Python高级应用程序设计任务
Posted Silver_Sakura
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
B站的视频信息爬取
2.主题式网络爬虫爬取的内容与数据特征分析
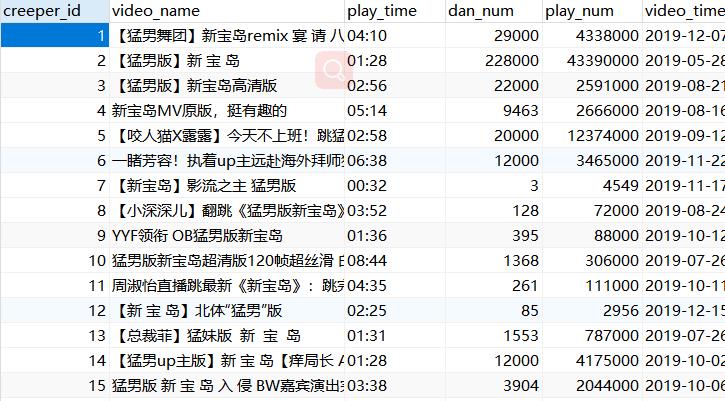
爬取B站搜索视频结果界面的主体视频信息(视频名,视频播放时间、视频播放数,视频弹幕数、视频上传时间)
数据特征,我做了简单的简化,视频时间采用字符串存储,上传时间也是,mysql存储也比较简单,处理起来也比较简单。因为B站最多的搜索页数为50,每页20,所以最多只有1000条记录,
不过因为本程序有一定的扩展性,只要关键字就可以爬取不同主题的信息记录。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1.设计,一开始其实本来想做个系统的、爬虫,并且爬取视频内容,但开发时遇到了一定的阻碍,计划临时改变
1.1 设计如下:
printShow类实现数据处理可视化输出
dataSave类实现数据的持久化
creeper类实现数据的爬取与清洗
creeperMain模块为运行的组函数
1.2实现思路:
printShow类使用matplotlib模块实现数据可视化。
dataSave类使用pymysql模块实现数据处理。
creeper类使用requests、BeautifulSoup、dataSave模块实现网页请求,处理网页,爬取网页、获取数据、清理数据、数据的持久化
creeperMain模块为主程序入口
1.3技术难点:
首先是对于数据的爬取,要找到网站有用的数据、还要使用BeautifulSoup爬取网站信息,这步需要对于网站的了解,还有要建立在网站不经常改变标识的情况下,找到较为合适的筛选规则。
其次对于数据的处理和传递,数据如何以文本的形式提取出来,数据如何转换,比如10万如何转变为整形的100000
再来数据的持久化处理,怎么存储,怎么使用。
最后是对与整个系统架构的设计,如何完善
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
主体页面为B站的搜索页面,基本的特征,基本就是网页头、网页中部、网页尾部、其中有用的数据在网页中部的
存有视频信息,结构由于工作比较忙懒得写了,直接上图
2.Htmls页面解析
主体页面为B站的搜索页面,基本的特征,基本就是网页头、网页中部、网页尾部、其中有用的数据在网页中部的有用信息,
简单描述救赎ul标签中有20个li标签,每个li标签中有视频名,视频播放时间、视频播放数,视频弹幕数、视频上传时间爬,就完事了
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
直接上图:
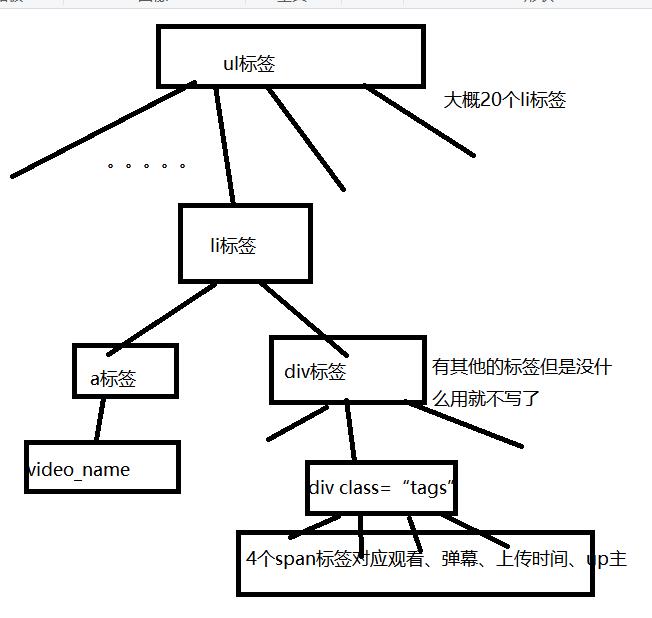
画的比较难看,但是工作真的很忙
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
使用模块化开发,模块为creeperBm,代码在如下
代码可实现功能挺多,我就不多写了,写几个典型的例子我觉得就行了。





2.对数据进行清洗和处理
使用模块化开发,模块为creeperBm,代码在如下
由于模块开发,功能合并,功能如上。
3.文本分析(可选):jieba分词、wordcloud可视化
这部分没做
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
使用模块化开发,模块为printShow,代码在如下
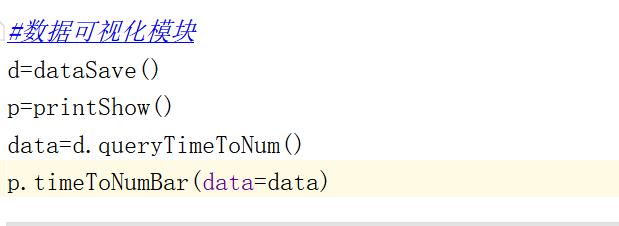
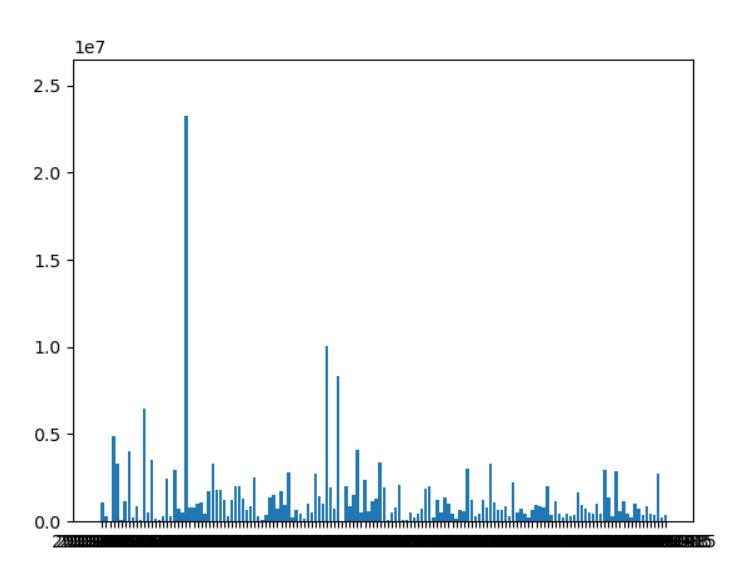
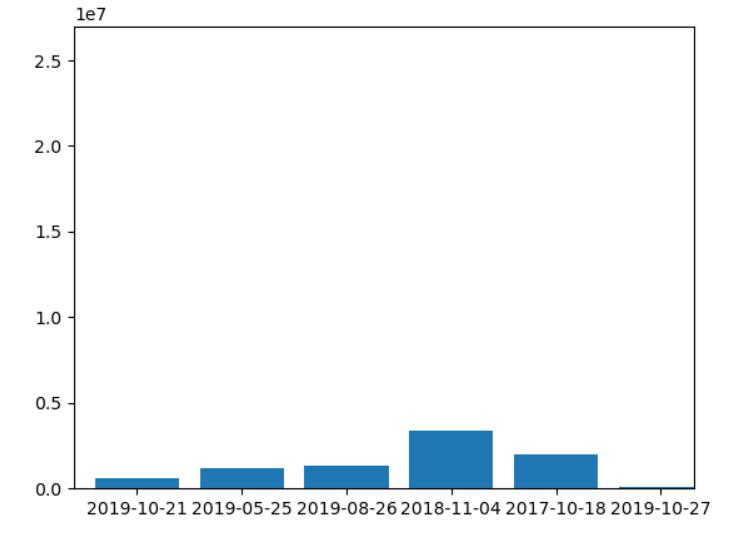
plt自带的放大功能可看

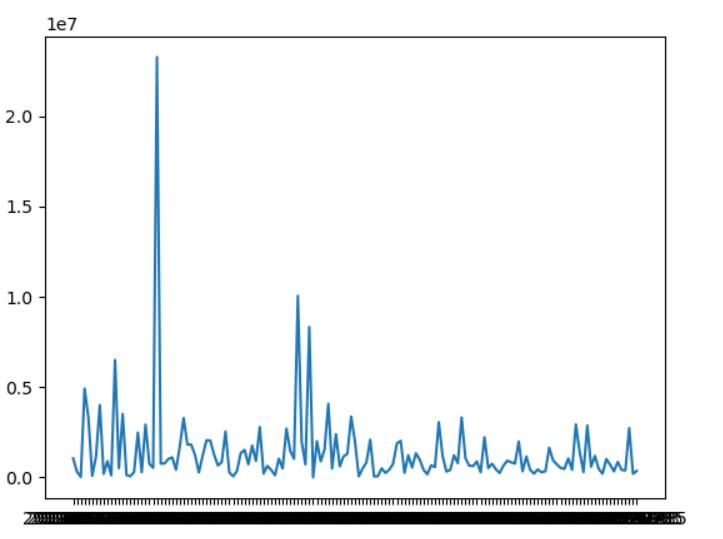

用户体验可能差了点,标题忘记改了
但是程序命名上有所体现
这只是一部分功能,具体功能可以查看代码有注释
5.数据持久化
使用模块化开发,模块为dataSave,代码在如下



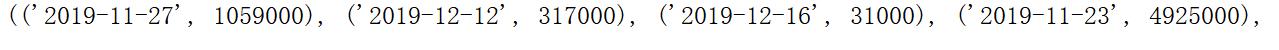
6.附完整程序代码
creeperBm模块:
#数据爬取加清洗模块,比较懒,放一起简单,主要是爬取B站搜索界面的一些视频信息。信息比较少也是因为懒。但是核心功能是有完成的。
#导入模块,这个不用多说了吧
import requests
from bs4 import BeautifulSoup
from dataSave import dataSave
import time
import numpy as np
import re
#定义creeper类,实现爬取和清洗功能
class creeper(object):
#初始化
def __init__(self):
pass
# def creeperHtmlUrl(self,url):
# reader=requests.get(url)
# print(reader.text.title())没有用到
#B站搜索界面爬取获取reader url=路径 kw为关键词默认新宝岛,part为页数默认1 return reader
def creeperSearchAll(self, url="https://search.bilibili.com/all", *, kw=\'新宝岛\', part=1):
reader = requests.get(url, params={"keyword": kw, "page": part})
return reader
# def creeperVideoHtmlAv(self,url="https://www.bilibili.com/video/",av="av53851218"):
# reader = requests.get(url+av)没有用到
# def creeperVideoOnAv(self,url="https://www.bilibili.com/video/",av="av53851218"):
# reader = requests.get(url + av)
#数据获取VideoName list表
def creeperVideoName(self,reader):
bs = BeautifulSoup(reader.text, "html.parser")
videoli = bs.find_all("li", class_="video-item matrix")
listVN=[]
for item in videoli:
# print(item.a["title"])#获取视频名
listVN.append(item.a["title"])
return listVN
# 数据获取PlayTime list表
def creeperPlayTime(self,reader):
bs = BeautifulSoup(reader.text, "html.parser")
videoli = bs.find_all("li", class_="video-item matrix")
listPT = []
for item in videoli:
videotime = item.find_all("span", class_="so-imgTag_rb")
for i in videotime :
# print(i.get_text()) #视频长度
listPT.append(i.get_text())
return listPT
# 数据获取PlayNum list表
def creeperPlayNum(self,reader):
bs = BeautifulSoup(reader.text, "html.parser")
videoli = bs.find_all("li", class_="video-item matrix")
listPN=[]
for item in videoli:
time = item.find_all("span", title="观看")
for i in time:
# print(i.get_text())
if ("万") in i.get_text().strip():
listPN.append(int(float(i.get_text().strip()[0:-1])*10000))
else:
listPN.append(int(i.get_text().strip()))
return listPN
# 数据获取VideoTime list表
def creeperVideoTime(self,reader):
bs = BeautifulSoup(reader.text, "html.parser")
videoli = bs.find_all("li", class_="video-item matrix")
listVT=[]
for item in videoli:
time = item.find_all("span", title="上传时间")
for i in time:
# print(i.get_text())
listVT.append(i.get_text().strip())
return listVT
# 数据获取DanNum list表
def creeperDanNum(self,reader):
bs = BeautifulSoup(reader.text, "html.parser")
videoli = bs.find_all("li", class_="video-item matrix")
listDN=[]
for item in videoli:
dan=item.find_all("span", title="弹幕")#弹幕数量可迭代
for i in dan:
# print(i.get_text())
if ("万") in i.get_text().strip():
listDN.append(int(float(i.get_text().strip()[0:-1])*10000))
else:
listDN.append(int(i.get_text().strip()))
return listDN
#多页爬取信息并持久化处理 入参page,kw为关键字,默认新宝岛
def creeperAllForPage(self,page,kw=\'新宝岛\'):
mysql = dataSave()
db = mysql.initMySql()
cur= db.cursor()
for part in range(page):
crer=creeper()
readerpart=crer.creeperSearchAll( "https://search.bilibili.com/all", kw=kw ,part=part+1)
if crer.creeperVideoName(readerpart)==[]:
break
listVN=crer.creeperVideoName(readerpart)
listPT=crer.creeperPlayTime(readerpart)
listDN=crer.creeperDanNum(readerpart)
listPN=crer.creeperPlayNum(readerpart)
listVT=crer.creeperVideoTime(readerpart)
for i in range(len(listVN)):
# print(range(len(listVN)))有点坑必须赋值之后再添加
datai={"videoname":listVN[i],"playtime":listPT[i],"dannum":listDN[i],"playnum":listPN[i],"videotime":listVT[i]}
mysql.addToTable(db=db,cur=cur,kwargs=datai)
print("页数较多会比较慢,请耐心等待")
cur.close()
db.close()
dataSave模块:
#工作太忙,代码基本写死了,可扩展性较弱,不过还行
#实际使用请自己建立数据库,实现数据的持久化
#127.0.0.1本地连接,你们连接不上运行肯定会出错的
#代码的优化还有可扩展性比较糟糕,不过就这样了,没时间了
#基本实现数据的持久化。creat、updata没做,不过基本不会用到
import pymysql
#类dataSave
class dataSave(object):
#类初始化
def __init__(self):
pass
#初始化mysql连接
def initMySql(self):
config = {
"host": "localhost",
"user": "root",
"password": "1qaz@WSX",
"port": 3308,
"database": "python_creeper",
}
db = pymysql.connect(**config)
return db
#创建表,没做,可扩展项目
def creatTable(self):
pass
#添加记录,基本就是简单的sql语句插入记录,写死了。
def addToTable(self,*,db,cur,kwargs):
sql ="INSERT INTO b_creeper(" \\
"video_name,play_time,dan_num,play_num,video_time)" \\
"values(%s,%s,%s,%s,%s)"
# cur.execute(sql,("1","1",3,4,"5"))
cur.execute(sql,(kwargs["videoname"],kwargs["playtime"],kwargs["dannum"],kwargs["playnum"],kwargs["videotime"]))
db.commit()
data = cur.fetchall()
# 清空记录,基本就是简单的sql语句,写死了。(每次换关键词爬取就要清空一次,比较局限,防止数据冲突)
def deleteToTableAll(self):
mysql = dataSave()
db = mysql.initMySql()
cur = db.cursor()
cur.execute("truncate table b_creeper ")
cur.close()
db.close()
#查询记录个数
def queryNum(self,*,db,id):
cur = db.cursor()
cur.execute("select count(1) from a_student ")
data = cur.fetchall()
cur.close()
db.close()
#查询列video_time和play_num
def queryTimeToNum(self):
mysql =dataSave()
db=mysql.initMySql()
cur=db.cursor()
cur.execute("SELECT video_time,play_num from b_creeper GROUP BY video_time ")
data = cur.fetchall()
cur.close()
db.close()
return data
#查询列video_time,dan_num
def queryTimeToDNum(self):
mysql =dataSave()
db=mysql.initMySql()
cur=db.cursor()
cur.execute("SELECT video_time,dan_num from b_creeper GROUP BY video_time ")
data = cur.fetchall()
cur.close()
db.close()
return data
#查询列video_time和其对应个数count(video_time)
def queryTimeToCNum(self):
mysql =dataSave()
db=mysql.initMySql()
cur=db.cursor()
cur.execute("SELECT video_time,count(video_time) from b_creeper GROUP BY video_time ")
data = cur.fetchall()
cur.close()
db.close()
return data
#查询列dan_num
def queryDanNumToBox(self):
mysql =dataSave()
db=mysql.initMySql()
cur=db.cursor()
cur.execute("SELECT dan_num from b_creeper ")
data = cur.fetchall()
cur.close()
db.close()
return data
#查询列play_num
def queryPlayNumToBox(self):
mysql =dataSave()
db=mysql.initMySql()
cur=db.cursor()
cur.execute("SELECT play_num from b_creeper ")
data = cur.fetchall()
cur.close()
db.close()
return data
printShow模块:
from creeperBm import creeper
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#printShow数据可视化类,只做了简单的数据的条形统计,折线,还有箱型图,其他的没做
class printShow(object):
def __init__(self):
pass
#以下都是绘制统计图,传入所需参数Bar条形,Plot折线,box箱型
#大部分都是重复的
def timeToNumBar(self,*,data):
listVT = []
listPN = []
for item in data:
listVT.append(item[0])
listPN.append(item[1])
plt.figure()
plt.bar(listVT, listPN)
plt.show()
def timeToNumPlot(self,*,data):
listVT = []
listPN = []
for item in data:
listVT.append(item[0])
listPN.append(item[1])
plt.figure()
plt.plot(listVT, listPN)
plt.show()
def timeToDNumBar(self,*,data):
listVT = []
listDN = []
for item in data:
listVT.append(item[0])
listDN.append(item[1])
plt.figure()
plt.bar(listVT, listDN)
plt.show()
def timeToDNumPlot(self,*,data):
listVT = []
listDN = []
for item in data:
listVT.append(item[0])
listDN.append(item[1])
plt.figure()
plt.plot(listVT, listDN)
plt.show()
def timeToCNumBar(self,*,data):
listVT = []
listCN = []
for item in data:
listVT.append(item[0])
listCN.append(item[1])
plt.figure()
plt.bar(listVT, listCN)
plt.show()
def timeToCNumPlot(self,*,data):
listVT = []
listCN = []
for item in data:
listVT.append(item[0])
listCN.append(item[1])
plt.figure()
plt.plot(listVT, listCN)
plt.show()
def danNumBox(self,*,data):
df = pd.DataFrame(data)
df.boxplot()
plt.show()
def playNumBox(self,*,data):
df = pd.DataFrame(data)
df.boxplot()
plt.show()
creeperMain:
#本来想做一个较为系统的但是能力不够啊。所以我只做了个大概。
#可扩展性不强,很多地方偷懒数据、方法直接写死了。
#B站现在官方也不开放api了,野生的基本挂了,爬取视频比较麻烦。
#所以现在就只是基本完成功能,数据爬取,清洗,持久化、可视化处理。除了爬取跟清洗我一起做了其他都是一部分一个python模块
#搜索仅仅限于50页,最高的精度了。B站搜索最高1000的记录,更早的搜索不出来。
#本程序可以更换关键词,有可扩展性,以另外一种方式实现了对于数据条数的要求,有多少个关键词就有多少的记录
#模块化开发,有挺多的功能的,所以我就不一一写了
#每个部分去掉*号就可以执行,有关数据库的,要自己安装,更改配置。我用的本地自己的数据库,外网是不可能连接到的。
from creeperBm import creeper
from printShowM import printShow
from dataSave import dataSave
from bs4 import BeautifulSoup
import requests
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#打印网页html
# c=creeper()
# reader=c.creeperSearchAll("https://search.bilibili.com/all",kw="python",part=1)
# print(reader.text)
#获取listVN
# c=creeper()
# reader=c.creeperSearchAll("https://search.bilibili.com/all",kw="python",part=1)
# listVN=c.creeperVideoName(reader)
# print(listVN)
#删除所有记录
# mysql = dataSave()
# db = mysql.initMySql()
# mysql.deleteToTableAll()
#爬取多页信息存储持久化 20页,可以更多最多50,记得删除记录
# c=creeper()
# c.creeperAllForPage(20,kw="英雄联盟")
#查询列video_time和play_num
# d=dataSave()
# data=d.queryTimeToNum()
# print(data)
#数据可视化模块
# d=dataSave()
# p=printShow()
# data=d.queryTimeToNum()
# p.timeToNumBar(data=data)
#数据可视化模块plot
# d=dataSave()
# p=printShow()
# data=d.queryTimeToNum()
# p.timeToNumPlot(data=data)
#数据可视化模块box
# d=dataSave()
# p=printShow()
# data=d.queryDanNumToBox()
# p.danNumBox(data=data)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
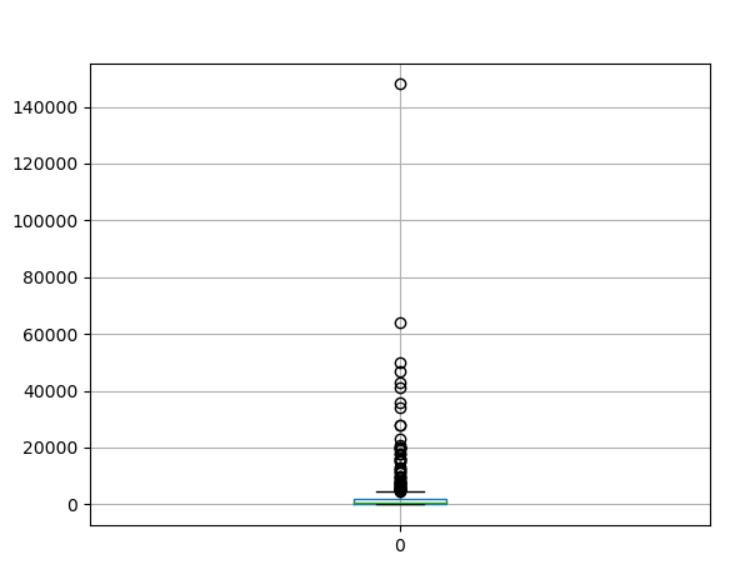
1.对弹幕数来说英雄联盟关键词在B站的弹幕数主要集中在2000以下,少数会超过10000,所以所在B站做视频还是挺辛苦的,处于中下游的up主居多。
2.对于视频和播放数柱状图和折线图来说B站的视频播放数一般会在有节日意义的日子变多,比如12.12日、11月11日等
3.对于视频和弹幕数柱状图和折线图来说B站的视频弹幕数一般会在有节日意义的日子变多,比如12.12日、11月11日等
4.从我未列举出来的数据表(视频的上传时间统计表)可以得出B站up一般会选择在有意义的节日上传视频,来提高播放和弹幕数。
5.根据所有数据可以得出结论,B站有关英雄联盟视频弹幕数主要集中在2000以下,但是也有弹幕数十分多的视频最高可对于140000
2.对本次程序设计任务完成的情况做一个简单的小结。
这次的程序,总体来说较为失败,没有较好的完成先前的指标,临时改变了开发方向,对于用户的体验也不是十分的友好,数据可视化也做的较为糟糕,但是基本来说完成了任务,
数据量的要求还是有达到的,数据的可视化虽然做的不够完善,但是仔细查看代码,会发现,代码的框架和架构还是ok的,不过可扩展性较差,但是基本所有的要求都有达到,
望老师,给个及格。工作了,时间比较少,也没办法。有时间的话可能会填下这个坑,不过,最近基本没时间了。(咕咕咕)以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章