python 运维自动化之路 Day2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 运维自动化之路 Day2相关的知识,希望对你有一定的参考价值。
学习内容:
1、模块初识
2、Pyc是什么
3、Python数据类型
4、数据运算
5、bytes数据类型
6、列表和元组的使用
7、字符串常用操作
8、字典的使用
1、模块初识
如果用 python 解释器来编程,从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
下面是一个使用 python 标准库中模块的例子。
import sys print(sys.path) print(sys.argv) # print(sys.argv[1]) import os os.system("dir") #调用系统命令dir,不保存结果。 print(os.popen(‘dir‘).read()) #打开总读取当前目录从内存地址中。 os.mkdir(‘new_quote3‘) #创建新目录 print(os.popen(‘dir‘).read())
执行结果如下:


C:\\Users\\hca006\\AppData\\Local\\Programs\\Python\\Python36\\python.exe "D:/python app/var/day2/sysmodel.py" [‘D:\\\\python app\\\\var\\\\day2‘, ‘D:\\\\python app\\\\var‘, ‘C:\\\\Users\\\\hca006\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\python36.zip‘, ‘C:\\\\Users\\\\hca006\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\DLLs‘, ‘C:\\\\Users\\\\hca006\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\lib‘, ‘C:\\\\Users\\\\hca006\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36‘, ‘C:\\\\Users\\\\hca006\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\lib\\\\site-packages‘] [‘D:/python app/var/day2/sysmodel.py‘] ?????? D ?е???? ???? ??????к??? 08BD-E367 D:\\python app\\var\\day2 ???? 2017/04/07 20:38 <DIR> . 2017/04/07 20:38 <DIR> .. 2017/04/07 20:18 2,015 dictionary.py 2017/04/07 18:46 1,048 dictionary22.py 2017/03/28 08:19 1,819 list.py 2017/03/29 16:45 1,657 mycopy.py 2017/03/29 15:21 145 mydeepcopy.py 2017/04/07 20:35 <DIR> new_quote2 2017/03/29 20:14 1,483 shop.py 2017/04/07 20:38 312 sysmodel.py 2017/03/29 19:55 535 tmall.py 2017/04/07 15:27 741 zifucuang.py 2017/03/23 19:20 19 __init__.py 2017/03/29 15:24 <DIR> __pycache__ 10 ????? 9,774 ??? 4 ???? 396,468,563,968 ??????? 驱动器 D 中的卷是 工作 卷的序列号是 08BD-E367 D:\\python app\\var\\day2 的目录 2017/04/07 20:38 <DIR> . 2017/04/07 20:38 <DIR> .. 2017/04/07 20:18 2,015 dictionary.py 2017/04/07 18:46 1,048 dictionary22.py 2017/03/28 08:19 1,819 list.py 2017/03/29 16:45 1,657 mycopy.py 2017/03/29 15:21 145 mydeepcopy.py 2017/04/07 20:35 <DIR> new_quote2 2017/03/29 20:14 1,483 shop.py 2017/04/07 20:38 312 sysmodel.py 2017/03/29 19:55 535 tmall.py 2017/04/07 15:27 741 zifucuang.py 2017/03/23 19:20 19 __init__.py 2017/03/29 15:24 <DIR> __pycache__ 10 个文件 9,774 字节 4 个目录 396,468,563,968 可用字节 驱动器 D 中的卷是 工作 卷的序列号是 08BD-E367 D:\\python app\\var\\day2 的目录 2017/04/07 20:38 <DIR> . 2017/04/07 20:38 <DIR> .. 2017/04/07 20:18 2,015 dictionary.py 2017/04/07 18:46 1,048 dictionary22.py 2017/03/28 08:19 1,819 list.py 2017/03/29 16:45 1,657 mycopy.py 2017/03/29 15:21 145 mydeepcopy.py 2017/04/07 20:35 <DIR> new_quote2 2017/04/07 20:38 <DIR> new_quote3 2017/03/29 20:14 1,483 shop.py 2017/04/07 20:38 312 sysmodel.py 2017/03/29 19:55 535 tmall.py 2017/04/07 15:27 741 zifucuang.py 2017/03/23 19:20 19 __init__.py 2017/03/29 15:24 <DIR> __pycache__ 10 个文件 9,774 字节 5 个目录 396,468,563,968 可用字节 Process finished with exit code 0
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 ,需要把命令放在脚本的顶端。
2、Pyc是什么
简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
.Pyc文件是存储预编译后的一个字节码文件。
3、Python数据类型
1.数字
Python 数字数据类型用于存储数值。
数据类型是不允许改变的,这就意味着如果改变数字数据类型得值,将重新分配内存空间。
Python 支持三种不同的数值类型:
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
- 浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- 复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
Python 数字类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
-
int(x) 将x转换为一个整数。
-
float(x) 将x转换到一个浮点数。
-
complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
-
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
以下实例将浮点数变量 a 转换为整数:
>>> a = 1.0 >>> int(a) 1
var1 = ‘Hello World!‘ var2 = "dnvwjy"
4、数据运算
算数运算:
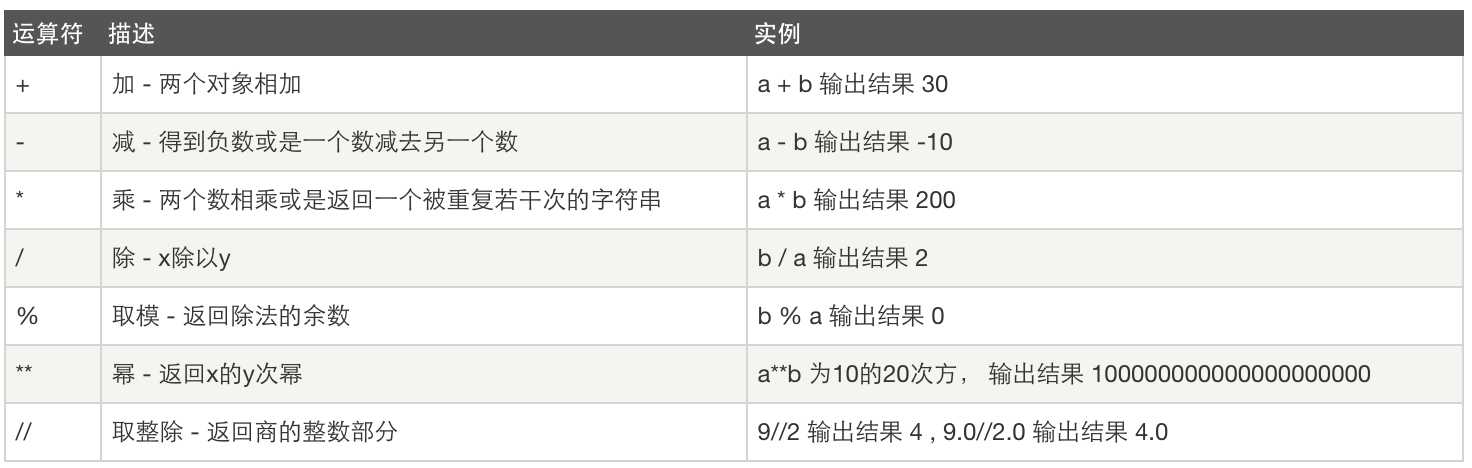
比较运算:

赋值运算:
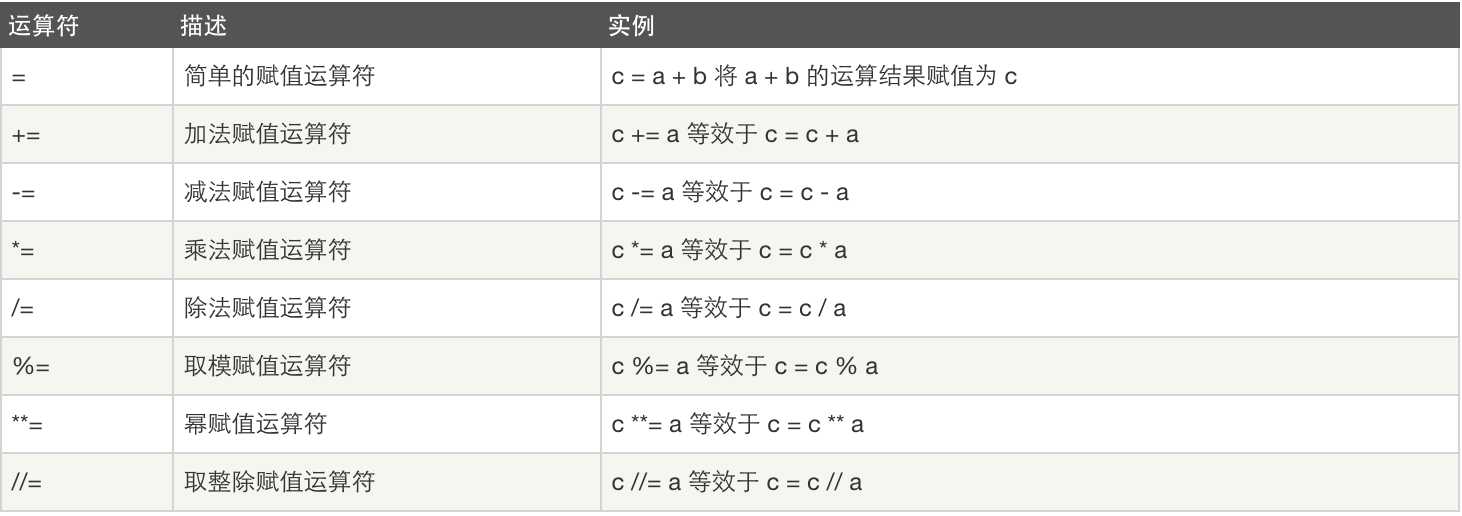
逻辑运算:

成员运算:

身份运算:

位运算:
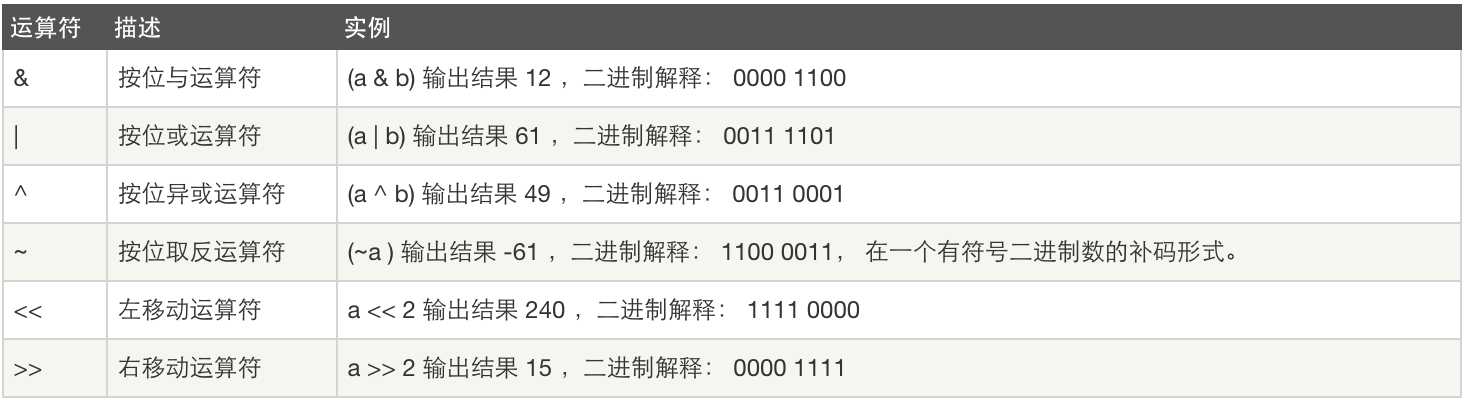
运算符优先级:
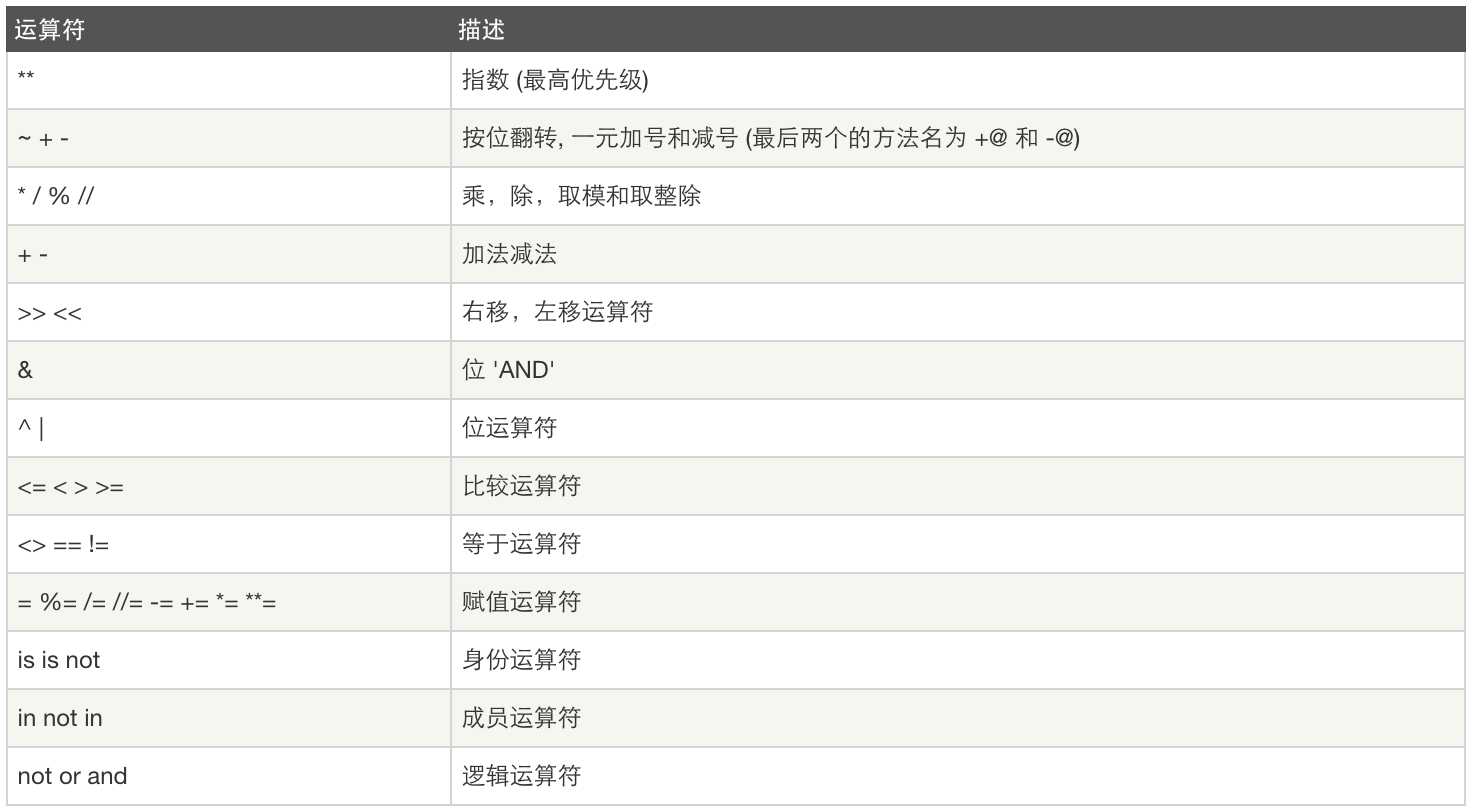
计算机中能表示的最小单位,是一个二进制位
计算机中能存储的最小单位,是一个二进制位(bit)
8bit = byte(字节)
1024byte = 1Kbyte
1024Kbyte = 1Mbyte
1024Mb = 1Gb
1024Gb= 1T
5、bytes数据类型
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
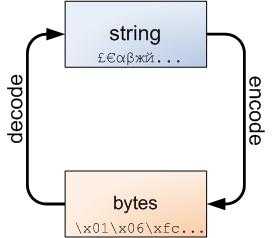
字符串可以编码成字节包,而字节包可以解码成字符串。
>>>‘€20‘.encode(‘utf-8‘) b‘\\xe2\\x82\\xac20‘ >>> b‘\\xe2\\x82\\xac20‘.decode(‘utf-8‘) ‘€20‘
这个问题要这么来看:字符串是文本的抽象表示。字符串由字符组成,字符则是与任何特定二进制表示无关的抽象实体。在操作字符串时,我们生活在幸福的无知之中。我们可以对字符串进行分割和分片,可以拼接和搜索字符串。我们并不关心它们内部是怎么表示的,字符串里的每个字符要用几个字节保存。只有在将字符串编码成字节包(例如,为了在信道上发送它们)或从字节包解码字符串(反向操作)时,我们才会开始关注这点。
传入encode和decode的参数是编码(或codec)。编码是一种用二进制数据表示抽象字符的方式。目前有很多种编码。上面给出的UTF-8是其中一种,下面是另一种:
>>‘€20‘.encode(‘iso-8859-15‘) b‘\\xa420‘ >>> b‘\\xa420‘.decode(‘iso-8859-15‘) ‘€20‘
编码是这个转换过程中至关重要的一部分。离了编码,bytes对象b‘\\xa420‘只是一堆比特位而已。编码赋予其含义。采用不同的编码,这堆比特位的含义就会大不同:
>>> b‘\\xa420‘.decode(‘windows-1255‘) ‘?20‘
三元运算:result = 值1 if 条件 else 值2
>>> a,b,c = 1,3,5 >>> a 1 >>> b 3 >>> c 5 >>> d = b if c>a else 7 >>> d 3 >>> d = b if c<a else 7 >>> d 7
6、元组和列表的使用
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
# 列表、元组操作 names = [‘胡汉‘,‘友兰‘,‘姬发‘,‘明程‘,‘国梁‘] print (names[1:3]) #打印names列表的值从第2个开始至第四个结束 print(names) print(names[-2:]) #打印最后两个,-1表示最后一个。如果写成-2:0打印为空,因为切片是从左往右切。 print (names.index(‘姬发‘)) #打印索引下标 print (names[names.index(‘姬发‘)]) #打印索引下标的值 print (names[:1]) #前面的0可以忽略
执行结果如下:(Python 列表的下标从0开始)
[‘友兰‘, ‘姬发‘] [‘胡汉‘, ‘友兰‘, ‘姬发‘, ‘明程‘, ‘国梁‘] [‘明程‘, ‘国梁‘] 2 姬发 [‘胡汉‘] Process finished with exit code 0
追加、修改、插入和删除(在修改列表的时候,只能通过下标索引,不能直接写值)
names = [‘胡汉‘,‘友兰‘,‘姬发‘,‘明程‘,‘国梁‘] names.append(2001) #追加,默认追加到列表最后。 print (names) names.insert(1,2002) #在列表内1的下标位置插入值。 print (names) names[3]=‘宇亮‘ print (names) names[names.index(‘明程‘)]=‘江夏‘ #在不知道下标的情况下修改列表内的值,在修改的时候只能用下标, #如果写成names[‘明程‘]=‘江夏‘是错误的! print (names) names.remove(2002) #移除列表内的值 print (names) del names[5] #删除列表内下标为5的值,凡是列表后面用[]括起,方法用()括起。 print (names) names.pop(1) #删除列表内下标为1的值,等同于del names[] print (names) names.pop() #空值表示删除最后一个值。 print (names) names2 = [1,2,3,5] del names2 #删除变量 print (names.count(‘江夏‘)) #统计数量 names.reverse() #列表反转 print(names)
执行结果如下:
[‘胡汉‘, ‘友兰‘, ‘姬发‘, ‘明程‘, ‘国梁‘, 2001] [‘胡汉‘, 2002, ‘友兰‘, ‘姬发‘, ‘明程‘, ‘国梁‘, 2001] [‘胡汉‘, 2002, ‘友兰‘, ‘宇亮‘, ‘明程‘, ‘国梁‘, 2001] [‘胡汉‘, 2002, ‘友兰‘, ‘宇亮‘, ‘江夏‘, ‘国梁‘, 2001] [‘胡汉‘, ‘友兰‘, ‘宇亮‘, ‘江夏‘, ‘国梁‘, 2001] [‘胡汉‘, ‘友兰‘, ‘宇亮‘, ‘江夏‘, ‘国梁‘] [‘胡汉‘, ‘宇亮‘, ‘江夏‘, ‘国梁‘] [‘胡汉‘, ‘宇亮‘, ‘江夏‘] 1 [‘江夏‘, ‘宇亮‘, ‘胡汉‘] Process finished with exit code 0
列表的排序和合并
a = [‘abc‘,‘acb‘,‘aac‘,‘abc‘] print(a) a.sort() #列表排序,默认升序。 print(a) b = [4,2,5,6,1,7] print(b) b.sort() print(b) c = [‘a‘,‘B‘,‘Pang‘,‘pang‘] print (c) c.sort() print (c) c.extend(b) #列表合并 print (c)
执行结果如下:不同类型的数据类型不能排序。
[‘abc‘, ‘acb‘, ‘aac‘, ‘abc‘] [‘aac‘, ‘abc‘, ‘abc‘, ‘acb‘] [4, 2, 5, 6, 1, 7] [1, 2, 4, 5, 6, 7] [‘a‘, ‘B‘, ‘Pang‘, ‘pang‘] [‘B‘, ‘Pang‘, ‘a‘, ‘pang‘] [‘B‘, ‘Pang‘, ‘a‘, ‘pang‘, 1, 2, 4, 5, 6, 7] Process finished with exit code 0
列表的copy
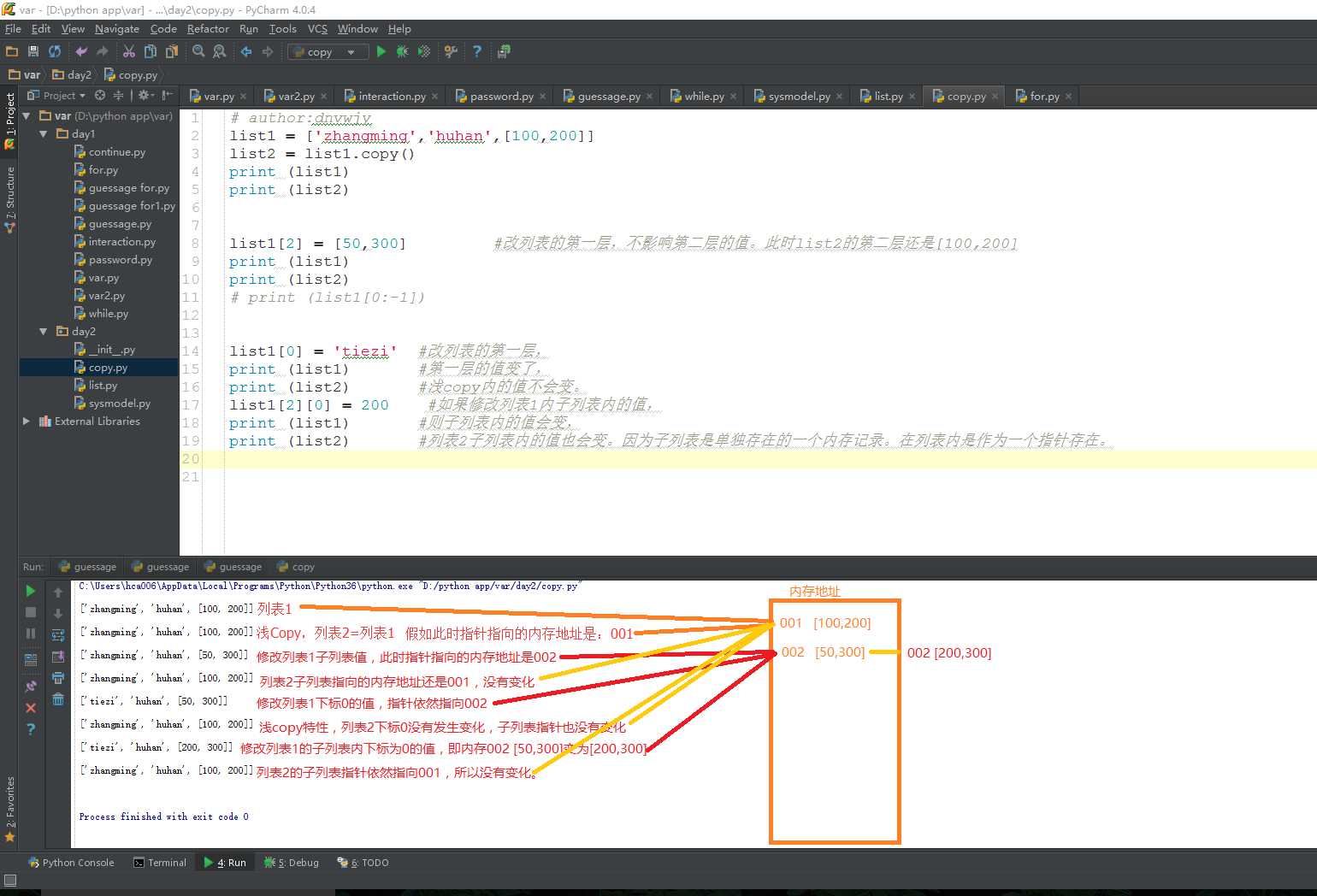
列表中可以包含列表,但是子列表的存在只是一个内存指针,在copy的时候只是浅copy,子列表是单独指向的一个内存地址,修改列表1列表2也会变。
浅copy:
import copy list1 = [‘zhangming‘,‘huhan‘,[100,200]] list2 = list1.copy() print (list1) print (list2) list1[2] = [50,300] #改列表的第一层,不影响第二层的值。此时list2的第二层还是[100,200] print (list1) print (list2) print (list1[:-1]) #列表切片,从第一个下标开始至最后一个下标,但不包含最后一个下标。
结果如下:
[‘zhangming‘, ‘huhan‘, [100, 200]] [‘zhangming‘, ‘huhan‘, [100, 200]] [‘zhangming‘, ‘huhan‘, [50, 300]] [‘zhangming‘, ‘huhan‘, [100, 200]] [‘zhangming‘, ‘huhan‘]
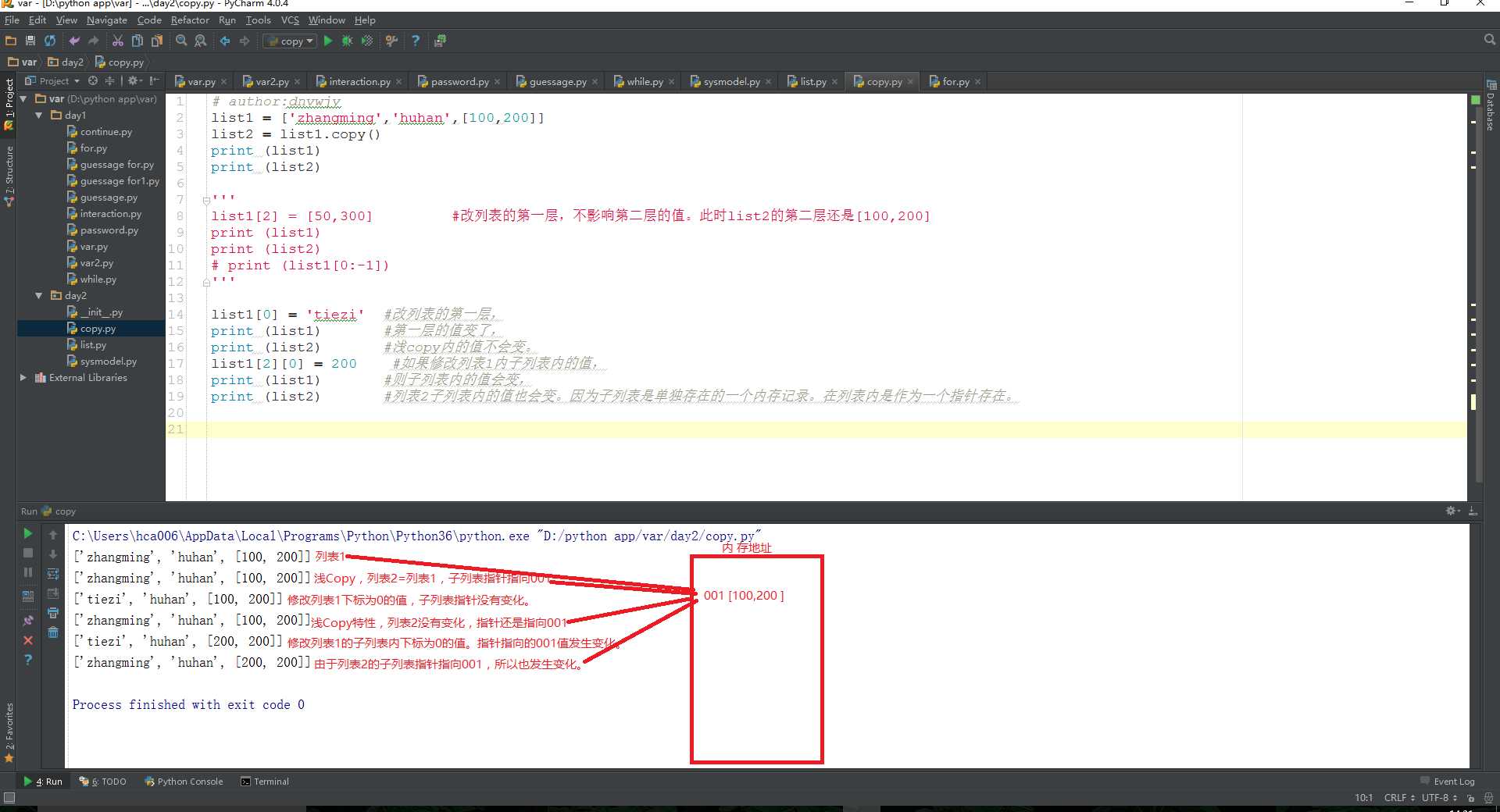
修改子列表浅copy的列表值也会跟着改变:
import copy list1 = [‘zhangming‘,‘huhan‘,[100,200]] list2 = list1.copy() list1[0] = ‘tiezi‘ #改列表的第一层, print (list1) #第一层的值变了, print (list2) #浅copy内的值不会变。 list1[2][0] = 200 #如果修改列表1内子列表内的值, print (list1) #则子列表内的值会变, print (list2) #列表2子列表内的值也会变。因为子列表是单独存在的一个内存记录。在列表内是作为一个指针存在。 list2[2][1] = 500 print (list1) print (list2)
如果如下:
[‘tiezi‘, ‘huhan‘, [100, 200]] [‘zhangming‘, ‘huhan‘, [100, 200]] [‘tiezi‘, ‘huhan‘, [200, 200]] [‘zhangming‘, ‘huhan‘, [200, 200]] [‘tiezi‘, ‘huhan‘, [200, 500]] [‘zhangming‘, ‘huhan‘, [200, 500]] Process finished with exit code 0
深copy:
# author:dnvwjy import copy list3 = [‘wangyi‘,‘chexiao‘,‘huilong‘,[‘yutong‘,‘CRT‘]] list4 = copy.deepcopy(list3) #深copy,就是完全克隆一份一模一样的,而且是独立的占一份内存地址。 print (list3) print (list4) list3[3][0] = ‘HM‘ print (list3) print (list4)
执行结果如下:
[‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘HM‘, ‘CRT‘]] [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] Process finished with exit code 0
列表的循环打印、切片以及步长切片:
list3 = [‘wangyi‘,‘chexiao‘,‘huilong‘,[‘yutong‘,‘CRT‘]] for i in list3: print (i) #列表的循环打印 #列表的切片 和 步长切片 print (list3[0:-1:2]) print (list3[::2]) #0和-1都可以省略。 print (list3[:]) #浅copy的三种实现形式 list5 = copy.copy(list3) list6 = list3[:] list7 = list(list3) print (‘list5:‘,list5) print (‘list6:‘,list6) print (‘list7:‘,list7) list3[3][0] = 1 print (‘list5:‘,list5) print (‘list6:‘,list6) print (‘list7:‘,list7)
结果如下:
wangyi chexiao huilong [‘yutong‘, ‘CRT‘] [‘wangyi‘, ‘huilong‘] [‘wangyi‘, ‘huilong‘] [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] list5: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] list6: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] list7: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [‘yutong‘, ‘CRT‘]] list5: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [1, ‘CRT‘]] list6: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [1, ‘CRT‘]] list7: [‘wangyi‘, ‘chexiao‘, ‘huilong‘, [1, ‘CRT‘]] Process finished with exit code 0
元组:
元组就是列表,但是不能删和改。元组又叫只读列表,元组用小括号()括号,只有两个参数(count/index),列表用中括号[]括起。
#元组--英文tuple,用小括号表示() tuple=(‘apple‘,‘eggs‘) print(tuple.count(‘apple‘)) #统计 print(tuple.index(‘apple‘)) #索引 del tuple #删除元组
7、字符串常用操作
特性:不可修改,可以切片

name.capitalize() 首字母大写
name.casefold() 大写全部变小写
name.center(50,"-") 输出 ‘---------------------Alex Li----------------------‘
name.count(‘lex‘) 统计 lex出现次数
name.encode() 将字符串编码成bytes格式
name.endswith("Li") 判断字符串是否以 Li结尾
"Alex\\tLi".expandtabs(10) 输出‘Alex Li‘, 将\\t转换成多长的空格
name.find(‘A‘) 查找A,找到返回其索引, 找不到返回-1
format :
>>> msg = "my name is {}, and age is {}"
>>> msg.format("alex",22)
‘my name is alex, and age is 22‘
>>> msg = "my name is {1}, and age is {0}"
>>> msg.format("alex",22)
‘my name is 22, and age is alex‘
>>> msg = "my name is {name}, and age is {age}"
>>> msg.format(age=22,name="ale")
‘my name is ale, and age is 22‘
format_map
>>> msg.format_map({‘name‘:‘alex‘,‘age‘:22})
‘my name is alex, and age is 22‘
msg.index(‘a‘) 返回a所在字符串的索引
‘9aA‘.isalnum() True
‘9‘.isdigit() 是否整数
name.isnumeric
name.isprintable
name.isspace
name.istitle
name.isupper
"|".join([‘alex‘,‘jack‘,‘rain‘])
‘alex|jack|rain‘
maketrans
>>> intab = "aeiou" #This is the string having actual characters.
>>> outtab = "12345" #This is the string having corresponding mapping character
>>> trantab = str.maketrans(intab, outtab)
>>>
>>> str = "this is string example....wow!!!"
>>> str.translate(trantab)
‘th3s 3s str3ng 2x1mpl2....w4w!!!‘
msg.partition(‘is‘) 输出 (‘my name ‘, ‘is‘, ‘ {name}, and age is {age}‘)
>>> "alex li, chinese name is lijie".replace("li","LI",1)
‘alex LI, chinese name is lijie‘
msg.swapcase 大小写互换
>>> msg.zfill(40)
‘00000my name is {name}, and age is {age}‘
>>> n4.ljust(40,"-")
‘Hello 2orld-----------------------------‘
>>> n4.rjust(40,"-")
‘-----------------------------Hello 2orld‘
>>> b="ddefdsdff_哈哈"
>>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
True
补充字符串操作:
name = ‘tangcao‘ print(name.capitalize()) print(name.capitalize()) print(‘abc‘.isalnum()) print(‘16AC‘.isdecimal()) print(‘a16AC-‘.isidentifier()) print(‘-‘.join([‘alum‘,‘fifle‘,‘firebord‘])) print (name.ljust(30,‘+‘)) print (name.rjust(30,‘+‘)) print (‘AAAA‘.lower()) print (‘aaaa‘.upper()) print (‘\\t \\nccccc\\n‘.lstrip()) print (‘++++\\t11‘) s=str.maketrans(‘abcdefg‘,‘1234567‘) print(‘my name is nana‘.translate(s)) print(‘fuck off‘.replace(‘f‘,‘6‘,1)) print(‘fuck off‘.rfind(‘f‘)) print (‘fuck off‘.split(‘f‘)) print (‘fu\\nck of\\nf‘.splitlines()) print(‘fUCK oFF‘.swapcase()) print (‘dnvwjy‘.zfill(30))
执行结果如下:
Tangcao Tangcao True False False alum-fifle-firebord tangcao+++++++++++++++++++++++ +++++++++++++++++++++++tangcao aaaa AAAA ccccc ++++ 11 my n1m5 is n1n1 6uck off 7 [‘‘, ‘uck o‘, ‘‘, ‘‘] [‘fu‘, ‘ck of‘, ‘f‘] Fuck Off 000000000000000000000000dnvwjy
8、字典的使用
字典是一种key-value的数据类型
特性:无序,key必须是唯一的,所以天生去重!
info = { ‘stu1101‘: ‘TengLan wu‘, ‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, } print(info) print(info[‘stu1102‘]) info[‘stu1101‘] = ‘武藤兰‘ #修改字典对应key的值 info[‘stu1104‘] = ‘cangjinkong‘ #没有相应的KEY就添加一条记录。 print (info) #del info[‘stu1101‘] #删除字典内KEY对应的KEY和值。 #del info #删除整个字典 DEL是Python内置的删除通用方法。 info.pop(‘stu1101‘) #删除 info.popitem() #随机删除一个 #查找 # info[‘stu1105‘] #没有相应的KEY就出错啦! # print(info[‘stu1105‘]) #KeyError:‘stu1105‘ print(info.get(‘stu1105‘)) #查找字典KEY的正确打开方式! #判断key是否在字典内: print(‘stu1105‘in info) #等同于PY2.X info.has_key(‘stu1102‘) #PY3.X没有了这种方法。 #返回布尔值 c = {‘stu1101‘:‘dnvwjy‘,1:3,2:5,} info.update(c) #更新,合并字典,有重复就替换。 print(info.items()) #把字典转换成列表 # s = info.fromkeys({6,7,8},‘test‘) #这里跟info没有任何关系可以写成dict s = dict.fromkeys([6,7,8],[2,{‘name‘:‘lexe‘},444]) #fromkeys(key,values),这里的value是一个列表的数据类型 s[8][1][‘name‘]=‘dbv‘ #[key][列表][列表下的值] s[8][2]=‘dccv‘ #[key][列表][列表下的值],共享的一个内存地址所以列表内的值全改了!如果只有一层就没问题。 print (s) print (info) #列表的循环: print (i,info(i)) #TypeError: ‘dict‘ object is not callable for i in info: print (i,info[i]) #这里不能用(),要用[]在字典内取值。 for k,j in info.items(): #两个字典循环的结果都一样,但是上面一种更加高效,因为第二种循环需要转换为列表,如果数据 #量非常大,运行速度也会变得非常慢。 print(k,j)
结果:
C:\\Users\\hca006\\AppData\\Local\\Programs\\Python\\Python36\\python.exe "D:/python app/var/day2/dictionary.py" {‘stu1101‘: ‘TengLan wu‘, ‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘} LongZe Luola {‘stu1101‘: ‘武藤兰‘, ‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1104‘: ‘cangjinkong‘} None False dict_items([(‘stu1102‘, ‘LongZe Luola‘), (‘stu1103‘, ‘XiaoZe Maliya‘), (‘stu1101‘, ‘dnvwjy‘), (1, 3), (2, 5)]) {6: [2, {‘name‘: ‘dbv‘}, ‘dccv‘], 7: [2, {‘name‘: ‘dbv‘}, ‘dccv‘], 8: [2, {‘name‘: ‘dbv‘}, ‘dccv‘]} {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘dnvwjy‘, 1: 3, 2: 5} stu1102 LongZe Luola stu1103 XiaoZe Maliya stu1101 dnvwjy 1 3 2 5 stu1102 LongZe Luola stu1103 XiaoZe Maliya stu1101 dnvwjy 1 3 2 5 Process finished with exit code 0
字典的多级嵌套
# author:dnvwjy av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } } av_catalog[‘大陆‘][‘1024‘][0] += ‘,还有91pron‘ #修改 # print (av_catalog.values()) #打印values # print (av_catalog.keys()) #打印keys av_catalog.setdefault(‘taiwang‘,{‘123‘:[‘www.baidu.com‘]}) #setdefault,如果字典内没有就添加,如果有就返回,不添加。 av_catalog.setdefault(‘taiwang‘,{‘456‘:[‘www.baidu.com‘]}) print( av_catalog.items()) # print (av_catalog)
C:\\Users\\hca006\\AppData\\Local\\Programs\\Python\\Python36\\python.exe "D:/python app/var/day2/dictionary22.py" dict_items([(‘欧美‘, {‘www.youporn.com‘: [‘很多免费的,世界最大的‘, ‘质量一般‘], ‘www.pornhub.com‘: [‘很多免费的,也很大‘, ‘质量比yourporn高点‘], ‘letmedothistoyou.com‘: [‘多是自拍,高质量图片很多‘, ‘资源不多,更新慢‘], ‘x-art.com‘: [‘质量很高,真的很高‘, ‘全部收费,屌比请绕过‘]}), (‘日韩‘, {‘tokyo-hot‘: [‘质量怎样不清楚,个人已经不喜欢日韩范了‘, ‘听说是收费的‘]}), (‘大陆‘, {‘1024‘: [‘全部免费,真好,好人一生平安,还有91pron‘, ‘服务器在国外,慢‘]}), (‘taiwang‘, {‘123‘: [‘www.baidu.com‘]})]) Process finished with exit code 0
总结:
想学好Python一定要多动手写代码,要猛戮键盘!:P 不然看得再多也枉然!
鸭梨山大!