《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,狼来了,狼来了....,狼没来,框架真的来了
Posted 北京-宏哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,狼来了,狼来了....,狼没来,框架真的来了相关的知识,希望对你有一定的参考价值。
1. 简介
前边宏哥一边一边的喊框架,就如同一边一边的喊狼来了!狼来了!.....这回是狼没有来,框架真的来了。从本文开始宏哥将会一步一步介绍,如何从无到有地创建自己的第一个自动化测试框架。这一篇,我们介绍,如何封装自己的日志类和浏览器引擎类。
2. 创建项目层级结构
如何创建,怎么创建。这个就需要我们前边介绍的框架概要设计以及框架的详细设计的思维导图,宏哥就是根据那个图,轻松地、清楚的、思路清晰地一步一步创建项目层级结构。
相关步骤:
1. 打开PyCharm,创建如下格式的项目层级结构,为了避免不必要的麻烦文件名称建议和宏哥保持一样;
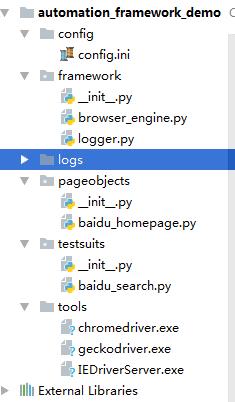
3. 相关文件代码
3.1 config.ini 配置文件
配置文件config.ini相关设计如下:
3.1.1 代码实现:
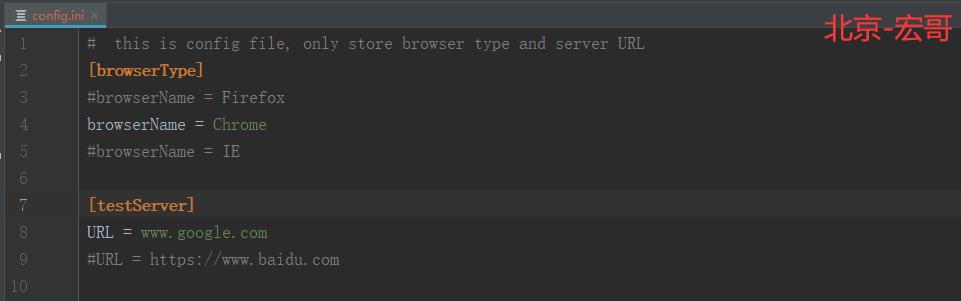
3.1.2 参考代码:
# this is config file, only store browser type and server URL [browserType] #browserName = Firefox browserName = Chrome #browserName = IE [testServer] URL = https://www.baidu.com #URL = www.google.com
3.2 封装浏览器驱动(引擎)类
3.2.1 browser_engine.py 文件
主要目前常用的Chrome、Firefox和IE三大浏览器引擎的封装。
浏览器引擎类browser_engine.py相关脚本代码如下:
3.2.2 代码实现:
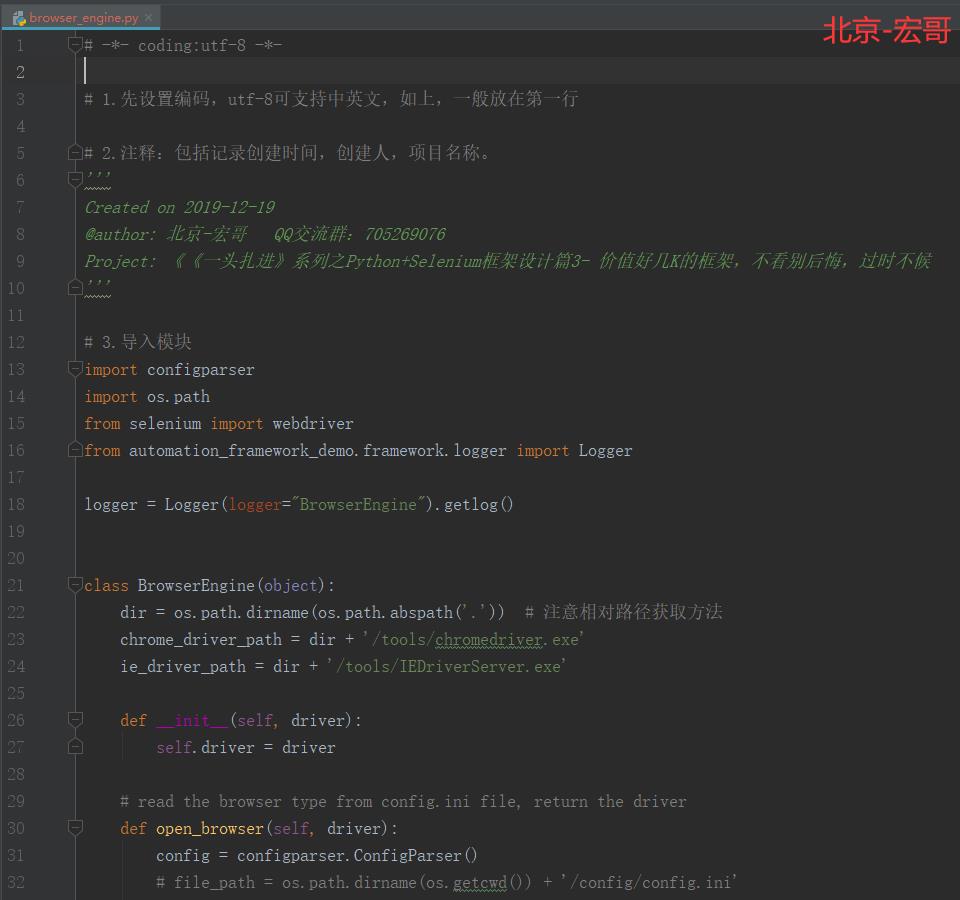
3.2.3 参考代码:
# -*- coding:utf-8 -*- # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 \'\'\' Created on 2019-12-19 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,不看别后悔,过时不候 \'\'\' # 3.导入模块 import configparser import os.path from selenium import webdriver from automation_framework_demo.framework.logger import Logger logger = Logger(logger="BrowserEngine").getlog() class BrowserEngine(object): dir = os.path.dirname(os.path.abspath(\'.\')) # 注意相对路径获取方法 chrome_driver_path = dir + \'/tools/chromedriver.exe\' ie_driver_path = dir + \'/tools/IEDriverServer.exe\' def __init__(self, driver): self.driver = driver # read the browser type from config.ini file, return the driver def open_browser(self, driver): config = configparser.ConfigParser() # file_path = os.path.dirname(os.getcwd()) + \'/config/config.ini\' file_path = os.path.dirname(os.path.abspath(\'.\')) + \'/config/config.ini\' config.read(file_path) browser = config.get("browserType", "browserName")#获取浏览器类型、名字 logger.info("You had select %s browser." % browser) #日志打印你选择的浏览器 url = config.get("testServer", "URL") #获取测试的URL地址 logger.info("The test server url is: %s" % url) #日志打印测试的URL地址 #判断你所选择的浏览器 if browser == "Firefox": driver = webdriver.Firefox() logger.info("Starting firefox browser.") elif browser == "Chrome": driver = webdriver.Chrome(self.chrome_driver_path)#初始化一个实例 logger.info("Starting Chrome browser.") elif browser == "IE": driver = webdriver.Ie(self.ie_driver_path) logger.info("Starting IE browser.") driver.get(url)#访问URL logger.info("Open url: %s" % url) driver.maximize_window() #将窗口放大 logger.info("Maximize the current window.") driver.implicitly_wait(10) logger.info("Set implicitly wait 10 seconds.") print(driver) return driver #关闭浏览器 def quit_browser(self): logger.info("Now, Close and quit the browser.") self.driver.quit()
3.3 封装日志类
3.3.1 logger.py文件
日志类logger.py相关脚本代码如下:
3.3.2 代码实现:

3.3.3 参考代码:
# -*- coding:utf-8 -*- # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 \'\'\' Created on 2019-12-19 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,不看别后悔,过时不候 \'\'\' # 3.导入模块 import logging import logging.handlers import os.path import time class Logger(object): def __init__(self, logger): \'\'\'\'\' 指定保存日志的文件路径,日志级别,以及调用文件 将日志存入到指定的文件中 \'\'\' # 创建一个日志器logger,并设置其日志级别为DEBUG self.logger = logging.getLogger(logger) self.logger.setLevel(logging.DEBUG) # 创建一个handler,用于写入日志文件 rq = time.strftime(\'%Y%m%d%H%M\', time.localtime(time.time())) # log_path = os.path.dirname(os.getcwd()) + \'/Logs/\' # 项目根目录下/Logs 保存日志 log_path = os.path.dirname(os.path.abspath(\'.\')) + \'/logs/\' # 如果case组织结构式 /testsuit/featuremodel/xxx.py , 那么得到的相对路径的父路径就是项目根目录 log_name = log_path + rq + \'.log\' # 创建一个文件处理器handler并设置其日志级别为INFO #fh = logging.FileHandler(log_name, maxBytes=1024 * 1024, backupCount=5, # encoding=\'utf-8\') fh = logging.handlers.RotatingFileHandler(log_name, maxBytes=1024 * 1024, backupCount=5, encoding=\'utf-8\') # 实例化handler #fh = logging.FileHandler(log_name) fh.setLevel(logging.INFO) # 再创建一个handler,用于输出到控制台 \'\'\' 创建一个流处理器handler并设置其日志级别为INFO \'\'\' ch = logging.StreamHandler() ch.setLevel(logging.INFO) # 定义handler的输出格式 #handler = logging.handlers.RotatingFileHandler(fh, maxBytes=1024 * 1024, backupCount=5, # encoding=\'utf-8\') # 实例化handler \'\'\' 创建一个格式器formatter并将 \'\'\' formatter = logging.Formatter(\'%(asctime)s - %(name)s - %(levelname)s - %(message)s\') fh.setFormatter(formatter) ch.setFormatter(formatter) # 给日志处理器logger添加上面创建的handler self.logger.addHandler(fh) self.logger.addHandler(ch) def getlog(self): return self.logger
页面对象pageobject这里暂不用,其实上一篇微博那个小例子已经介绍过了,计划下一篇宏哥再做详细地介绍。
4. 新建测试脚本
4.1 测试脚本baidu_search.py
测试脚本baidu_search.py相关脚本如下:
4.2 代码实现:
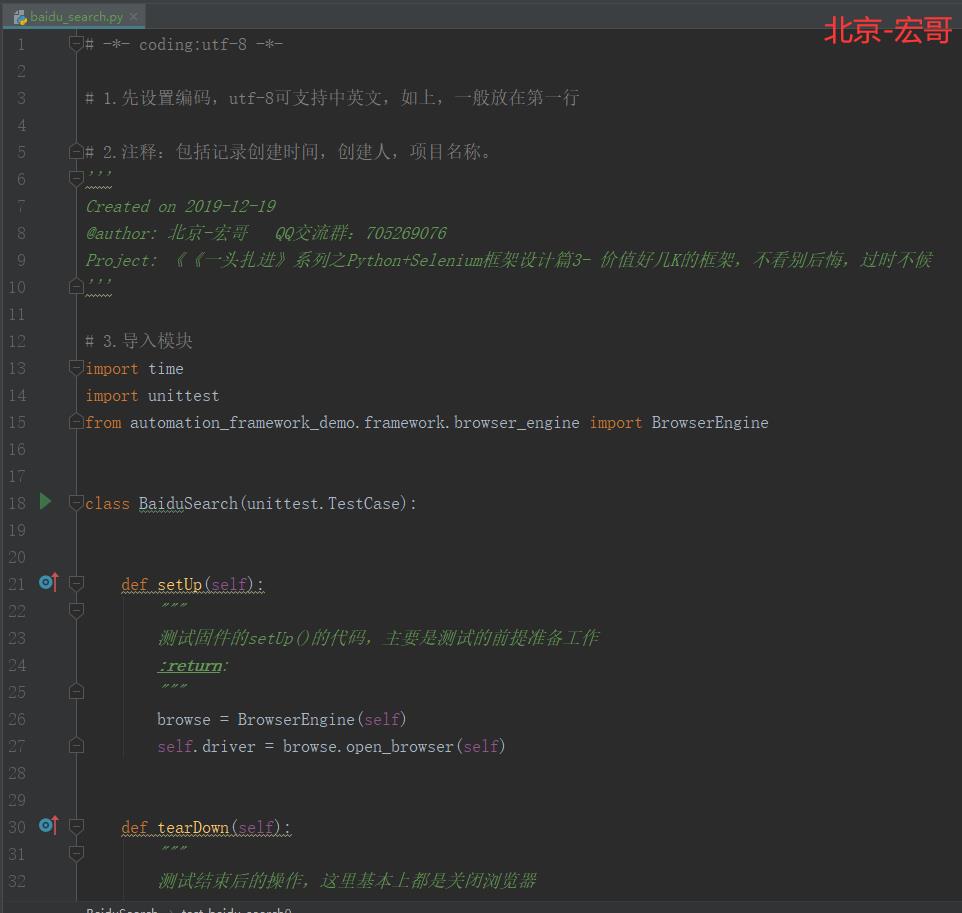
4.3 参考代码:
# -*- coding:utf-8 -*- # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 \'\'\' Created on 2019-12-19 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,不看别后悔,过时不候 \'\'\' # 3.导入模块 import time import unittest from automation_framework_demo.framework.browser_engine import BrowserEngine class BaiduSearch(unittest.TestCase): def setUp(self): """ 测试固件的setUp()的代码,主要是测试的前提准备工作 :return: """ browse = BrowserEngine(self) self.driver = browse.open_browser(self) def tearDown(self): """ 测试结束后的操作,这里基本上都是关闭浏览器 :return: """ self.driver.quit() def test_baidu_search(self): """ 这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。 :return: """ self.driver.find_element_by_id(\'kw\').send_keys(\'selenium\') time.sleep(1) self.driver.find_element_by_id(\'su\').click() time.sleep(5) try: assert \'selenium\' in self.driver.title print (\'Test Pass.\') except Exception as e: print (\'Test Fail.\', format(e)) if __name__ == \'__main__\': unittest.main()
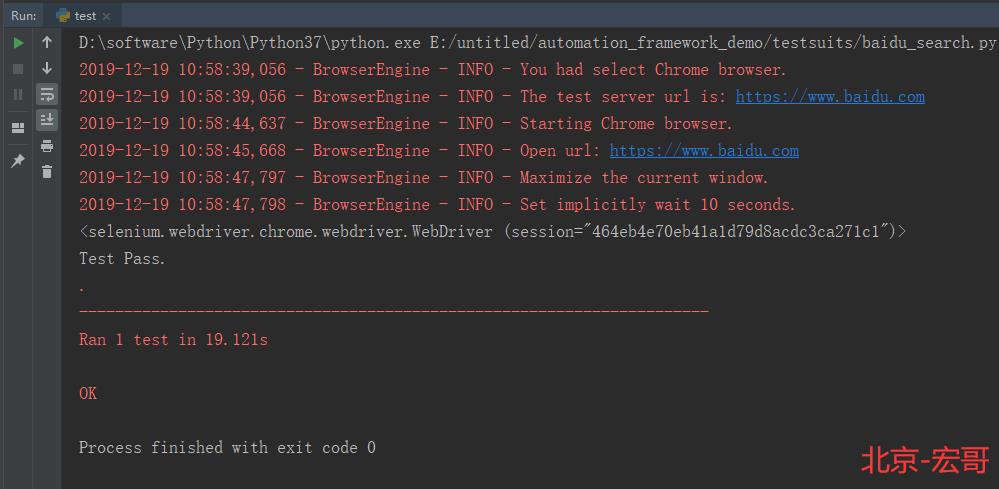
4.4 运行结果:
运行代码后,控制台打印如下图的结果
工具包,这里把三个浏览器的driver文件都放根目录一个文件夹里,这样别人拷贝这个项目也不需要去下载这些文件。
运行测试脚本baidu_search.py,会在根目录下的logs文件生成日志文件,例如宏哥的文件内容:

5.小结
5.1 遇到的一个小问题
问题描述:主要是在断言的时候fail的了,原因是输入selenium后,没有点击查询,于是宏哥加上这段代码
self.driver.find_element_by_id(\'su\').click()
运行后仍然fail的,宏哥猜测是点击后没有出现元素,就去断言,因此又加上了等待的出现的代码,结果pass了
time.sleep(5)
在实践和写代码,运行的过程中,遇到问题就出现在下边的代码里。有兴趣的小伙伴或者童鞋们可以自己注释掉实验一下
def test_baidu_search(self): """ 这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。 :return: """ self.driver.find_element_by_id(\'kw\').send_keys(\'selenium\') time.sleep(1) self.driver.find_element_by_id(\'su\').click() time.sleep(5) try: assert \'selenium\' in self.driver.title print (\'Test Pass.\') except Exception as e: print (\'Test Fail.\', format(e))
好了,今天的分享就到这里吧!!!谢谢各位的耐心阅读。有问题加群交流讨论
您的肯定就是我进步的动力。如果你感觉还不错,就请鼓励一下吧!记得随手点波 推荐 不要忘记哦!!!
别忘了点 推荐 留下您来过的痕迹

以上是关于《一头扎进》系列之Python+Selenium框架设计篇3- 价值好几K的框架,狼来了,狼来了....,狼没来,框架真的来了的主要内容,如果未能解决你的问题,请参考以下文章