Python高级应用程序设计任务要求
Posted 蔡晓玉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务要求相关的知识,希望对你有一定的参考价值。
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
主题名称:豆瓣音乐专区的摇滚音乐
2.主题式网络爬虫爬取的内容与数据特征分析
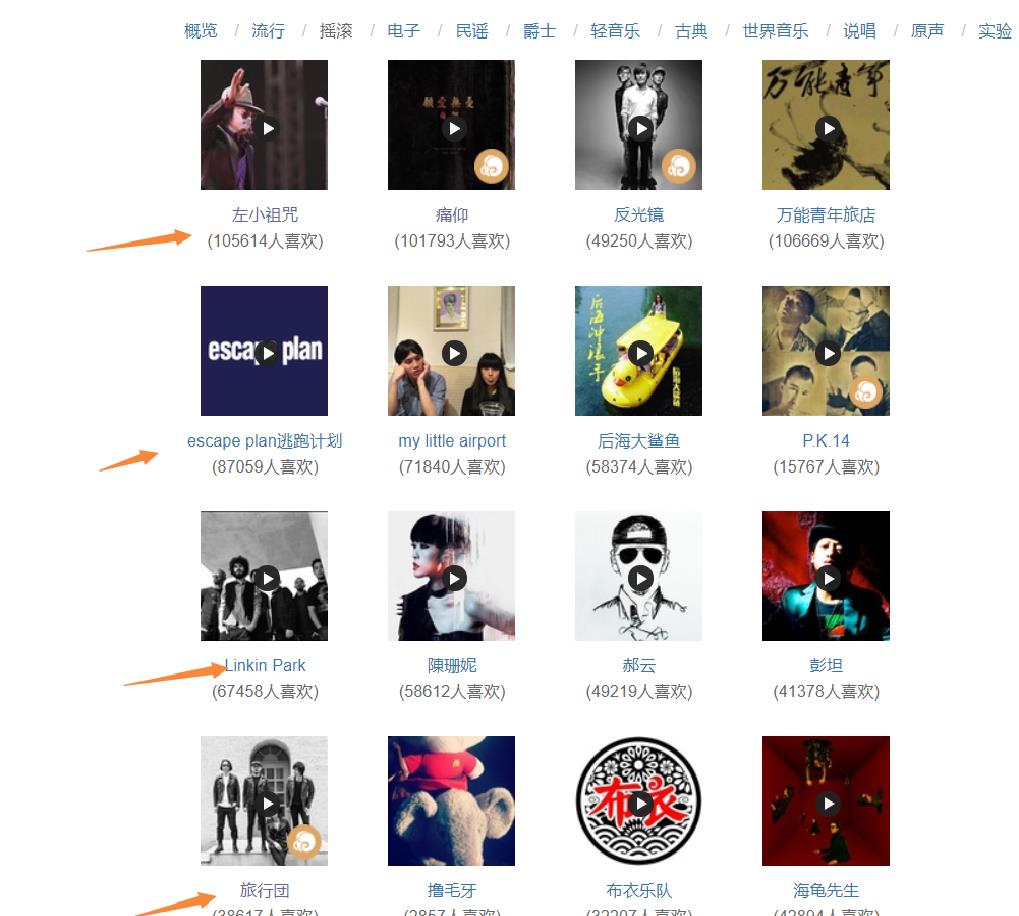
爬取豆瓣音乐专区的摇滚音乐歌手、链接及受喜爱的人数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:爬取获得的豆瓣音乐的HTML页面,使用BeautifulSoup类解析html文本,使用pandas进行数据的存储、读取以及保存
技术难点:将不同的数据保存在Excel文档中
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
打开豆瓣音乐的官网,点击鼠标右键按“查看元素”或按“F12”打开网页源代码,查找自己所要爬取的内容
2.Htmls页面解析
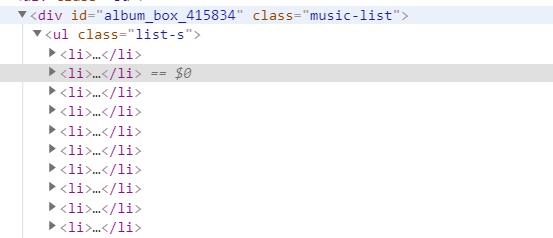
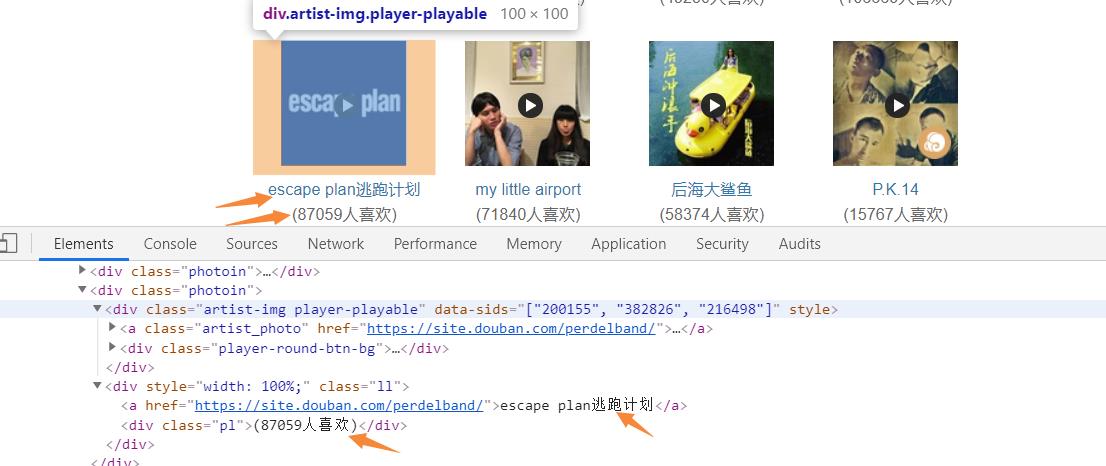
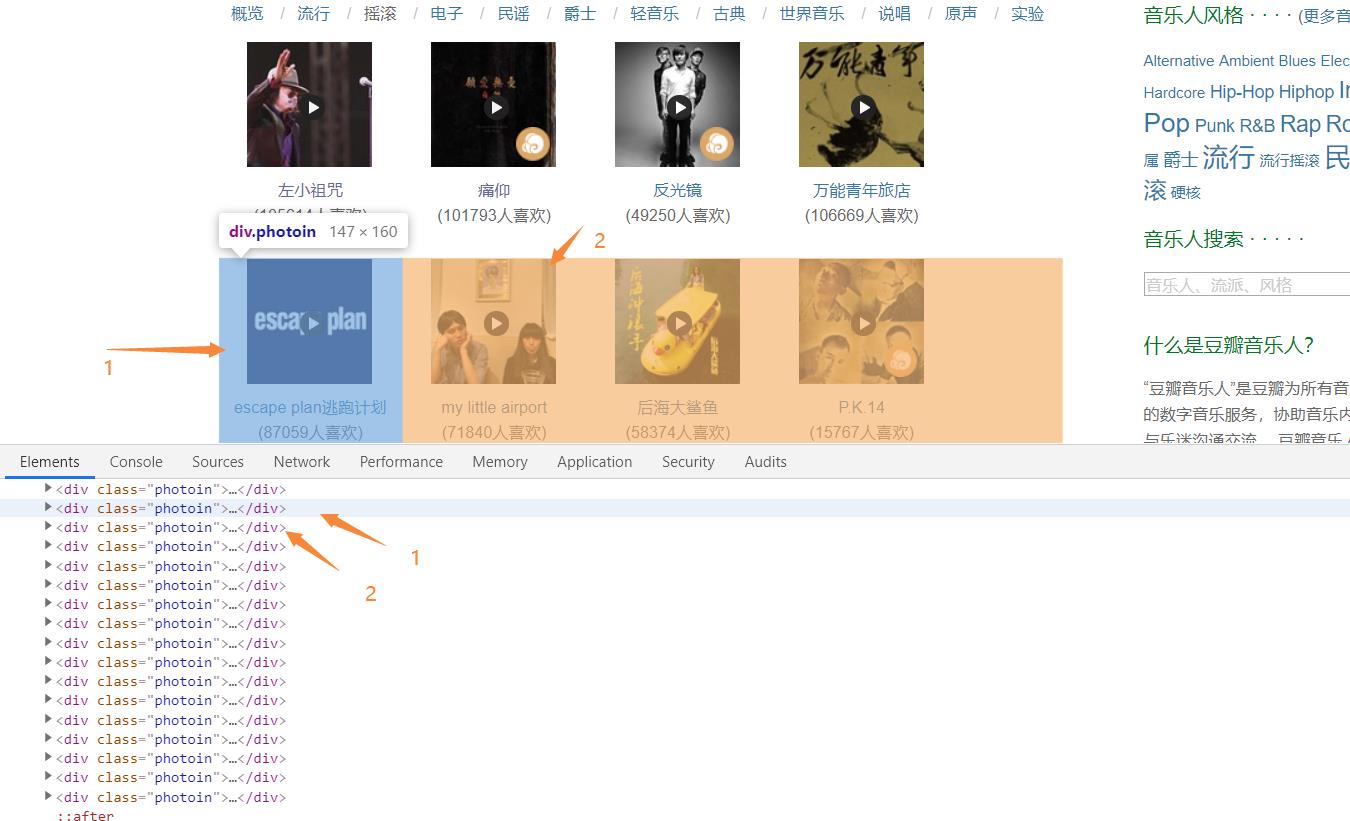
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:find
遍历方法:for循环嵌套
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt import re import seaborn as sns import numpy as np def getHtml(url): #获取网页数据 try: r = requests.get(url, headers={\'user-agent\': \'Mozilla/5.0\'}) r.raise_for_status() return r.text except: return "页面爬取错误" def beautifulSoup(html, artistList): List = [] #使用BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") clearfix = soup.find_all("div", "clearfix")[1] # 爬取列表标签 photoins = clearfix.find_all("div", "photoin") # 循环列表 for photoin in photoins: div = photoin.find("div", "ll") # 歌手 singer_name = div.find("a").text # 链接 singer_href = div.find("a").attrs["href"] # 喜欢人数 like_num = div.find("div").text artistList.append([singer_name, singer_href, like_num]) # 输入爬取页数 def numpage(n,artistList,urls): # 随机生成index,爬取指定页数数据 for i in range(1,n+1): # 拼接url地址 url = "https://music.douban.com/artists/genre_page/8/"+str(i) # 获取源码 html = getHtml(url) # 数据添加=到数组中 beautifulSoup(html, artistList) # 保存数据 def saveexcel(artistList): save = pd.ExcelWriter("singerList.xlsx") #指定列名 column = ["singer_name", "singer_href", "like_num"] # 生成DataFrame格式数据 pf = pd.DataFrame(artistList,columns=column) # 使用pandas将DataFrame存入excel表格中 pf.to_excel(save) save.save() def readExcel(path): singerdetailslist = pd.read_excel(path) for i in singerdetailslist[\'singer_href\']: try: text = getHtml(i) soup = BeautifulSoup(text, "html.parser") sp_logo = soup.select("div.sp-logo")[0].text.strip() try: # 获取所有专辑信息 albums = soup.select("div#album_box_415834")[0].text.strip() except: albums = "" bulletin_content = soup.select( "div#link-report415877")[0].text.strip() print(albums) except: bulletin_content = "" # 运行 def run(): artistList = [] urls = [] # 爬取5个页面的数据 numpage(5, artistList,urls) # 数据持久化 saveexcel(artistList) path = "singerList.xlsx" def run2(): readExcel("singerList.xlsx") run()
1.数据爬取与采集
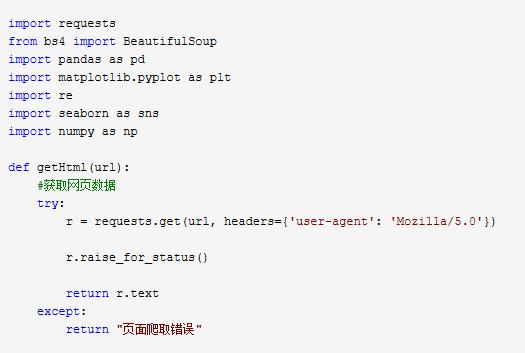
2.对数据进行清洗和处理



3.文本分析(可选):jieba分词、wordcloud可视化
5.数据持久化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
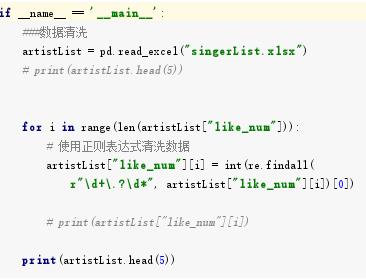


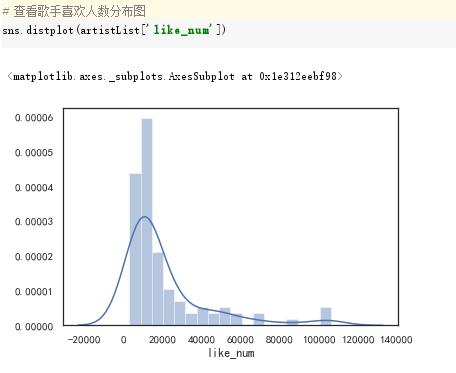
5.数据持久化

6.附完整程序代码
import requests from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt import re import seaborn as sns import numpy as np def getHtml(url): #获取网页数据 try: r = requests.get(url, headers={\'user-agent\': \'Mozilla/5.0\'}) r.raise_for_status() return r.text except: return "页面爬取错误" def beautifulSoup(html, artistList): List = [] #使用BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") clearfix = soup.find_all("div", "clearfix")[1] # 爬取列表标签 photoins = clearfix.find_all("div", "photoin") # 循环列表 for photoin in photoins: div = photoin.find("div", "ll") # 歌手 singer_name = div.find("a").text # 链接 singer_href = div.find("a").attrs["href"] # 喜欢人数 like_num = div.find("div").text artistList.append([singer_name, singer_href, like_num]) # 输入爬取页数 def numpage(n,artistList,urls): # 随机生成index,爬取指定页数数据 for i in range(1,n+1): # 拼接url地址 url = "https://music.douban.com/artists/genre_page/8/"+str(i) # 获取源码 html = getHtml(url) # 数据添加=到数组中 beautifulSoup(html, artistList) # 保存数据 def saveexcel(artistList): save = pd.ExcelWriter("singerList.xlsx") #指定列名 column = ["singer_name", "singer_href", "like_num"] # 生成DataFrame格式数据 pf = pd.DataFrame(artistList,columns=column) # 使用pandas将DataFrame存入excel表格中 pf.to_excel(save) save.save() def readExcel(path): singerdetailslist = pd.read_excel(path) for i in singerdetailslist[\'singer_href\']: try: text = getHtml(i) soup = BeautifulSoup(text, "html.parser") sp_logo = soup.select("div.sp-logo")[0].text.strip() try: # 获取所有专辑信息 albums = soup.select("div#album_box_415834")[0].text.strip() except: albums = "" bulletin_content = soup.select( "div#link-report415877")[0].text.strip() print(albums) except: bulletin_content = "" # 运行 def run(): artistList = [] urls = [] # 爬取5个页面的数据 numpage(5, artistList,urls) # 数据持久化 saveexcel(artistList) path = "singerList.xlsx" def run2(): readExcel("singerList.xlsx") run()

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
喜欢万能青年旅店歌手的人占的比例最大,喜欢窦唯歌手的占的比例较小
在摇滚音乐中越年轻的歌手受欢迎的程序越高
2.对本次程序设计任务完成的情况做一个简单的小结。
此次的程序设计让我进一步的了解了Python这门语言,在爬取的过程中也遇到了很多的问题,一开始的选题在后面的爬取的过程中发现相关数据被隐藏了,导致数据无法爬取成功,于是换了一个新的选题,在爬取数据的过程中让我不断学习到了新知识,也让我明白了爬取之前的目标要明确以及对于数据采集的方向要有一个明确的选择,这次的程序设计也让我对Python更加的感兴趣了。
以上是关于Python高级应用程序设计任务要求的主要内容,如果未能解决你的问题,请参考以下文章