打造最全皮肤,Python采集英雄联盟(LOL)官网数据!
Posted qdsn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打造最全皮肤,Python采集英雄联盟(LOL)官网数据!相关的知识,希望对你有一定的参考价值。
环境:
- Python3.6.5
- Windows
- pycharm
模块:
- import requests
- import jsonpath from urllib.request
- import urlretrieve import os
思路:
进入LOL官网的游戏资料-资料库后,可以看到所有的英雄都在里面。
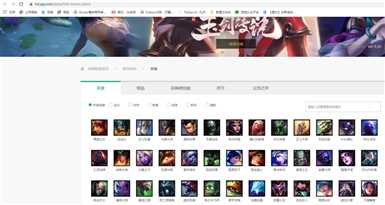
当我们点击英雄头像时,会跳转到皮肤界面。
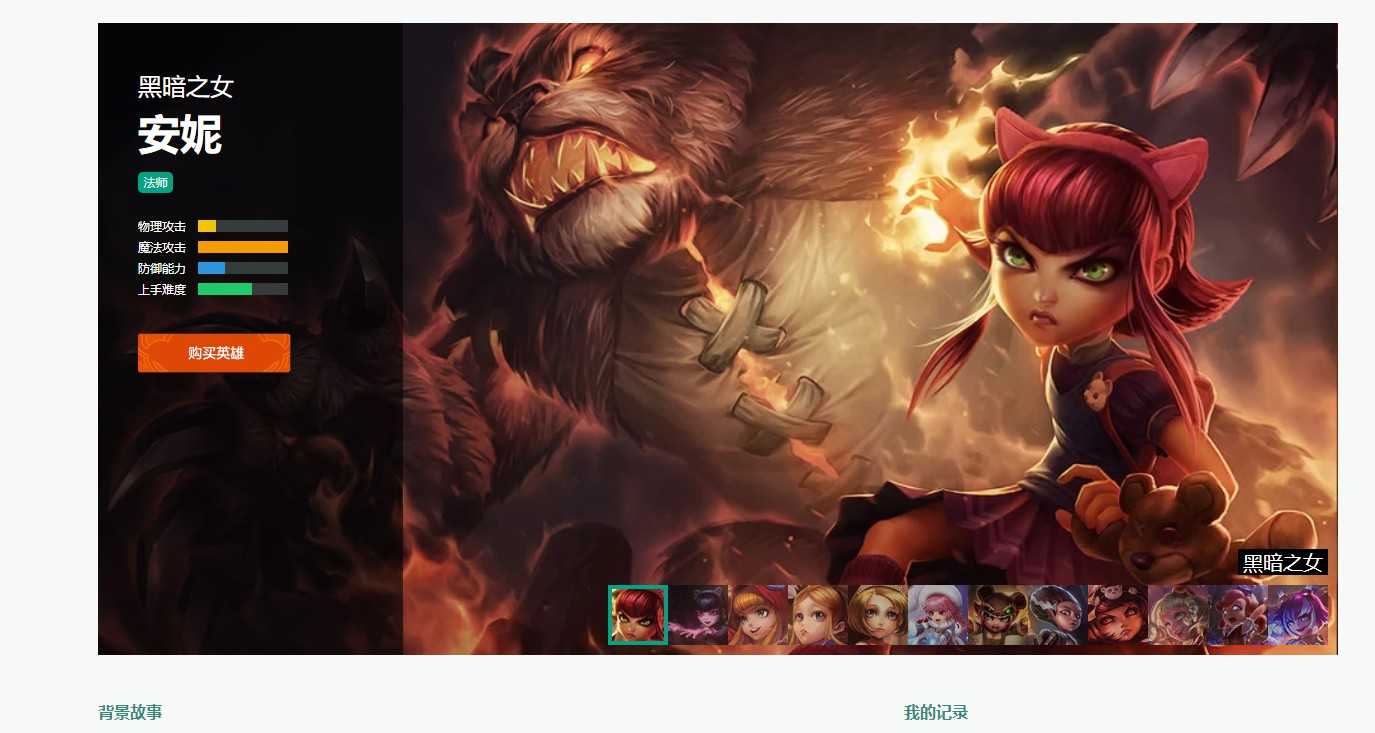
一般人的做法就是,采集到跳转的url,然后再请求该url获取皮肤数据。
思路没错,但是要想一下,如果源代码中没有跳转的url呢?
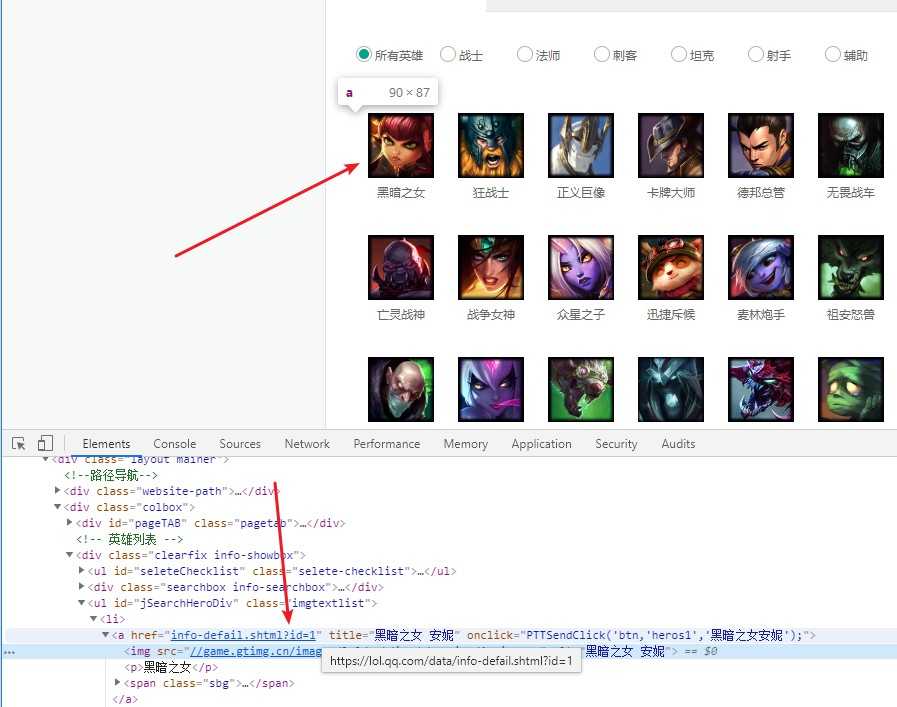
elements中确实有该链接,但是源代码中没有:
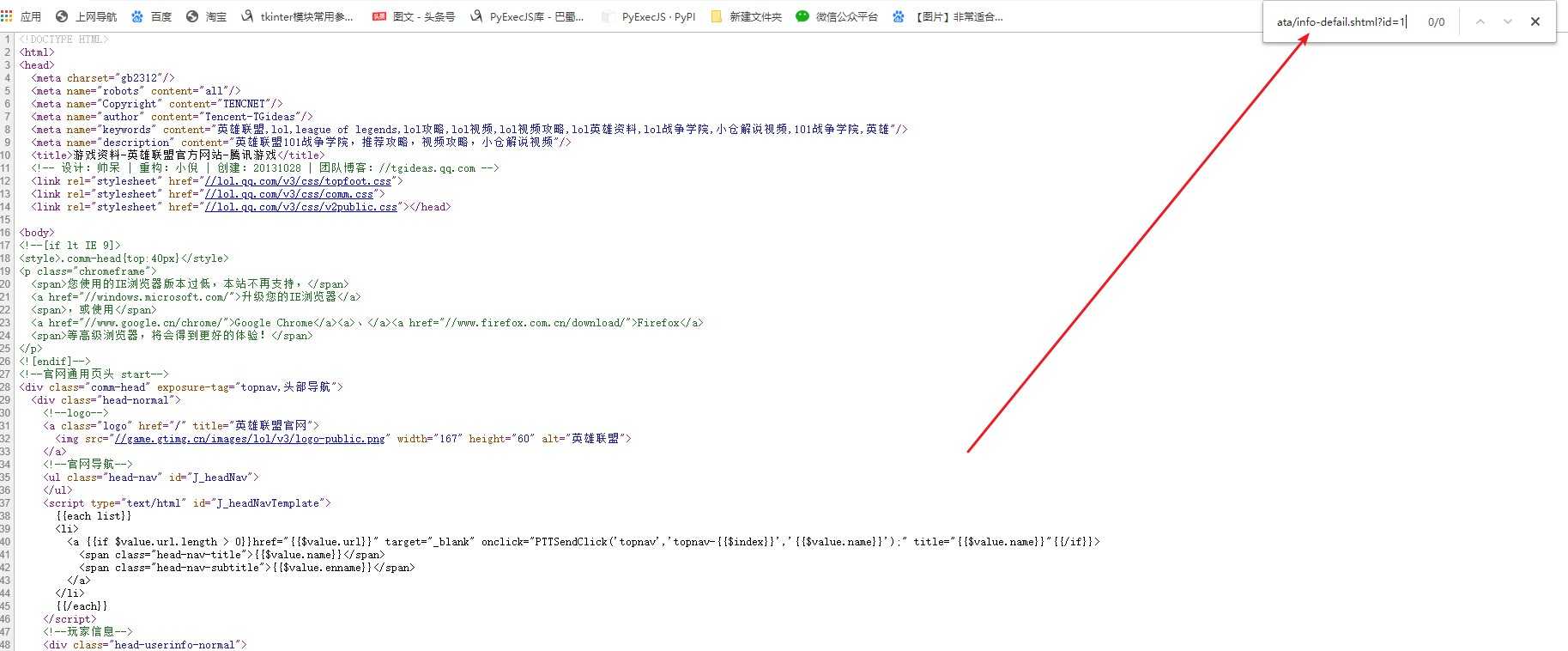
这个时候,毫无疑问 --抓包吧:
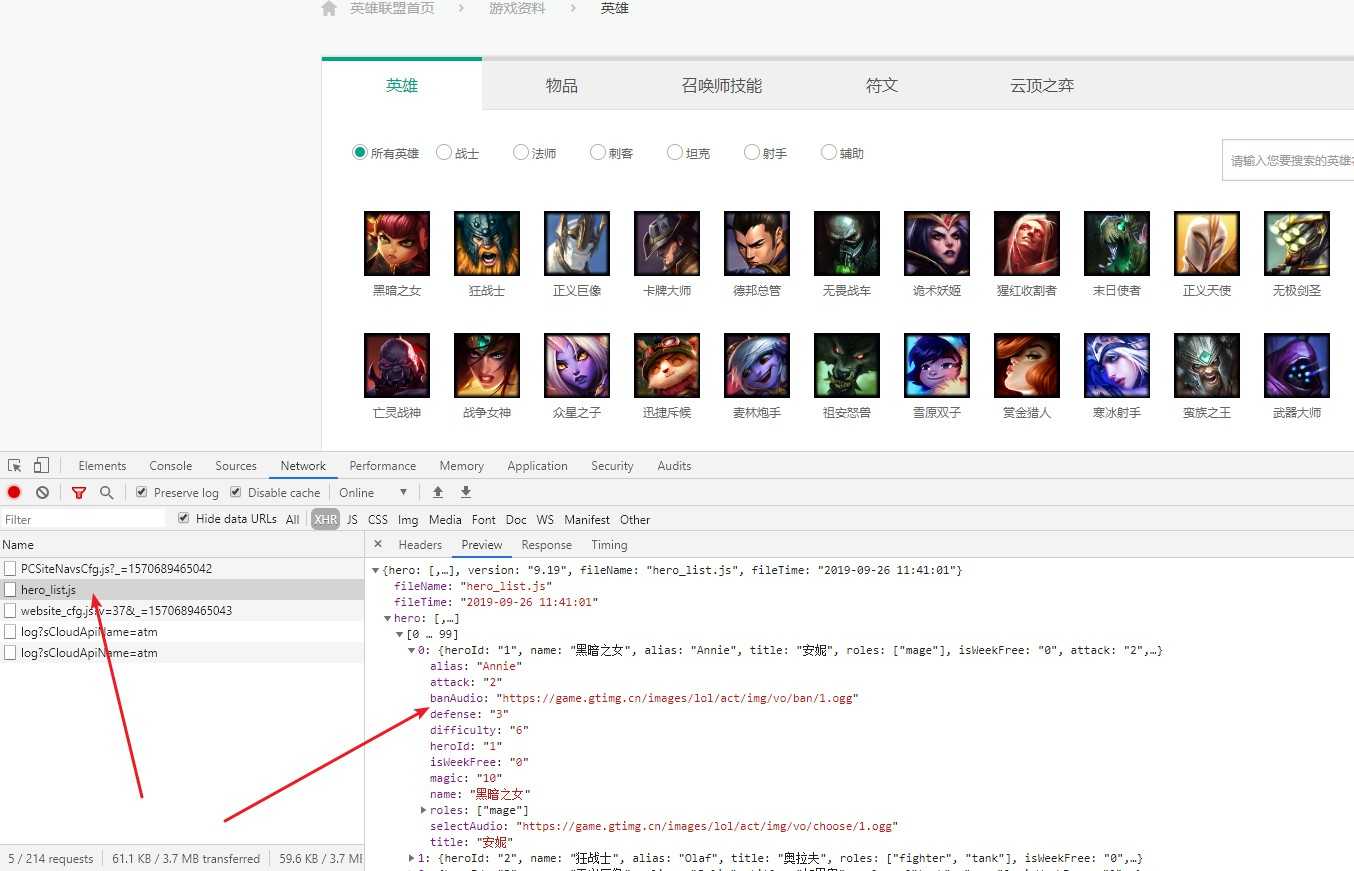
很多人做到这里无从下手了,并没有跳转的url,但是你没发现跳转的url只有一个地方放生了变化吗?(自行观察)
就只有后面的数字发生了变化,而我们的banaudio这个标签当中的url末尾是不是也有个1.ogg???
获取到数字1即可自行构造跳转的url。
到了跳转页面后,会发现网页源代码中同样不存在我们想要的图片数据(继续抓包):
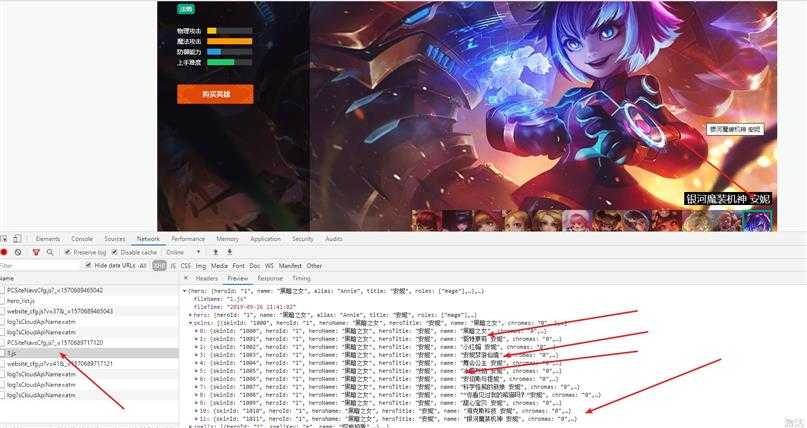
OK,问题已经得到解决,很简单的一个案例。
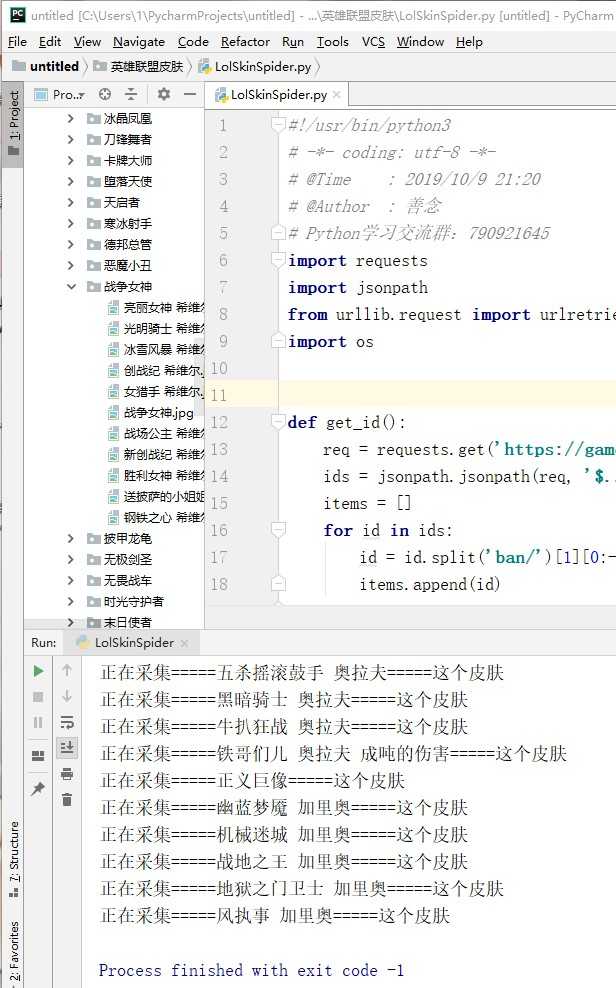
效果:
想得到更多的技术文章推送可以关注我的个人公众号:

以上是关于打造最全皮肤,Python采集英雄联盟(LOL)官网数据!的主要内容,如果未能解决你的问题,请参考以下文章