[Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)相关的知识,希望对你有一定的参考价值。
思路是这样的,给一系列关键字:互联网电视;智能电视;数字;影音;家庭娱乐;节目;视听;版权;数据等。在活动行网站搜索页(http://www.huodongxing.com/search?city=%E5%85%A8%E5%9B%BD&pi=1)的文本输入框中分别输入每个关键字,在搜索结果中抓取需要的数据。
首先通过Selenium+IE驱动得到每个关键字搜索结果的url(首页,因为以后各个页的url就是索引不一样)和总页数,保存的列表里面。然后再循环列表,用Selenium +phantomjs抓取每个关键字对应的url抓取对应的数据。

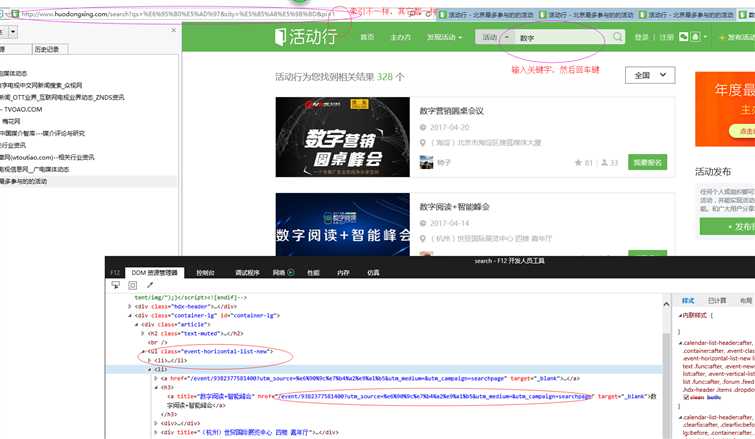
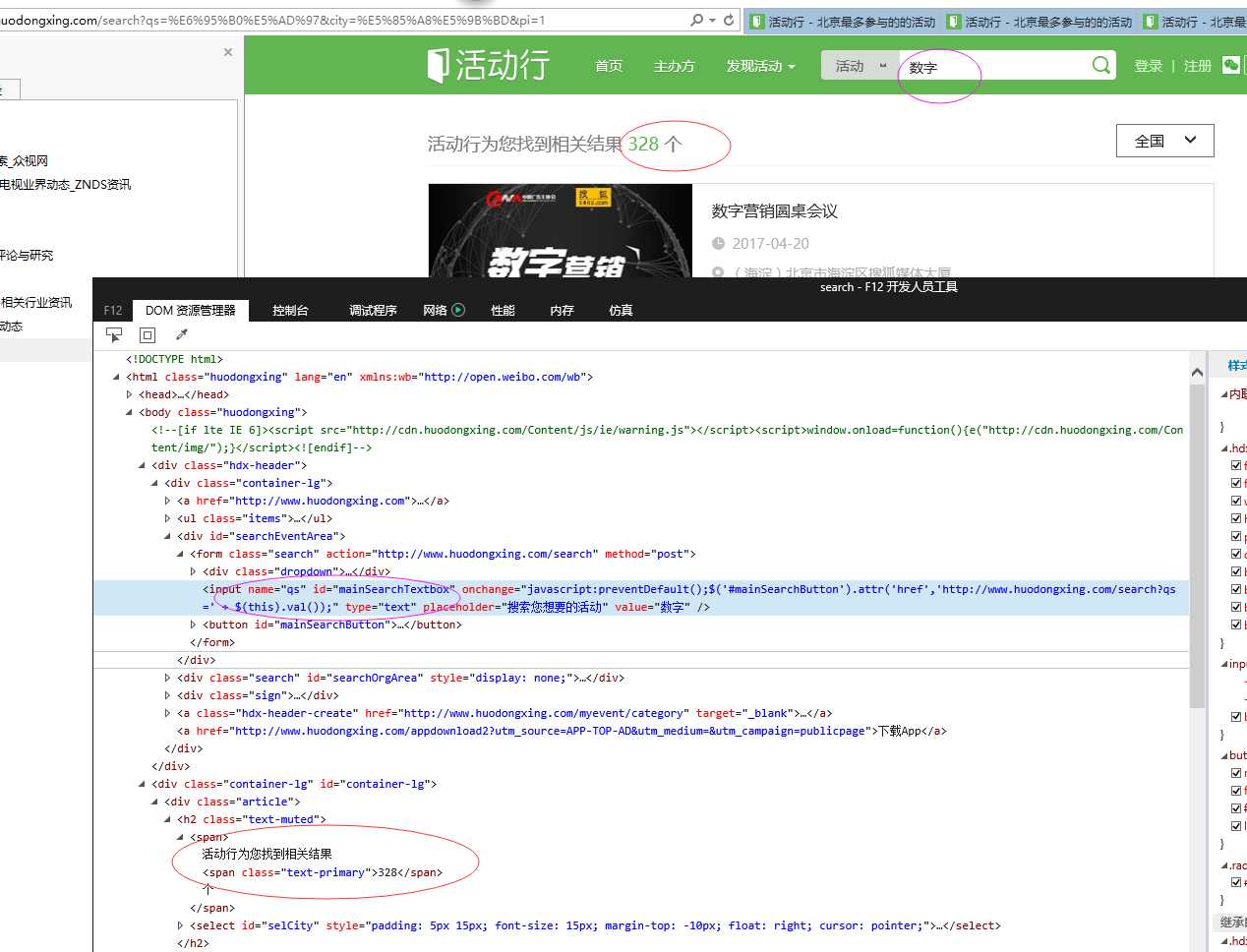
具体代码如下:
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import IniFile
from selenium.webdriver.common.keys import Keys
import LogFile
class huodongxing:
def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
configfile = os.path.join(os.getcwd(),‘MeetingConfig.conf‘)
self.cf = IniFile.ConfigFile(configfile)
IEDriverServer = self.cf.GetValue("section", "IEDriverServer")
#每抓取一页数据延迟的时间,单位为秒,默认为5秒
self.pageDelay = 5
pageInteralDelay = self.cf.GetValue("section", "pageInteralDelay")
if pageInteralDelay:
self.pageDelay = int(pageInteralDelay)
os.environ["webdriver.ie.driver"] = IEDriverServer
self.urldriver = webdriver.Ie(IEDriverServer)
# self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.urldriver, 20)
self.urldriver.maximize_window()
def compareDate(self,dateLeft, dateRight):
‘‘‘
比较俩个日期的大小
:param dateLeft: 日期 格式2017-03-04
:param dateRight:日期 格式2017-03-04
:return: 1:左大于右,0:相等,-1:左小于右
‘‘‘
dls = dateLeft.split(‘-‘)
drs = dateRight.split(‘-‘)
if len(dls) > len(drs):
return 1
if int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) == int(drs[2]):
return 0
if int(dls[0]) > int(drs[0]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) > int(drs[1]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) > int(drs[2]):
return 1
return -1
def scroll_top(self):
‘‘‘
滚动条拉到顶部
:return:
‘‘‘
if self.urldriver.name == "chrome":
js = "var q=document.body.scrollTop=0"
else:
js = "var q=document.documentElement.scrollTop=0"
return self.urldriver.execute_script(js)
def scroll_foot(self):
‘‘‘
滚动条拉到底部
:return:
‘‘‘
if self.urldriver.name == "chrome":
js = "var q=document.body.scrollTop=10000"
else:
js = "var q=document.documentElement.scrollTop=10000"
return self.urldriver.execute_script(js)
def get_UrlPageCountList(self,webSearchUrl,keywordList):
‘‘‘
根据关键字列表获取每个关键字搜索出内容url及对应的页数
:param webSearchUrl: 给定网址的搜索首页
:param keywordList: 关键字列表
:return: url及对应的页数的列表
‘‘‘
search_url_pageCount_list = []
# firstUrl = self.cf.GetValue("section", "webSearchUrl")
self.urldriver.get(webSearchUrl)
# self.urldriver.implicitly_wait(3)
time.sleep(3)
pageCountLable = self.cf.GetValue("section", "pageCountLable")
for keyword in keywordList:
if len(keyword) > 0:
js = "var obj = document.getElementById(‘mainSearchTextbox‘);obj.value=‘" + keyword + "‘;"
print ‘关键字:%s‘ % keyword
self.urldriver.execute_script(js)
# 点击搜索链接
ss_elements = self.urldriver.find_element_by_id("mainSearchTextbox")
ss_elements.send_keys(Keys.RETURN)
time.sleep(5)
current_url = self.urldriver.current_url.replace(‘pi=1‘, ‘pi=‘)
try:
elements = self.urldriver.find_elements_by_xpath(pageCountLable)
# 要爬虫的页数
strCount = elements[0].text.encode(‘utf8‘)
pageCount = int(strCount) / 10
if int(strCount) % 10 > 0:
pageCount = pageCount + 1
search_url_pageCount_list.append(current_url + ‘_‘ + str(pageCount))
except Exception, e:
print e.message
self.urldriver.close()
self.urldriver.quit()
self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 20)
self.driver.maximize_window()
return search_url_pageCount_list
def scrapy_Data(self):
‘‘‘抓取数据‘‘‘
start = time.clock()
webSearchUrl = self.cf.GetValue("section", "webSearchUrl")
keyword = self.cf.GetValue("section", "keywords")
keywordList = keyword.split(‘;‘)
#搜索页及对应的页数
search_url_pageCount_list = self.get_UrlPageCountList(webSearchUrl,keywordList)
if len(search_url_pageCount_list) > 0:
htmlLable = self.cf.GetValue("section", "htmlLable")
# logfile = os.path.join(os.getcwd(), r‘log.txt‘)
# log = LogFile.LogFile(logfile)
OriginalUrlLabel = self.cf.GetValue("section", "OriginalUrlLabel")
currentDate = time.strftime(‘%Y-%m-%d‘)
datePattern = re.compile(r‘\\d{4}-\\d{2}-\\d{2}‘)
keyword_index = 0
for url_pageCount in search_url_pageCount_list:
try:
kword = keywordList[keyword_index]
print ‘‘
print ‘关键字:%s ‘ % kword
pageCount = int(url_pageCount.split(‘_‘)[1])
page_Count = pageCount
recordCount = 0
if pageCount > 0:
current_url = url_pageCount.split(‘_‘)[0]
pageIndex = 0
while pageCount > 0:
url = current_url + str(pageIndex)
self.driver.get(url)
# 延迟3秒
time.sleep(3)
# self.driver.implicitly_wait(3)
pageCount = pageCount - 1
self.wait.until(lambda driver: self.driver.find_elements_by_xpath(htmlLable))
Elements = self.driver.find_elements_by_xpath(htmlLable)
# 查找微博对应的原始url
urlList = []
self.wait.until(lambda driver: self.driver.find_elements_by_xpath(OriginalUrlLabel))
hrefElements = self.driver.find_elements_by_xpath(OriginalUrlLabel)
for hrefe in hrefElements:
urlList.append(hrefe.get_attribute(‘href‘).encode(‘utf8‘))
# self.driver.implicitly_wait(2)
index = 0
strMessage = ‘ ‘
strsplit = ‘\\n------------------------------------------------------------------------------------\\n‘
index = 0
# 每页中有用记录
usefulCount = 0
for element in Elements:
txt = element.text.encode(‘utf8‘)
txts = txt.split(‘\\n‘)
strDate = re.findall(datePattern, txt)
# 日期大于今天并且搜索的关键字在标题中才认为是复合要求的数据
if len(strDate) > 0 and self.compareDate(strDate[0], currentDate) == 1 and \\
txts[0].find(kword) > -1:
print ‘ ‘
print txt
print ‘活动链接:‘ + urlList[index]
print strsplit
strMessage = txt + "\\n"
strMessage += ‘活动链接:‘ + urlList[index] + "\\n"
strMessage += strsplit
strMessage = unicode(strMessage, ‘utf8‘)
log.WriteLog(strMessage)
usefulCount = usefulCount + 1
recordCount = recordCount + 1
index = index + 1
pageIndex = pageIndex + 1
if usefulCount == 0:
break
print "共浏览了: %d 页数据" % page_Count
print "共抓取了: %d 个符合条件的活动记录" % recordCount
except Exception, e:
print e.message
keyword_index = keyword_index + 1
self.driver.close()
self.driver.quit()
end = time.clock()
print "整个过程用时间: %f 秒" % (end - start)
# #测试抓取数据
obj = huodongxing()
obj.scrapy_Data()
配置文件内容:
[section]
#IE驱动的路径
iedriverserver = C:\\Program Files\\Internet Explorer\\IEDriverServer.exe
pageinteraldelay = 5
#要搜索的标签,如果有多个,中间用分号隔开
htmlLable = //ul[@class=‘event-horizontal-list-new‘]/li
#要获取爬虫也是的标签
pageCountLable = //span[@class=‘text-primary‘]
#给定网址的搜索首页Url
webSearchUrl = http://www.huodongxing.com/search?city=%E5%85%A8%E5%9B%BD&pi=1
#查找对应的原始url
OriginalUrlLabel = //ul[@class=‘event-horizontal-list-new‘]/li/h3/a
#文本输入框要搜索的关键字
keywords = 互联网电视;智能电视;数字;影音;家庭娱乐;节目;视听;版权;数据
抓取的数据结构为:

以上是关于[Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)的主要内容,如果未能解决你的问题,请参考以下文章