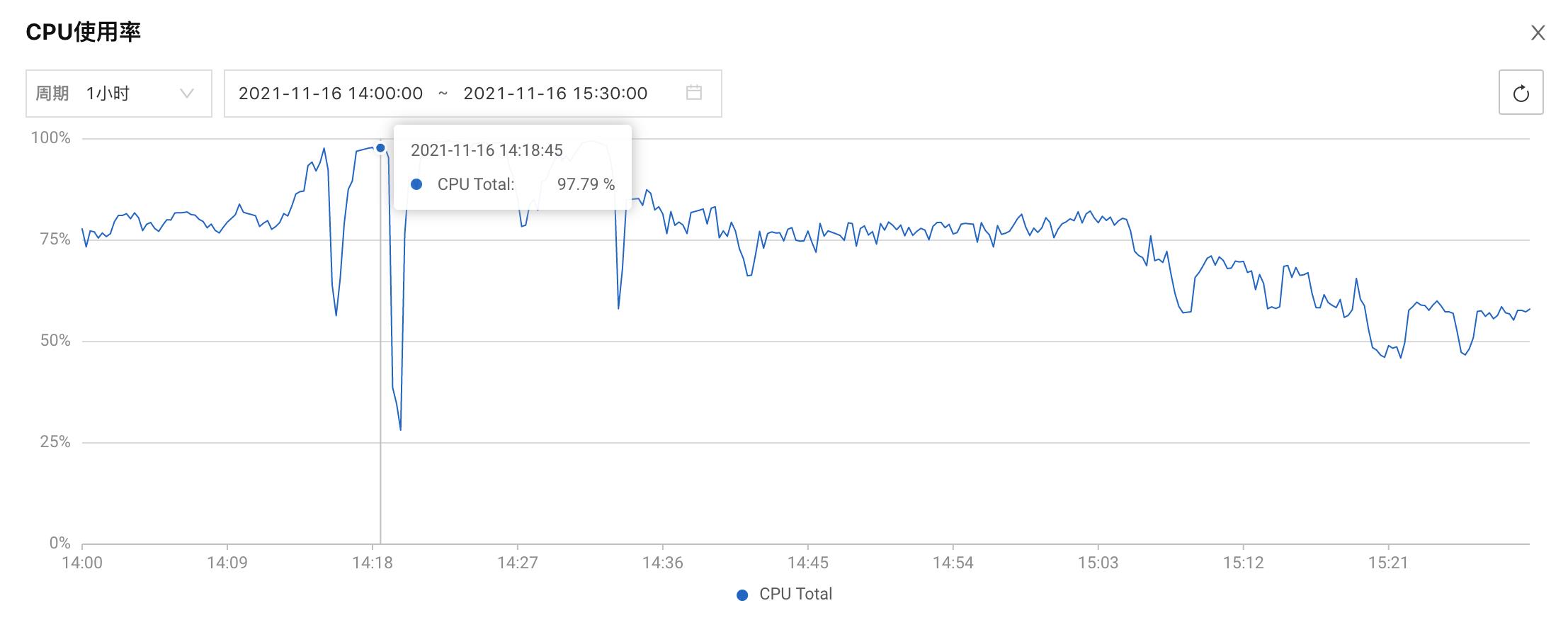
发现故障后,我们开始加服务器,一共加了5台服务器(2台8核64G,1台16核64G,2台4核8G),并逐步将 pod 切换到新加的服务器。
刚刚热身并完成健康检查的 pod 们从未经受如此的高并发考验,切换后刚上战场就倒下的情况频频出现,所以,虽然加了足够的服务器,但恢复正常需要一个过程,一边要等新 pod 撑住,一边发现体力不支的旧 pod 并强制结束,直到 15:30 之后才逐渐恢复正常。
经过初步分析,这些突增的请求多数是非正常用户的请求,这样的请求没有访问热点,每次请求的 url 不一样,让缓存有力使不上。
这次故障就向大家简单汇报到这。
这次的请求量增幅是我们之前从未遇到过的,我们毫无准备,而且目前k8s集群还没实现自动伸缩,我们还需要时间去准备。
以上是关于故障公告突然猛增的巨量请求冲垮一共92核CPU的k8s集群的主要内容,如果未能解决你的问题,请参考以下文章
故障公告取代 memcached 的 redis 出现问题造成网站故障
故障公告数据库服务器 CPU 近 100% 造成全站故障,雪上加霜难上加难的三月