Python网络爬虫---使用已登录的cookie访问需要登录的网页
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python网络爬虫---使用已登录的cookie访问需要登录的网页相关的知识,希望对你有一定的参考价值。
使用已登录的Cookie访问登录的网站在网络爬虫中经常使用
1.使用浏览器手动登录网站,点击你需要访问的页面,比如我想访问的资源地址是
http://27.24.159.151:8005/student/GradeQueryPersonal.aspx
访问之后,使用F12启动调试
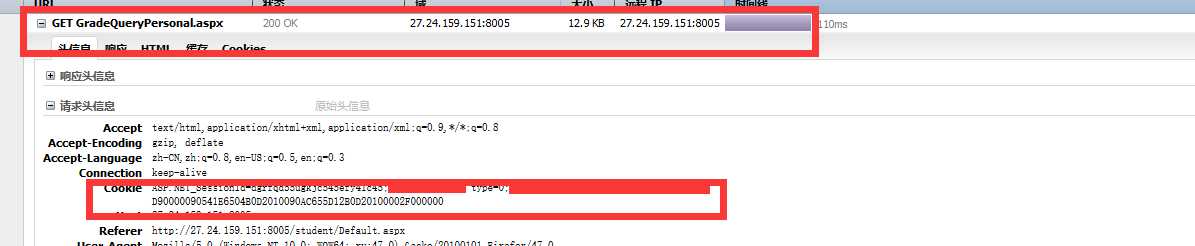
可以看到访问该资源地址的所需要的Cookie信息
2.开始编码,使用Python2.7的自带的urllib2模块发送带cookie信息的请求头去访问对应的资源地址
#-*-coding:utf-8-*- ‘‘‘ 登录教务系统 ‘‘‘ import urllib2 from bs4 import BeautifulSoup cook = ‘ASP.NET_SessionId=dgrfqd55ugkjc545efy41c45;0090541E6504B0D2010090AC655D12B0D20100002F000000‘ HEADERS = {"cookie": cook} #填写你访问对应的资源地址时对应的Cookie url = ‘http://27.24.159.151:8005/student/GradeQueryPersonal.aspx‘ request = urllib2.Request(url, headers=HEADERS) html = urllib2.urlopen(request).read() soup = BeautifulSoup(html, ‘lxml‘) title = soup.find(‘title‘).get_text() print title
运行结果,打印输出了该页面的标题
python stucookie.py
学生个人成绩查询
以上是关于Python网络爬虫---使用已登录的cookie访问需要登录的网页的主要内容,如果未能解决你的问题,请参考以下文章