Python高级应用程序设计任务
Posted 王志华1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
小米官网爬虫手机类型销量爬虫
2.主题式网络爬虫爬取的内容与数据特征分析:
小米官网爬虫手机类型销量爬虫
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)本次设计方案主要依靠BeautifulSoup库对目标页面进行信息的爬取采集,对数据进行清洗,最后将结果打印出来本次设计方案主要依靠BeautifulSoup库对新浪网访问并采集,最后以txt格式将数据保存在本地。技术难点:爬取数据,遍历标签属性。存储数据表格信息时
实现思路:
(1)利用requests请求网页并爬取目标页面
(2)利用BeautifulSoup解析网页同时获取文件名及目标url链接
二、主题页面的结构特征分析(15分)
1. 1.主题页面的结构特征http://detail.zol.com.cn/cell_phone_index/subcate57_34645_list_1.html
打开小米官网,通过右击鼠-标查看网页源代码,找到对应要爬取的信息

2.Htmls页面解析
使用BeautifulSoup进行网页页面解析,通过观察发现我想要获取的内容是在“div”标签下的“a”标签中。
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import numpy as np
import threading
header={
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36\',
\'cookie\': \'cna=WLxnFpWWi2YCAd5YmGBzb1LE; lid=%E5%A2%A8%E6%83%9C%E5%A6%82%E9%A3%8E; mbk=d104fe4feee1e4c8; enc=ZCXWltgoZbBKllIe42s2UMcdQrPHmbPRvsr5bu64hsyhih2chiIXNMdBlKbSjBosRRqbW8Ba58RiIkOj5bUr1Q%3D%3D; tk_trace=1; t=416ebaf372aac9e714d2411257bebe66; tracknick=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; lgc=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; _tb_token_=e33db43b7fe30; cookie2=130ad5a94570e50984de0fa8439d8b65; dnk=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; uc1=cookie21=VFC%2FuZ9ainBZ&cookie14=UoTbm8RWp827BA%3D%3D&pas=0&existShop=false&lng=zh_CN&cookie15=WqG3DMC9VAQiUQ%3D%3D&tag=8&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D; uc3=nk2=p2MwXab0cT8%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dByus1oAedGs7HXvs%3D&id2=UNDUK%2FSwTIuBMQ%3D%3D; _l_g_=Ug%3D%3D; uc4=nk4=0%40pVXnDf4QgAF6OsvRnr8f86t9pQ%3D%3D&id4=0%40UgckEyzfCeaEbCy9LaVJ3V%2BC1%2B2o; unb=3004348014; cookie1=AVcQal%2F7P9z%2B8EjUWhp7%2BQvoVbt%2Fz5oUDaF9k92YW%2BU%3D; login=true; cookie17=UNDUK%2FSwTIuBMQ%3D%3D; _nk_=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; sg=%E9%A3%8E4e; csg=8ac18de6; l=dBORoGnuqd-_KXXvBOCanurza77OjIRYouPzaNbMi_5Zl6L6H_QOkUgh7Fp6cjWft4TB4dH2-sp9-etkiepTY-cHtBU4RxDc.; isg=BLi41LSjEe7kQn1tu6bgpcSKiWZKIRyr208sQPIpC_OmDVj3mjFoOukrxUUYW9SD\'
}
gLock = threading.Lock() #引入解锁和上锁的类
def get_bar(name,list):
gLock.acquire() #上锁
plt.rcParams[\'font.sans-serif\'] = [\'Microsoft YaHei\'] #显示中文字体
plt.title(\'各品牌手机部分平均价格\') #标题
plt.xlabel(\'品牌\') #x轴标签
plt.ylabel(\'价格\') #同上
colors=[\'yellow\',\'red\',\'blue\',\'green\',\'orange\'] #设置颜色
plt.bar(name,list6,alpha=0.8,color=colors) #开始绘图
plt.show() #展示绘图结果
gLock.release() #解锁
\'\'\'以下五个函数的代码部分是相似的,换句话说是一样的,但是他们传入的参数是不同的,不一一注释了\'\'\'
def get_xiaomi(url):
price_list=[] #价格列表
name_list=[] #名称
txt = requests.get(url, headers=header).text #获取网页内容,携带请求头进行伪装爬虫
bs = BeautifulSoup(txt, \'html.parser\') #设置解析方式
for product in bs.find_all(\'div\', class_="product"): #提取数据,初步筛选信息
price = product.find_all(\'em\')[0][\'title\'] #获取价格
name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') #获取名称,并对民称进行处理
print(price,name) #打印名称和价格
price=float(price) #将字符型价格改为浮点型价格,强制转化
name_list.append(name) #将名字和价格添加进列表
price_list.append(price)
return name_list,price_list
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找:get函数,find。
遍历:for循环嵌套
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。

1.数据爬取与采集
2.对数据进行清洗和处理



3.文本分析(可选):jieba分词、wordcloud可视化
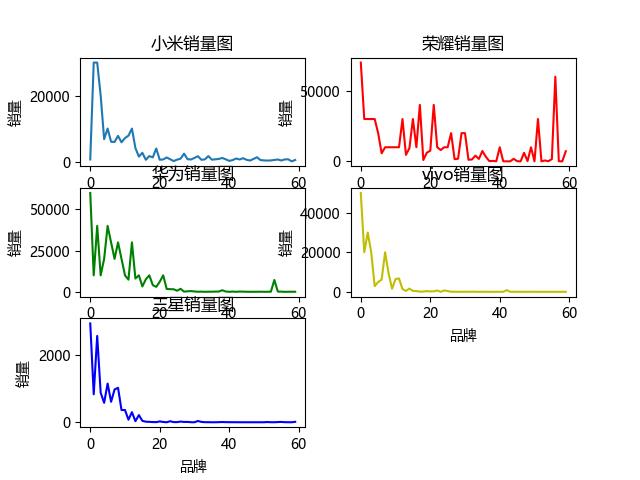
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)

5.数据持久化
def get_sanxing(url): liaoliang_list = [] name_list = [] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') xiaoliang = int(xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) # print(price, name, xiaoliang) return name_list,liaoliang_list def get_figure(name1,list1,name2,list2,name3,list3,name4,list4,name5,list5): plt.rcParams[\'font.sans-serif\'] = [\'Microsoft YaHei\']
完整代码
import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt import time import numpy as np import threading header={ \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36\', \'cookie\': \'cna=WLxnFpWWi2YCAd5YmGBzb1LE; lid=%E5%A2%A8%E6%83%9C%E5%A6%82%E9%A3%8E; mbk=d104fe4feee1e4c8; enc=ZCXWltgoZbBKllIe42s2UMcdQrPHmbPRvsr5bu64hsyhih2chiIXNMdBlKbSjBosRRqbW8Ba58RiIkOj5bUr1Q%3D%3D; tk_trace=1; t=416ebaf372aac9e714d2411257bebe66; tracknick=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; lgc=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; _tb_token_=e33db43b7fe30; cookie2=130ad5a94570e50984de0fa8439d8b65; dnk=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; uc1=cookie21=VFC%2FuZ9ainBZ&cookie14=UoTbm8RWp827BA%3D%3D&pas=0&existShop=false&lng=zh_CN&cookie15=WqG3DMC9VAQiUQ%3D%3D&tag=8&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D; uc3=nk2=p2MwXab0cT8%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dByus1oAedGs7HXvs%3D&id2=UNDUK%2FSwTIuBMQ%3D%3D; _l_g_=Ug%3D%3D; uc4=nk4=0%40pVXnDf4QgAF6OsvRnr8f86t9pQ%3D%3D&id4=0%40UgckEyzfCeaEbCy9LaVJ3V%2BC1%2B2o; unb=3004348014; cookie1=AVcQal%2F7P9z%2B8EjUWhp7%2BQvoVbt%2Fz5oUDaF9k92YW%2BU%3D; login=true; cookie17=UNDUK%2FSwTIuBMQ%3D%3D; _nk_=%5Cu58A8%5Cu60DC%5Cu5982%5Cu98CE; sg=%E9%A3%8E4e; csg=8ac18de6; l=dBORoGnuqd-_KXXvBOCanurza77OjIRYouPzaNbMi_5Zl6L6H_QOkUgh7Fp6cjWft4TB4dH2-sp9-etkiepTY-cHtBU4RxDc.; isg=BLi41LSjEe7kQn1tu6bgpcSKiWZKIRyr208sQPIpC_OmDVj3mjFoOukrxUUYW9SD\' } def get_bar(name,list): plt.rcParams[\'font.sans-serif\'] = [\'Microsoft YaHei\'] plt.title(\'各品牌手机部分总销量\') plt.xlabel(\'品牌\') plt.ylabel(\'销量\') colors=[\'yellow\',\'red\',\'blue\',\'green\',\'orange\'] plt.bar(name,list6,alpha=0.8,color=colors) plt.show() def get_xiaomi(url): liaoliang_list=[] name_list=[] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') # print(price, name, xiaoliang) xiaoliang=int(xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) return name_list,liaoliang_list def get_rongyao(url): liaoliang_list = [] name_list = [] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') xiaoliang = int(xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) return name_list, liaoliang_list def get_huawei(url): liaoliang_list = [] name_list = [] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') xiaoliang = int(xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) # print(price, name, xiaoliang) return name_list,liaoliang_list def get_vivo(url): liaoliang_list = [] name_list = [] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') xiaoliang = int(xiaoliang) # print(price, name, xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) return name_list,liaoliang_list def get_sanxing(url): liaoliang_list = [] name_list = [] txt = requests.get(url, headers=header).text bs = BeautifulSoup(txt, \'html.parser\') for product in bs.find_all(\'div\', class_="product"): # price = product.find_all(\'em\')[0][\'title\'] name = product.find_all(\'a\', attrs={\'target\': "_blank"})[1].text.replace(\'\\n\', \'\') xiaoliang = product.find_all(\'em\')[1].text.replace(\'.0万笔\',\'0000\').replace(\'.\',\'000\').replace(\'笔\',\'\').replace(\'万\',\'\') xiaoliang = int(xiaoliang) name_list.append(name) liaoliang_list.append(xiaoliang) # print(price, name, xiaoliang) return name_list,liaoliang_list def get_figure(name1,list1,name2,list2,name3,list3,name4,list4,name5,list5): plt.rcParams[\'font.sans-serif\'] = [\'Microsoft YaHei\'] fig=plt.figure() ax1=fig.add_subplot(321) ax2=fig.add_subplot(322) ax3=fig.add_subplot(323) ax4=fig.add_subplot(324) ax5=fig.add_subplot(325) name1 = range(len(name1)) name2 = range(len(name2)) name3 = range(len(name3)) name4 = range(len(name4)) name5 = range(len(name5)) ax1.set_title(\'小米销量图\') ax1.set_xlabel(\'品牌\') ax1.set_ylabel(\'销量\') ax1.plot(name1,list1) ax2.set_title(\'荣耀销量图\') ax3.set_xlabel(\'品牌\') ax2.set_ylabel(\'销量\') ax2.plot(name2, list2,\'r\') ax3.set_title(\'华为销量图\') ax3.set_xlabel(\'品牌\') ax3.set_ylabel(\'销量\') ax3.plot(name3, list3,\'g\') ax4.set_title(\'vivo销量图\') ax4.set_xlabel(\'品牌\') ax4.set_ylabel(\'销量\') ax4.plot(name4, list4,\'y\') ax5.set_title(\'三星销量图\') ax5.set_xlabel(\'品牌\') ax5.set_ylabel(\'销量\') ax5.plot(name5, list5,\'b\') plt.savefig(\'多品牌销量图.png\') plt.show() if __name__==\'__main__\': urllist = [ \'https://list.tmall.com/search_product.htm?q=%D0%A1%C3%D7%CA%D6%BB%FA&type=p&vmarket=&spm=875.7931836%2FB.a2227oh.d100&from=mallfp..pc_1_searchbutton\', \'https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000723.1.3e5e17e7HMiPUP&&active=2&from=rs_1_key-top-s&q=%C8%D9%D2%AB%CA%D6%BB%FA\', \'https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000723.1.19364d7ePqKoRA&&active=2&from=rs_1_key-top-s&q=%BB%AA%CE%AA%CA%D6%BB%FA\', \'https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000723.2.4cd110b21pk5Js&&active=2&from=rs_1_key-top-s&q=vivo+%CA%D6%BB%FA\', \'https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000723.6.159e3278ogZpdE&&active=2&from=rs_1_key-top-s&q=%C8%FD%D0%C7+%CA%D6%BB%FA\', ] name1,list1=get_xiaomi(urllist[0]) # get_zexian(name1,list1,\'小米\') # time.sleep(10) name2,list2=get_rongyao(urllist[1]) # get_zexian(name2, list2, \'荣耀\') # time.sleep(10) name3,list3=get_huawei(urllist[2]) # get_zexian(name3, list3, \'华为\') # time.sleep(10) name4,list4=get_vivo(urllist[3]) # get_zexian(name4, list4, \'vivo\') # time.sleep(10) name5,list5=get_sanxing(urllist[4]) list6=[] list6.append(sum(list1)) list6.append(sum(list2)) list6.append(sum(list3)) list6.append(sum(list4)) list6.append(sum(list5)) name=[\'小米\',\'荣耀\',\'华为\',\'vivo\',\'三星\'] get_bar(name,list6) get_figure(name1, list1, name2, list2, name3, list3, name4, list4, name5, list5)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
小米手机还是比较受大众的欢迎的,虽然比起一些新兴企业差了一些,但是从总体的水平来看,还是非常受大众欢迎的
2.对本次程序设计任务完成的情况做一个简单的小结。
做一个任务之前,需要做许多的准备工作,要提前明确自己的目标,构建一个大致的框架,这样到写代码的步骤时才会有条不紊的进行。收集数据时也需要具备明确的目标,微数据分析打好基础。有些数据是隐藏起来的,不能爬取,在确定目标的时候需要注意。这次爬虫,期间遇到了一些小问题,但是也对Python这门语言更加的有兴趣。对自己以后进一步学习编程有了很大帮助。总而言之,遇到了很多难题,也学习到了很多的方法,通过本次课程设计,我受益匪浅。这段时间来,从一开始的不太懂到熟练运用。这次的程序设计很好的巩固了我们所学到的知识,除此之外学到了很多课堂以外的知识。在其中也遇到了很多难题,明白自身要学习的东西还有很多,学无止境,才能更进一步
以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章