正则表达式(Python)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式(Python)相关的知识,希望对你有一定的参考价值。
-
了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。 正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
-
正则表达式的大致匹配过程
- 依次拿出表达式和文本中的字符比较,
- 如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
- 如果表达式中有量词或边界,这个过程会稍微有一些不同。
-
正则表达式的语法规则(Python)
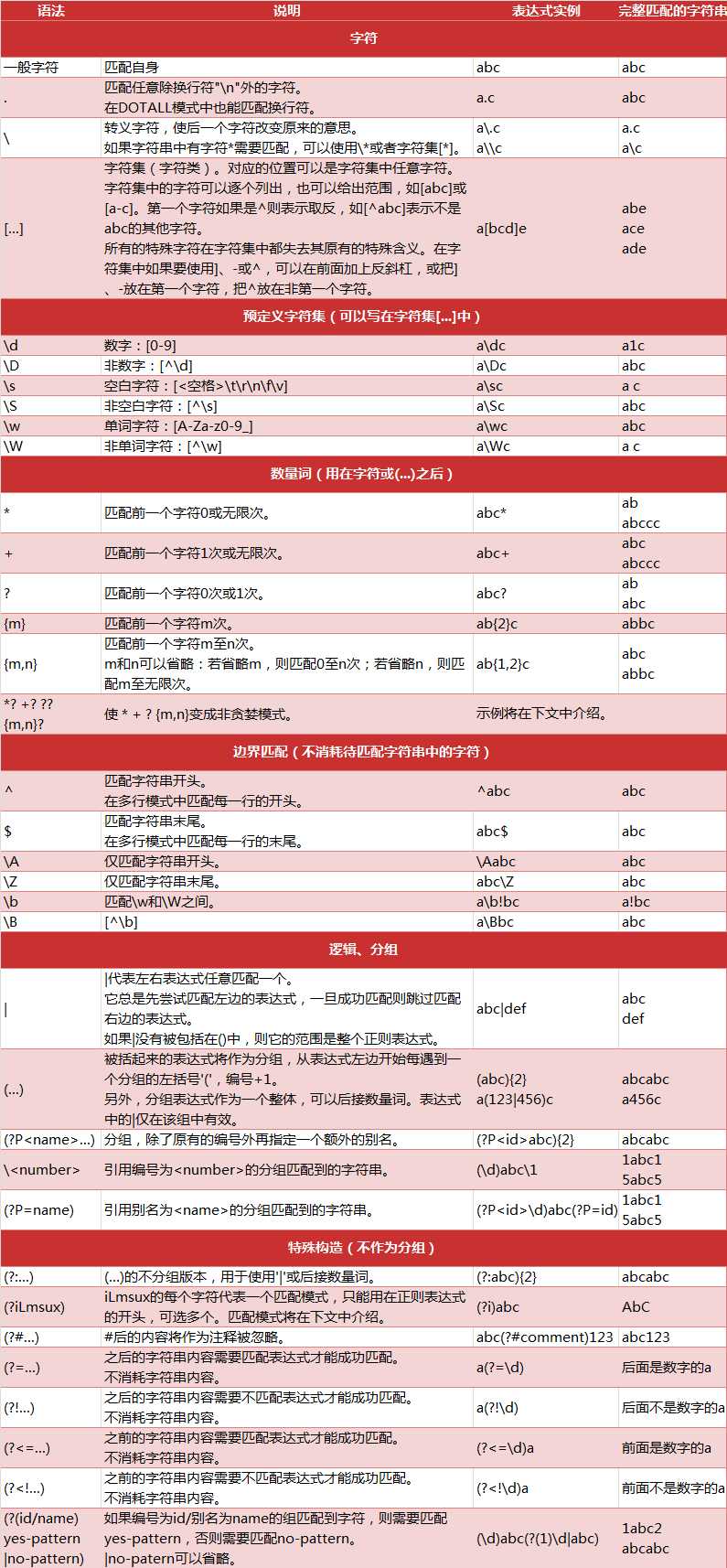
-
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式 ”ab” 如果用于查找 ”abbbc”,将找到 ”abbb”。而如果使用非贪婪的数量词 ”ab?”,将找到 ”a”。
注:我们一般使用非贪婪模式来提取。
-
反斜杠问题
与大多数编程语言相同,正则表达式里使用”\\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python 里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用 r”\\” 表示。同样,匹配一个数字的 ”\\d” 可以写成 r”\\d”。
-
Python Re模块
Python自带了re模块,它提供了对正则表达式的支持。主要用法如下举例:
#返回pattern对象 re.compile(string[,flag]) #以下为匹配所用函数 re.match(pattern, string[, flags]) re.search(pattern, string[, flags]) re.split(pattern, string[, maxsplit]) re.findall(pattern, string[, flags]) re.finditer(pattern, string[, flags]) re.sub(pattern, repl, string[, count]) re.subn(pattern, repl, string[, count])
patterng概念:
pattern 可以理解为一个匹配模式,那么我们怎么获得这个匹配模式呢?很简单,我们需要利用 re.compile 方法就可以。例如
pattern = re.compile(r‘hello‘)
在参数中我们传入了原生字符串对象,通过 compile 方法编译生成一个 pattern 对象,然后我们利用这个对象来进行进一步的匹配。
另外大家可能注意到了另一个参数 flags,在这里解释一下这个参数的含义:
参数 flag 是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如 re.I | re.M。
可选值有:
? re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
? re.M(全拼:MULTILINE): 多行模式,改变‘^‘和‘$‘的行为(参见上图)
? re.S(全拼:DOTALL): 点任意匹配模式,改变‘.‘的行为
? re.L(全拼:LOCALE): 使预定字符类 \\w \\W \\b \\B \\s \\S 取决于当前区域设定
? re.U(全拼:UNICODE): 使预定字符类 \\w \\W \\b \\B \\s \\S \\d \\D 取决于unicode定义的字符属性
? re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
在刚才所说的另外几个方法例如 re.match 里我们就需要用到这个 pattern 了,下面我们一一介绍。
注: 以下七个方法中flags同样是代表匹配模式的意思,如果在pattern生成时已经指明了flags,那么在下面的方法中就不需要传入这个参数了。
-
re.match函数
re.match 尝试从字符串的开始匹配一个模式。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
| pattern | 匹配的正则表达式。 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
| 匹配对象方法 | 描述 |
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例:
1 #!/usr/bin/python
2 import re
3
4 line = "Cats are smarter than dogs"
5
6 matchObj = re.match( r‘(.*) are (.*?) .*‘, line, re.M|re.I)
7
8 if matchObj:
9 print ("matchObj.group() : ", matchObj.group())
10 print ("matchObj.group(1) : ", matchObj.group(1))
11 print ("matchObj.group(2) : ", matchObj.group(2))
12 else:
13 print ("No match!!")
以上实例执行结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
-
re.search方法
re.search 尝试从字符串的开始匹配一个模式。
函数语法:
re.search(pattern, string, flags=0)
实例:
1 #!/usr/bin/python
2 import re
3
4 line = "Cats are smarter than dogs";
5
6 matchObj = re.search( r‘(.*) are (.*?) .*‘, line, re.M|re.I)
7
8 if matchObj:
9 print ("matchObj.group() : ", matchObj.group())
10 print ("matchObj.group(1) : ", matchObj.group(1))
11 print ("matchObj.group(2) : ", matchObj.group(2))
12 else:
13 print ("No match!!")
执行结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
-
re.match 与 re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
实例:
1 import re
2
3 line = "Cats are smarter than dogs"
4
5 matchObj = re.match( r‘dogs‘, line, re.M|re.I)
6 if matchObj:
7 print ("match --> matchObj.group(): ", matchObj.group())
8 else:
9 print ("No match!!")
10
11 searchObj = re.search( r‘dogs‘, line, re.M|re.I)
12 if searchObj:
13 print ("search --> matchObj.group(): ", searchObj.group())
14 else:
15 print ("No match!!")
运行结果:
No match!!
search --> matchObj.group() : dogs
-
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
实例:
1 #!/usr/bin/python
2 import re
3
4 phone = "2004-959-559 # This is Phone Number"
5
6 # Delete Python-style comments
7 num = re.sub(r‘#.*$‘, "", phone)
8 print ("Phone Num : ", num)
9
10 # Remove anything other than digits
11 num = re.sub(r‘\\D‘, "", phone)
12 print ("Phone Num : ", num)
运行结果:
Phone Num : 2004-959-559
Phone Num : 2004959559
以上是关于正则表达式(Python)的主要内容,如果未能解决你的问题,请参考以下文章