Python高级应用程序设计任务
Posted wangjiaping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取携程网站泉州地区酒店信息
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取携程网站泉州地区酒店名称与地址和酒店评分
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:本次设计方案主要使用request库爬取网页信息和beautifulSoup库来提取泉州地区酒店信息
技术难点:主要包括对携程网站泉州地区酒店部分的页面进行分析采集
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
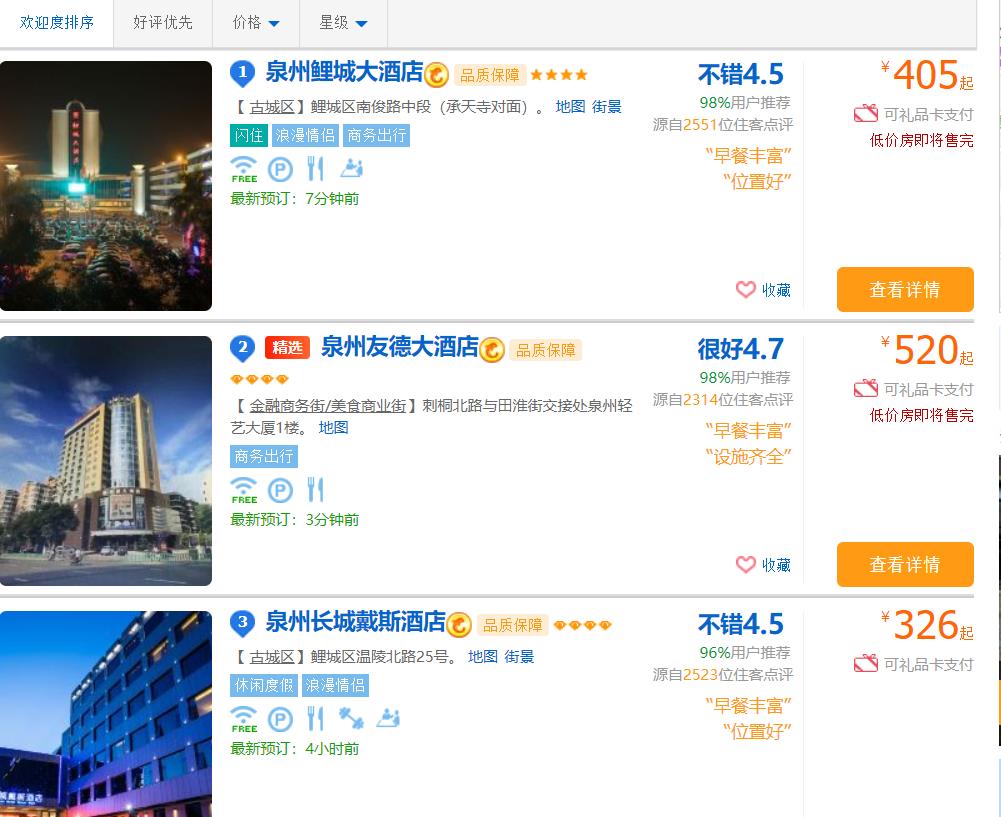
2.Htmls页面解析
通过F12,对页面进行检查,查看我们所需要爬取内容的相关代码
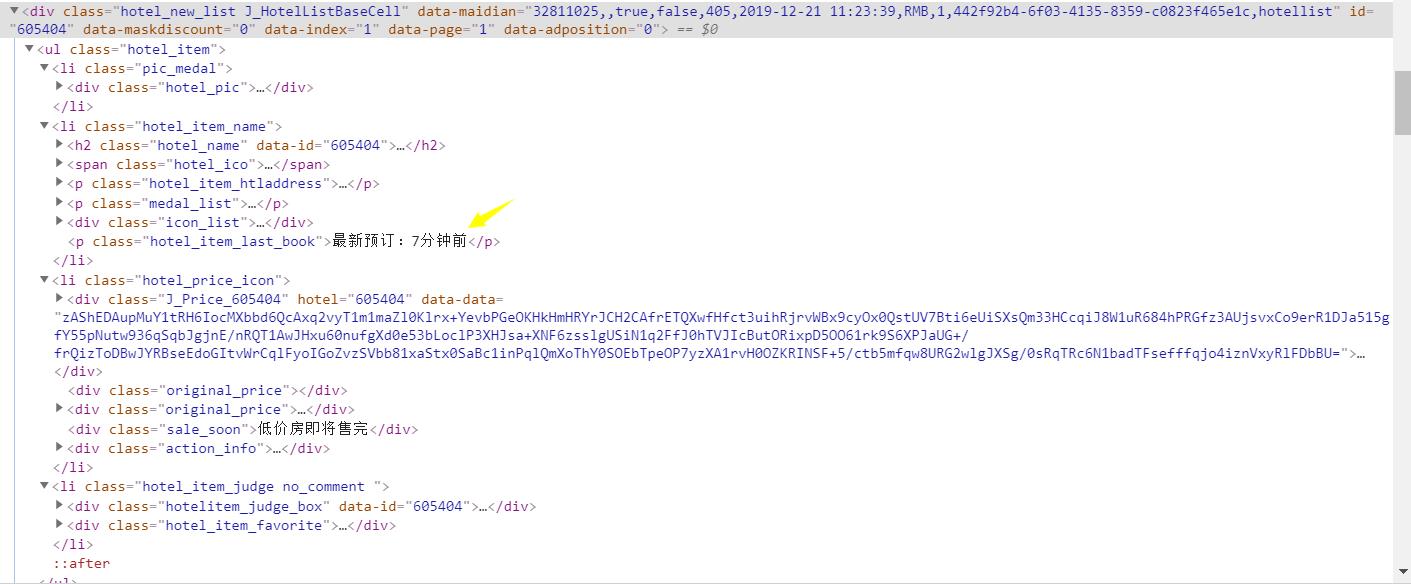
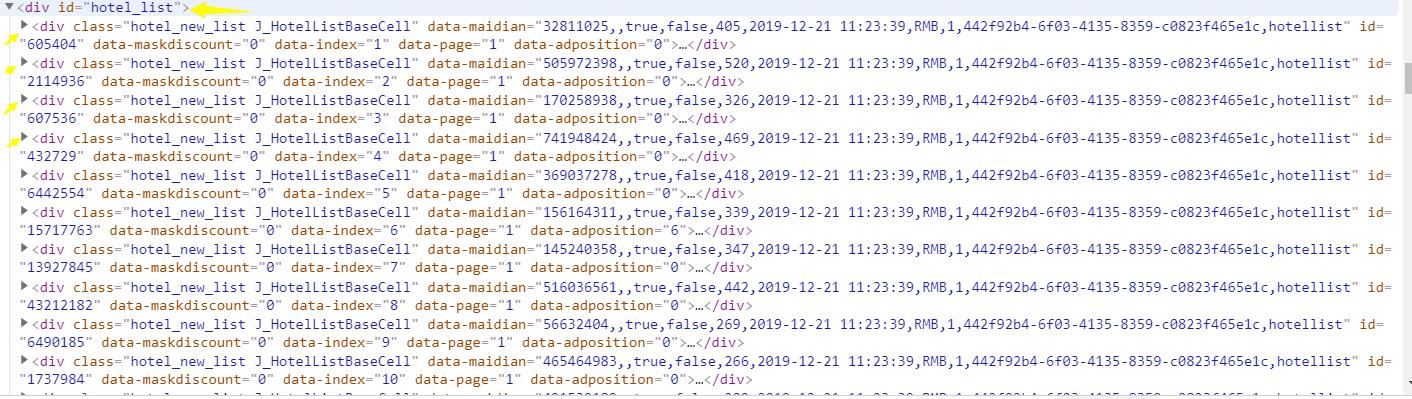
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:find
遍历方法:for循环
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集

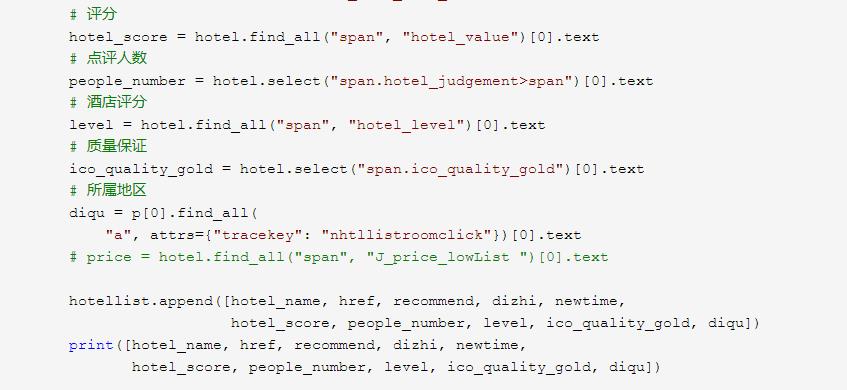
2.对数据进行清洗和处理



3.文本分析(可选):jieba分词、wordcloud可视化
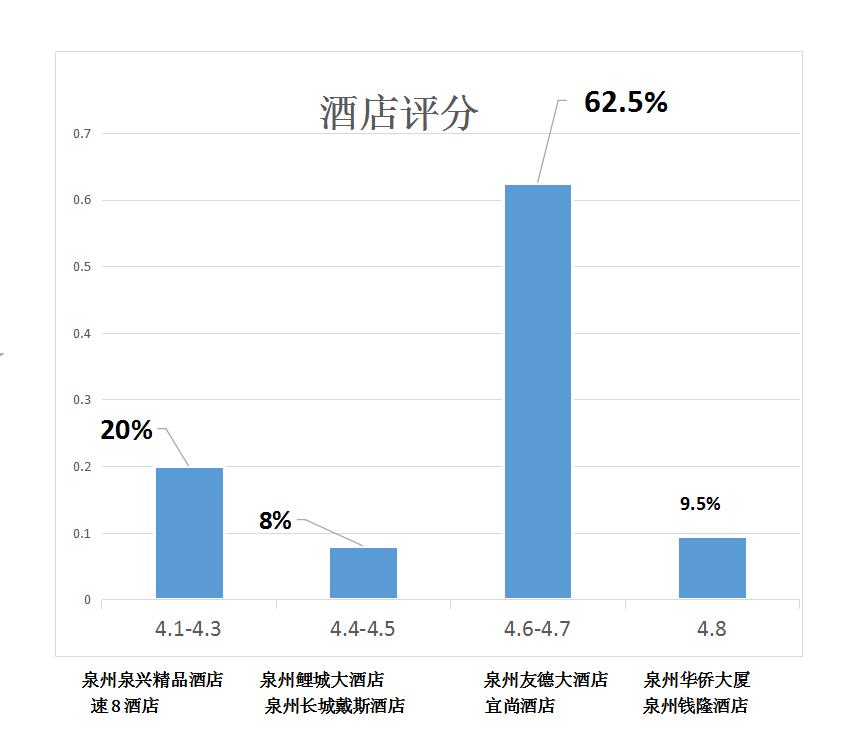
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)


5.数据持久化

6.附完整程序代码
# 导入相关模块 import requests from bs4 import BeautifulSoup import pandas as pd def getHtml(url): # 判断爬取 是否出错 try: # 使用get方式爬取页面,添加头部伪装浏览器 r = requests.get(url, headers={\'user-agent\': \'Mozilla/5.0\'}) r.raise_for_status() # 设置编码格式 r.encoding = r.apparent_encoding # 返回源码 return r.text except: return "页面爬取Error" def HotelList(text,hotellist): soup = BeautifulSoup(text, "html.parser") # 爬取酒店列表 hotel_list = soup.select("div#hotel_list>div") # 循环 for hotel in hotel_list: # 将可能出现错误的地方进行跳过 try: # 酒店名称 hotel_name = hotel.select("h2")[0].text # 酒店链接 href = hotel.select("h2>a")[0].attrs["href"] # 服务贫家 recommend = hotel.select("span.recommend")[0].text p = hotel.select("p.hotel_item_htladdress") # 酒店地址 dizhi = p[0].text # 最新预定时间 newtime = hotel.select("p.hotel_item_last_book")[0].text # 评分 hotel_score = hotel.find_all("span", "hotel_value")[0].text # 点评人数 people_number = hotel.select("span.hotel_judgement>span")[0].text # 酒店评分 level = hotel.find_all("span", "hotel_level")[0].text # 质量保证 ico_quality_gold = hotel.select("span.ico_quality_gold")[0].text # 所属地区 diqu = p[0].find_all( "a", attrs={"tracekey": "nhtllistroomclick"})[0].text # price = hotel.find_all("span", "J_price_lowList ")[0].text hotellist.append([hotel_name, href, recommend, dizhi, newtime, hotel_score, people_number, level, ico_quality_gold, diqu]) print([hotel_name, href, recommend, dizhi, newtime, hotel_score, people_number, level, ico_quality_gold, diqu]) except: "一个数据爬取出错" hotellist.append([hotel_name, href, recommend, dizhi, newtime, hotel_score, people_number, level, ico_quality_gold, diqu]) def savedata(hotellist): wri = pd.ExcelWriter("HotelList.xlsx") col = ["hotel_name", "href", "recommend", "dizhi", "newtime", "hotel_score", "people_number", "level", "ico_quality_gold", "diqu"] pf = pd.DataFrame(hotellist,columns=col) # 写入excel pf.to_excel(wri) wri.save() def main(): # 存放数据的数组 hotellist = [] text = getHtml( "https://hotels.ctrip.com/hotel/quanzhou406#ctm_ref=hod_hp_sb_lst") HotelList(text, hotellist) #打印结果信息 print(hotellist) # 数据保存 savedata(hotellist)

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对泉州地区酒店的爬取,可以知道每个酒店的具体名称和地址还有酒店评分,由此可知泉州华侨大厦和希岸酒店,泉州钱隆酒店的评分最高;泉州泉兴精品酒店评分最低。
泉州酒店点评人数最多,泉州钱隆酒店点评人数最少。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
我觉得这次爬虫的内容还挺有意思的,也让我学到了很多书本以外的知识,一步一步自己探索出来,遇到不懂的问题及时问同学答疑解惑。这一次任务按照老师的要求一步一步来实现,虽然有一些没有完全实现出来,还存在在很多问题,但是发现问题多了也就能及时查缺补漏,让我们对Python这门语言有了更深的理解,也让我增加了更多的兴趣对于这个课程,能够让自己能更好地进步。
以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章