13.0 序
这一章我们就来看看python中类是怎么实现的,我们知道C不是一个面向对象语言,而python却是一个面向对象的语言,那么在python的底层,是如何使用C来支持python实现面向对象的功能呢?带着这些疑问,我们下面开始剖析python中类的实现机制。另外,在python2中存在着经典类(classic class)和新式类(new style class),但是到Python3中,经典类已经消失了。并且python2官网都快不维护了,因此我们这一章只会介绍新式类。
13.1 python中的对象模型
我们在第一章python对象初探的时候就说了,在面向对象的理论中,有两个核心的概念:类和实例。类可以看成是一个模板,那么实例就是根据这个模板创建出来的对象。可以想象成docker的镜像和容器。但是在python中,一切都是对象,所以类和实例都是对象,类叫做类对象,实例叫做实例对象。如果想用大白话来描述清楚的话,这无疑是一场灾难,我们还是需要使用一些专业术语来描述:
首先我们这里把python中的对象分为三种
内建对象:python中的内建对象,比如int、str、list、type、object等等class对象:程序员通过python中的class关键字定义的类。当然后面我们也会把内建对象和class对象统称为类对象的实例对象:表示由内建对象或者class对象创建的实例
13.1.1 对象间的关系
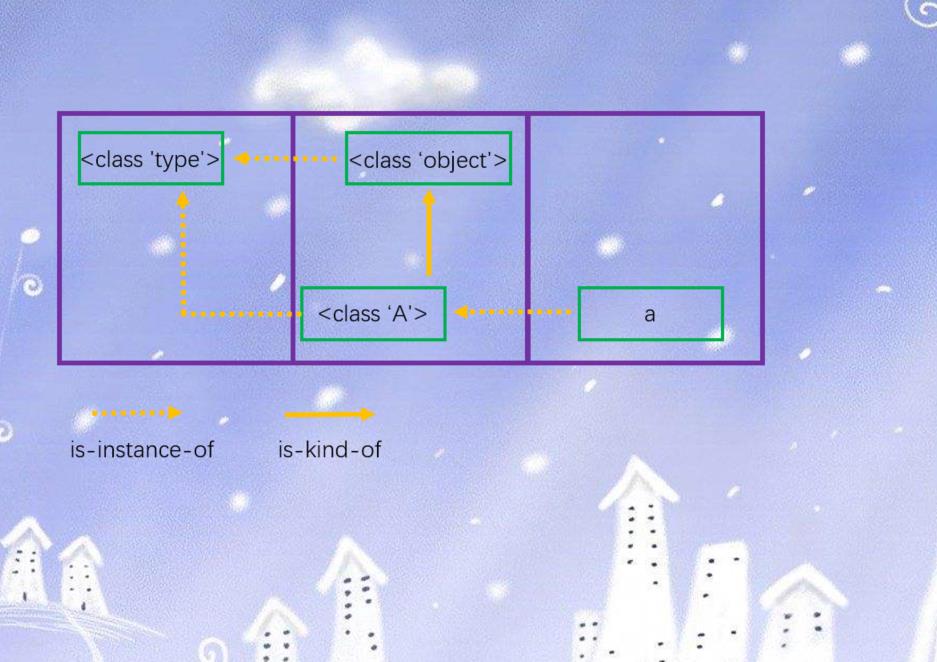
python的三种对象之间,存在着两种关系
is-kind-of:对应面向对象理论中父类和子类之间的关系is-instance-of:对应面向对象理论中类和实例之间的关系
class A(object):
pass
a = A()
这段代码中便包含了上面的三种对象:object(内建对象),A(class对象),a(实例对象)。显然object和A之间是is-kind-of关系,即object是A的父类,另外值得一提的是,在python3中所有定义的类都是默认继承自object,即便我们这里不显式写继承object,也会默认继承的,为了说明,我们就写上了。除了object是A的父类,我们还能看出a和A存在is-instance-of关系,即a是A的实例。当然如果再进一步的话,a和object之间也存在is-instance-of关系,a也是object的实例。我们可以使用python查看一下
class A(object):
pass
a = A()
print(type(a)) # <class \'__main__.A\'>
print(isinstance(a, object)) # True
我们看到尽管打印a的类型显示的是A(内建对象、class对象除了表示对象之外,还可以用来表示对应实例的类型,比如这里a的类型就是A),但是a也是object的实例,因为A继承了object,至于这其中的原理,我们会慢慢介绍到。
python中的类型检测
python提供了一些方法可以探测这些关系,除了我们上面的type之外,还可以使用对象的__class__属性探测一个对象和其它的哪些对象之间存在is-instance-of关系,而通过对象的__bases__属性则可以探测一个对象和其它的哪些对象之间存在着is-kind-of关系。此外python还提供了两个方法issubclass和isinstance来验证两个对象之间是否存在着我们期望的关系
class A(object):
pass
a = A()
####################
print(a.__class__) # <class \'__main__.A\'>
print(A.__class__) # <class \'type\'>
# 因为python可以多继承,因为打印的是一个元组
print(A.__bases__) # (<class \'object\'>,)
# 另外__class__是查看自己的类型是什么,也就是生成自己的类。
# 而在介绍python对象的时候,我们就看到了,任何一个对象都至少具备两个东西,一个是引用计数、一个是对象的类型
# 所以__class__在python中,是所有的对象都具备的
# 但是__bases__的话就不一定了,这个属性实例对象是没有的。只有class对象、内建对象才有
# 因此是无法调用a.__bases__的
估计看到这张图就应该知道我想说什么了,里面有着一个非常关键、也是非常让人费解的一个点。我记得之前说过,但是在这里我们再来研究一遍。
13.1.2 <class \'type\'>和<class \'object\'>
首先记住python中关于类的两句话:
所有的类对象(内建对象+class对象)都是由type生成的所有的类对象都继承object
逻辑性比较强的人,可能马上就发现了,这两句话组合起来是存在矛盾的,但是在python中是不矛盾的。我们来看几个例子
class A:
pass
print(type(A)) # <class \'type\'>
print(type(int)) # <class \'type\'>
print(type(dict)) # <class \'type\'>
print(A.__bases__) # (<class \'object\'>,)
print(int.__bases__) # (<class \'object\'>,)
print(dict.__bases__) # (<class \'object\'>,)
# 相信上面的都没有什么问题,但是令人费解的是下面
print(type(object)) # <class \'type\'>
print(type.__bases__) # (<class \'object\'>,).
我们看到object这个对象是由type创建的,但是object又是type的父类,那么这就先入了先有鸡还是先有蛋的问题。其实这两者是同时出现的,只不过在python中把两者形成了一个闭环,也正因为如此,python才能把一切皆对象的理念贯彻的如此彻底。至于type是由谁创建的,很容易猜到是由type自身创建的,连自己都不放过,更不要说其他的类对象了,因次我们也把type称之为metaclass(元类),创建类对象的类。更具体的解释请在前面的章节中翻一翻
我们刚才把python中的对象分成了三类:内建对象、class对象、实例对象。但是class对象也可以称之为实例对象,因为它是type生成的,那么自然就是type的一个实例对象,但是它同时也能生成实例,因此又叫做class对象。但是一般我们就认为实例对象就只是除了type之外的类生成的实例对象
因此现在我们可以总结一下:
在python中,任何一个对象都有一个类型,可以通过对象的__class__属性获取,也可以通过type函数去查看。任何一个实例对象的类型都是一个类对象,而类对象的类型则是<class \'type\'>。而在python底层,它实际上对应的就是PyType_Type在python中,任何一个类对象都与<class \'object\'>之间存在is-kind-of关系,包括<class \'type\'>。在python内部,<class \'object\'>对应的类型是PyBaseObject_Type
13.2 深入♂class
我们知道python里面有很多以双下划线开头、双下划线结尾的方法,我们称之为魔法方法。python中的每一个对象所能进行操作,那么在生成该对象的对象中一定会定义相应的魔法方法。比如整型3,整型可以相加,这就代表int这个类里面肯定定义了__add__方法
class MyInt(int):
def __add__(self, other):
return int.__add__(self, other) * 3
a = MyInt(1)
b = MyInt(2)
print(a + b) # 9
我们自己实现了一个类,继承自int,那么肯定可以接收一个整型。当我执行a+b的时候,肯定执行对应的__add__方法,然后调用int的__add__方法,得到结果之后再乘上3,逻辑上没有问题。但是问题来了,首先调用int.__add__的时候,python是怎么相加的呢?而且我们知道int.__add__(self, other)里面的参数显然都应该是int,但是我们传递的是MyInt,那么python虚拟机是怎么寻找的呢?先来看一张草图:
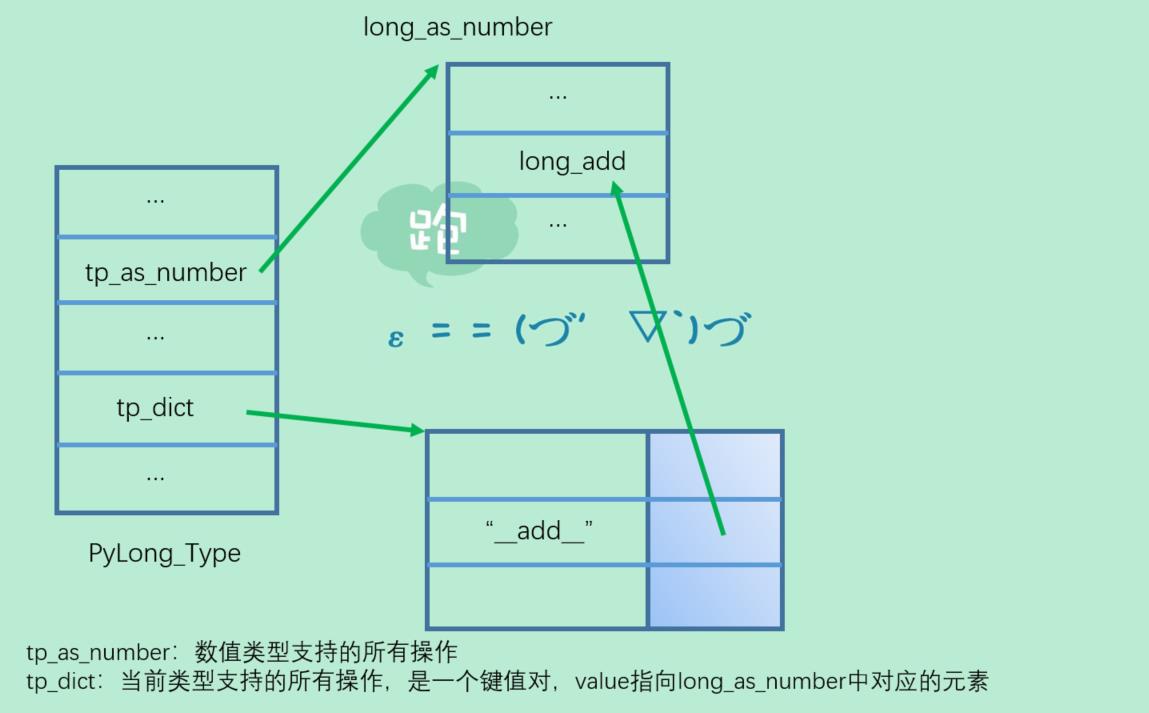
当python虚拟机需要调用int.__add__时,会从对应类型(PyObject里面ob_type域,这是一个PyTypeObject对象)的tp_dict域里面查找符号为__add__的对应的值,通过这个值找到long_as_number中对应的操作,从而完成对int.__add__的调用。
注意:我们上面说通过这个值找到long_as_number中对应的操作,并没有说指向它,对,很明显了,tp_dict中__add__对应的值不是直接指向long_add的,而是它的调用(也就是加上括号)才指向它。虽然是调用,但是并不代表这个值就一定是一个PyFunctionObject,在python中一切都有可能被调用,只要对应的类型对象(比如A加上括括号生成了a,那么就把A称之为a的类型对象,这样秒速会方便一些)定义了__call__方法,即在底层中的ob_type域中定义的tp_call方法不为NULL。
一言以蔽之:在python中,所谓调用,就是执行类型对象对应的ob_type域中定义的tp_call方法
class A:
def __call__(self, *args, **kwargs):
return "我是CALL,我被尻了"
a = A()
print(a()) # 我是CALL,我被尻了
在python内部,实际上是通过一个PyObject_Call的函数对实例对象a进行操作。
def foo():
a = 1
print(a())
# TypeError: \'int\' object is not callable
foo()
我们看到一个整数对象是不可调用的,这显然意味着int这个类里面没有__call__方法,换言之PyLongObject结构体对应的ob_type域里面的tp_call为NULL。
# 但是我们通过反射打印的时候,发现int是有__call__方法的啊
print(hasattr(int, "__call__")) # True
# 其实所有的类都由type生成的,这个__call__不是int里面的,而是type的
print("__call__" in dir(int)) # False
print("__call__" in dir(type)) # True
print(int.__call__) # <method-wrapper \'__call__\' of type object at 0x00007FFAE22C0D10>
# hasattr和类的属性查找一样,如果找不到会自动到对应的类型对象里面去找
# type生成了int,那么如果type里面有__call__的话,即便int里面没有,hasattr(int, "__call__")依旧是True
a1 = int("123")
a2 = int.__call__("123")
a3 = type.__call__(int, "123")
# 以上三者的本质是一样的
print(a1, a2, a3) # 123 123 123
# 之前说过,当一个对象加上括号的时候,本质上调用其类型对象里面的__call__方法
# a = 3
# 那么a()就相当于调用int里面的__call__方法,但是int里面没有,就直接报错了
# 可能这里就有人问了,难道不会到type里面找吗?答案是不会的,因为type是元类,是用来生成类的
# 如果还能到type里面找,那么调用type的__call__生成的结果到底算什么呢?是类对象?可它又明明是实例对象加上括号调用的。显然这样就乱套了
# 因此实例对象找不到,会到类对象里面找,如果类对象再找不到,就不会再去元类里面找了,而是会去父类里面找
class A:
def __call__(self, *args, **kwargs):
print(self)
return "我被尻了"
class B(A):
pass
class C(B):
pass
print(C()())
"""
<__main__.C object at 0x000002282F3D9B80>
我被尻了
"""
# 此时我们看到,给C的实例对象加括号的时候,C里面没有__call__方法,这个时候是不会到元类里面找的
# 还是之前的结论,实例对象找不到属性,会去类对象里面找,然而即便此时类对象里面也没有,也不会到元类type里面找,这时候就看父类了
# 只有当类对象去找属性找不到的时候,才会去元类里面找,正如上面的__call__方法
# int里面没有,但它的类型对象type里面有,所以会去type里面找。如果type再找不到,肯定报错了
# 我们看对于我们上面的例子,给C的实例对象加括号的时候,会执行C这个类里面的__call__
# 但是它没有,所以找不到。然而它继承的父类里面有__call__
# 因此会执行继承的父类的__call__方法,并且里面的self还是C的实例对象
看,一个整数对象是不可调用的,但是我们发现这并不是在编译的时候就能够检测出来的错误,而是在运行时才能检测出来、会在运行时通过函数PyObject_CallFunctionObjArgs确定。所以a = 1;a()明明会报错,但是python还是成功编译了。
为什么会是这样呢?我们知道一个对象对应的类型都会有tp_dict这个域,这个域指向一个PyDictObject,表示这个对象支持哪些操作,而这个PyDictObject对象必须要在运行时动态构建。所以都说python效率慢,一个原因是所有对象都分配在堆上,还有一个原因就是一个对象很多属性或者操作、甚至是该对象是什么类型都需要在运行时动态构建,从而也就造成了python运行时效率不高。
而且我们发现,像int、str、dict等内建对象可以直接使用。这是因为python在启动时,会对这些内建对象进行初始化的动作。这个初始化的动作会动态地在这些内建对象对应的PyTypeObject中填充一些重要的东西,其中当然也包括填充tp_dict,从而让这些内建对象具备生成实例对象的能力。这个对内建对象进行初始化的动作就从函数PyType_Ready拉开序幕。
python通过调用函数PyType_Ready对内建对象进行初始化。实际上,PyType_Ready不仅仅是处理内建对象,还会处理class对象,并且PyType_Ready对于内建对象和class对象的作用还不同。比如说:list和class A:,list就已经作为PyList_Type(PyTypeObject)在python中存在了,咦,PyList_Type是个啥,和PyListObject有关系吗?估计到这里可能有人已经懵了,或者说前面章节介绍的已经忘记了。以python中的list为例:
PyListObject:对应python中的list实例对象,一个list()就是一个PyListObject结构体实例PyList_Type:就是python中list这个类本身,它被PyListObject中的ob_type域指向
PyListObject支持哪些操作,都会通过ob_type到PyList_Type里面去找。
言归正传,我们刚才说,在python解释器启动的时候,PyList_Type就已经存在了,并且是全局对象,仅仅再需要小小的完善一下。但是对于自定的class对象A来说(为了解释方便,假设在底层就叫做PyA_Type吧,当然我们只是假设这么对应的,至于到底是什么我们后面会说,但是目前为了解释方便就这么叫吧),底层对应的PyA_Type则并不存在,需要申请内存、创建、初始化整个动作序列。所以对于list来说,初始化就只剩下PyType_Ready了(也就上面说的小小的完善一下),但是对于自定义的class对象A来说,PyType_Ready仅仅是很小的一部分。
下面我们就以python中的type对象入手,因为它比较特殊。python中的type在底层对应PyType_Type。我们说python中type生成了int、str、dict等内建对象,但是type、object也是内建对象,当然这两个老铁的类型也依旧是type。但是在底层,这个所有的内建类型都是一个PyTypeObject对象。
int: PyLong_Typestr: PyUnicode_Typetuple: PyTuple_Typedict: PyDict_Typetype: PyType_Type
从名字也能看出来规律,这些内建对象在cpython、也就是python底层中,都是一个PyTypeObject对象、或者说一个PyTypeObject结构体实例。尽管在python中说type生成了所有的类对象(所有内建对象+class对象),但是在cpython中它们都是同一个类型、也就是同一个结构体(各个域的值不同)的不同实例。
13.2.1 处理基类和type信息
//typeobject.c
int
PyType_Ready(PyTypeObject *type)
{
//这里的参数显然是PyType_Type
//tp_dict,和继承的基类,因为是多个所以是bases,当然不用想这些基类也都是PyTypeObject对象
PyObject *dict, *bases;
//还是继承的基类,显然这个是object,对应PyBaseObject_Type,因为py3中,所有的类都是默认继承的
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_base (defaults to BaseObject unless that\'s us) */
// 获取type中tp_base域指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
//设置
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
/* Initialize the base class */
//如果基类没有tp_dict,那么会初始化基类
if (base != NULL && base->tp_dict == NULL) {
if (PyType_Ready(base) < 0)
goto error;
}
//设置type信息
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);
}
python虚拟机会尝试获取待初始化的type(PyType_Ready的参数名,这里是PyType_Type)的基类,这个信息是在PyTypeObject.tp_base中指定的,可以看看一些常见内建对象的tp_base信息。

对于指定了tb_base的内建对象,当然就使用指定的基类,而对于没有指定tp_base的内置class对象,python将为其指定一个默认的基类:PyBaseObject_Type,当然这个东西就是python中的object。现在我们看到PyType_Type的tp_base指向了PyBaseObject_Type,这在python中体现的就是type继承自object、或者说object是type的父类。但是所有的类底层对应的结构体的ob_type域又都指向了PyType_Type,包括object,因此我们又说type生成了包括object的所有类。
在获得了基类之后,就会判断基类是否被初始化,如果没有,则需要先对基类进行初始化。可以看到, 判断初始化是否完成的条件是base->tp_dict是否为NULL,这符合之前的描述,对于内建对象的初始化来说,在python解释器启动的时候,就已经作为全局对象存在了,剩下的就是小小的完善一下,也就是对tp_dict进行填充。
然后设置ob_type信息,实际上这个ob_type就是__class__返回的信息。首先PyType_Ready函数里面接收的是一个PyTypeObject,我们知道这个在python中就是python的类对象。因此这里是设置这些类对象的ob_type,那么对应的ob_type显然就是元类metaclass,我们自然会想象到python中的type。但是我们发现Py_TYPE(type) = Py_TYPE(base);这一行代码是把父类的ob_type设置成了当前类的ob_type,也就是说A类是由XX生成的,那么B在继承A的时候,B也会由XX生成。这里之所以用XX代替,是因为python中不仅仅是type可以生成类对象,那些继承了type的子类也可以。
# 必须要继承自type,否则无法作为一个类的metaclass
class MyType(type):
def __new__(mcs, name, bases, attrs):
# 控制类的实例化过程
# 自动添加一个属性
attrs.update({"哈哈": "蛤蛤"})
return super().__new__(mcs, name, bases, attrs)
# 指定A的metaclass是MyType
class A(metaclass=MyType):
pass
# 然后让B去继承A
# 因为A是由MyType生成的,那么B继承A之后,B的元类也会是MyType
class B(A):
pass
print(B.__class__) # <class \'__main__.MyType\'>
print(B.哈哈) # 蛤蛤
所以大家应该明白下面的代码是做什么的了,python虚拟机就是将基类的metaclass设置到了子类的metaclass里面,对于我们当前的PyType_Type来说,其metaclass就是object的metaclass,只不过还是它自己,而在源码的PyBaseObject_Type中可以看到其ob_type是被设置成了PyType_Type的。如果经常使用元类的话,那么上面这个例子很容易明白。
//设置type信息
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);
既然继承了PyBaseObject_Type,那么便会首先初始化PyBaseObject_Type,我们下面来看看这个PyBaseObject_Type、python中的object是怎么被初始化的。
13.2.2 处理基类列表
接下来,python虚拟机会处理类型的基类列表,因为python支持多重继承,所以每一个python的类对象都会有一个基类、或者说父类列表。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_base (defaults to BaseObject unless that\'s us) */
//获取tp_base中指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
...
...
...
/* Initialize tp_bases */
//处理bases:基类列表
bases = type->tp_bases;
//如果bases为空
if (bases == NULL) {
//如果base也为空,说明这个对象一定是PyBaseObject_Type
//因为python中任何类都继承自object,除了object自身
if (base == NULL)
//那么这时候bases就是个空元组,元素个数为0
bases = PyTuple_New(0);
else
//否则的话,就申请只有一个空间的元素,然后将base(PyBaseObject_Type)塞进去
bases = PyTuple_Pack(1, base);
if (bases == NULL)
goto error;
//设置bases
type->tp_bases = bases;
}
}
因此我们看到有两个属性,一个是tp_base,一个是tp_bases,我们看看这俩在python中的区别。
class A:
pass
class B(A):
pass
class C:
pass
class D(B, C):
pass
print(D.__base__) # <class \'__main__.B\'>
print(D.__bases__) # (<class \'__main__.B\'>, <class \'__main__.C\'>)
print(C.__base__) # <class \'object\'>
print(C.__bases__) # (<class \'object\'>,)
print(B.__base__) # <class \'__main__.A\'>
print(B.__bases__) # (<class \'__main__.A\'>,)
我们看到D同时继承多个类,那么tp_base就是先出现的那个基类,而tp_bases则是继承的所有基类,但是基类的基类是不会出现的,比如object。对于class B也是一样的。然后我们看看class C,因为C没有显式地继承任何类,那么tp_bases就是NULL,但是python3中所有的类都默认继承了object,所以tp_base就是PyBaseObject_Type,那么就会把tp_base拷贝到tp_bases里面,因此也就出现了这个结果。
print(C.__base__) # <class \'object\'>
print(C.__bases__) # (<class \'object\'>,)
13.2.3 填充tp_dict
下面python虚拟机就进入了激动人心的tp_dict的填充阶段,这是一个极其繁复的过程。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_dict */
//初始化tp_dict
dict = type->tp_dict;
if (dict == NULL) {
dict = PyDict_New();
if (dict == NULL)
goto error;
type->tp_dict = dict;
}
/* Add type-specific descriptors to tp_dict */
//将与type相关的操作加入到tp_dict中
if (add_operators(type) < 0)
goto error;
if (type->tp_methods != NULL) {
if (add_methods(type, type->tp_methods) < 0)
goto error;
}
if (type->tp_members != NULL) {
if (add_members(type, type->tp_members) < 0)
goto error;
}
if (type->tp_getset != NULL) {
if (add_getset(type, type->tp_getset) < 0)
goto error;
}
}
在这个截断,完成了将("__add__", &long_add)加入tp_dict的过程,这个阶段的add_operators、add_methods、add_members、add_getset都是完成这样的填充tp_dict的动作。那么这时候一个问题就出现了,python是如何知道__add__和long_add之间存在关联的呢?其实这种关联显然是一开始就已经定好了的,而且存放在一个名为slotdefs的数组中。
13.2.3.1 slot与操作排序
在进入填充tp_dict的复杂操作之前,我们先来看一下python中的一个概念:slot。在python内部,slot可以视为表示PyTypeObject中定义的操作,一个操作对应一个slot,但是slot又不仅仅包含一个函数指针,它还包含一些其它信息,我们看看它的结构。在python内部,slot是通过slotdef这个结构体来实现的。
//typeobject.c
typedef struct wrapperbase slotdef;
//descrobject.h
struct wrapperbase {
const char *name;
int offset;
void *function;
wrapperfunc wrapper;
const char *doc;
int flags;
PyObject *name_strobj;
};
在一个slot中,就存储着PyTypeObject中一种操作对应的各种信息,比如:int实例对象(PyLongObject)支持哪些操作,就看int(PyTypeObject实例PyLong_Type)支持哪些操作,而PyTypeObject中的一个操作就会有一个slot与之对应。比如slot里面的name就是操作对应的名称,比如字符串__add__,offset则是操作的函数地址在PyHeapTypeObject中的偏移量,而function则指向一种称为slot function的函数
python中提供了多个宏来定义一个slot,其中最基本是TPSLOT和ETSLOT
//typeobject.c
#define TPSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \\
{NAME, offsetof(PyTypeObject, SLOT), (void *)(FUNCTION), WRAPPER, \\
PyDoc_STR(DOC)}
#define ETSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \\
{NAME, offsetof(PyHeapTypeObject, SLOT), (void *)(FUNCTION), WRAPPER, \\
PyDoc_STR(DOC)}
TPSLOT和ETSLOT的区别就在于TPSLOT计算的是操作对应的函数指针(比如nb_add)在PyTypeObject中的偏移量,而ETSLOT计算的是函数指针在PyHeapTypeObject中的偏移量,但是我们看一下,PyHeapTypeObject的定义,就能发现端倪
typedef struct _heaptypeobject {
/* Note: there\'s a dependency on the order of these members
in slotptr() in typeobject.c . */
PyTypeObject ht_type;
PyAsyncMethods as_async;
PyNumberMethods as_number;
PyMappingMethods as_mapping;
PySequenceMethods as_sequence; /* as_sequence comes after as_mapping,
so that the mapping wins when both
the mapping and the sequence define
a given operator (e.g. __getitem__).
see add_operators() in typeobject.c . */
PyBufferProcs as_buffer;
PyObject *ht_name, *ht_slots, *ht_qualname;
struct _dictkeysobject *ht_cached_keys;
/* here are optional user slots, followed by the members. */
} PyHeapTypeObject;
我们发现PyHeapTypeObject的第一个域就是PyTypeObject,因此可以发现TPSLOT计算出的也是PyHeapTypeObject的偏移量。
对于一个PyTypeObject来说,有的操作,比如long_add,其函数指针是在PyNumberMethods里面存放的,而PyTypeObject中却是通过一个tp_as_number指针指向另一个PyNumberMethods结构,因此这种情况是没办法计算出long_add在PyTypeObject中的偏移量的,只能计算出在PyHeapTypeObject中的偏移量。这种时候TPSLOT就失效了
因此与long_add对应的slot必须是通过ETSLOT来定义的,但是我们说PyHeapTypeObject里面的offset表示的是基于PyHeapTypeObject得到的偏移量,而PyLong_Type却是一个PyTypeObject,那么通过这个偏移量显然无法得到PyLong_Type中为int准备的long_add,那~~~这个offset有什么用呢?
答案非常诡异,这个offset是用来对操作进行排序的。排序?整个人都不好了不过在理解为什么需要对操作进行排序之前,需要先看看python预先定义的slot集合--slotdefs
//typeobject.c
#define SQSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC) \\
ETSLOT(NAME, as_sequence.SLOT, FUNCTION, WRAPPER, DOC)
static slotdef slotdefs[] = {
//不同操作名(__add__、__radd__)对象,对应相同操作nb_add
//这个nb_add在PyLong_Type就是long_add,表示+
BINSLOT("__add__", nb_add, slot_nb_add,
"+"),
RBINSLOT("__radd__", nb_add, slot_nb_add,
"+"),
BINSLOT("__sub__", nb_subtract, slot_nb_subtract,
"-"),
RBINSLOT("__rsub__", nb_subtract, slot_nb_subtract,
"-"),
BINSLOT("__mul__", nb_multiply, slot_nb_multiply,
"*"),
RBINSLOT("__rmul__", nb_multiply, slot_nb_multiply,
"*"),
//相同操作名(__getitem__)对应不同操作(mp_subscript、mp_ass_subscript)
MPSLOT("__getitem__", mp_subscript, slot_mp_subscript,
wrap_binaryfunc,
"__getitem__($self, key, /)\\n--\\n\\nReturn self[key]."),
SQSLOT("__getitem__", sq_item, slot_sq_item, wrap_sq_item,
"__getitem__($self, key, /)\\n--\\n\\nReturn self[key]."),
};
其中BINSLOT,SQSLOT等这些宏实际上都是对ETSLOT的一个简单包装,并且在slotdefs中,可以发现,操作名(比如__add__)和操作并不是一一对应的,存在多个操作对应同一个操作名、或者多个操作名对应同一个操作的情况,那么在填充tp_dict时,就会出现问题,比如对于__getitem__,在tp_dict中与其对应的是mp_subscript还是sq_item呢?
为了解决这个问题,就需要利用slot中的offset信息对slot(也就是对操作)进行排序。回顾一下前面列出的PyHeapTypeObject的代码,它与一般的struct定义不同牟其中定义中各个域的顺序是非常关键的,在顺序中隐含着操作优先级的问题。比如在PyHeapTypeObject中,PyMappingMethods的位置在PySequenceMethods之前,mp_subscript是PyMappingMethods中的一个域:PyObject *,而sq_item又是PySequenceMethods中的的一个域:PyObject *,那么最终计算出的偏移量就存在如下关系:offset(mp_subscript) < offset(sq_item)。因此如果在一个PyTypeObject中,既定义了mp_subscript,又定义了sq_item,那么python虚拟机将选择mp_subscript与__getitem__发生关系。
而对slotdefs的排序在init_slotdefs中完成:
//typeobject.c
static int slotdefs_initialized = 0;
/* Initialize the slotdefs table by adding interned string objects for the
names. */
static void
init_slotdefs(void)
{
slotdef *p;
//init_slotdefs只会进行一次
if (slotdefs_initialized)
return;
for (p = slotdefs; p->name; p++) {
/* Slots must be ordered by their offset in the PyHeapTypeObject. */
//注释也表名:slots一定要通过它们在PyHeapTypeObject中的offset进行排序
//而且是从小到大排
assert(!p[1].name || p->offset <= p[1].offset);
//填充slotdef结构体中的name_strobj
p->name_strobj = PyUnicode_InternFromString(p->name);
if (!p->name_strobj || !PyUnicode_CHECK_INTERNED(p->name_strobj))
Py_FatalError("Out of memory interning slotdef names");
}
//将值赋为1,这样的话下次执行的时候,执行到上面的if就直接return了
slotdefs_initialized = 1;
}
13.2.3.2 从slot到descriptor
在slot中,包含了很多关于一个操作的信息,但是很可惜,在tp_dict中,与__getitem__关联在一起的,一定不会是slot。因为它不是一个PyObject,无法放在dict对象中。当然如果再深入思考一下,会发现slot也无法被调用。既然slot不是一个PyObject,那么它就没有ob_type这个域,也就无从谈起什么tp_call了,所以slot是无论如也无法满足python中的可调用这一条件的。前面我们说过,python虚拟机在tp_dict找到__getitem__对应的操作后,会调用该操作,所以tp_dict中与__getitem__对应的只能是包装了slot的PyObject。在python中,我们称之为descriptor。
在python内部,存在多种descriptor,与descriptor相对应的是PyWrapperDescrObject。在后面的描述中也会直接使用descriptor代表PyWrapperDescrObject。一个descriptor包含一个slot,其创建是通过PyDescr_NewWrapper完成的
//descrobject.h
#define PyDescr_COMMON PyDescrObject d_common
typedef struct {
PyObject_HEAD
PyTypeObject *d_type;
PyObject *d_name;
PyObject *d_qualname;
} PyDescrObject;
typedef struct {
PyDescr_COMMON;
struct wrapperbase *d_base;
void *d_wrapped; /* This can be any function pointer */
} PyWrapperDescrObject;
//descrobject.c
static PyDescrObject *
descr_new(PyTypeObject *descrtype, PyTypeObject *type, const char *name)
{
PyDescrObject *descr;
//申请空间
descr = (PyDescrObject *)PyType_GenericAlloc(descrtype, 0);
if (descr != NULL) {
Py_XINCREF(type);
descr->d_type = type;
descr->d_name = PyUnicode_InternFromString(name);
if (descr->d_name == NULL) {
Py_DECREF(descr);
descr = NULL;
}
else {
descr->d_qualname = NULL;
}
}
return descr;
}
PyObject *
PyDescr_NewWrapper(PyTypeObject *type, struct wrapperbase *base, void *wrapped)
{
PyWrapperDescrObject *descr;
descr = (PyWrapperDescrObject *)descr_new(&PyWrapperDescr_Type,
type, base->name);
if (descr != NULL) {
descr->d_base = base;
descr->d_wrapped = wrapped;
}
return (PyObject *)descr;
}
python内部的各种descriptor都将包含PyDescr_COMMON,其中的d_type被设置为PyDescr_NewWrapper的参数type,而d_wrapped则存放着最重要的信息:操作对应的函数指针,比如对于PyList_Type来说,其tp_dict["__getitem__"].d_wrapped就是&mp_subscript。而slot则被存放在了d_base中。
PyWrapperDescrObject的type是PyWrapperDescr_Type,其中的tp_call是wrapperdescr_call,当python虚拟机调用一个descriptor时,也就会调用wrapperdescr_call。对于descriptor的调用过程,我们将在后面详细介绍。
13.2.3.3 建立联系
排序后的结果仍然存放在slotdefs中,python虚拟机这下就可以从头到尾遍历slotdefs,基于每一个slot建立一个descriptor,然后在tp_dict中建立从操作名到descriptor的关联,这个过程是在add_operators中完成的。
//typeobject.c
static int
add_operators(PyTypeObject *type)
{
PyObject *dict = type->tp_dict;
slotdef *p;
PyObject *descr;
void **ptr;
//对slotdefs进行排序
init_slotdefs();
for (p = slotdefs; p->name; p++) {
//如果slot中没有指定wrapper,则无需处理
if (p->wrapper == NULL)
continue;
//获得slot对应的操作在PyTypeObject中的函数指针
ptr = slotptr(type, p->offset);
if (!ptr || !*ptr)
continue;
//如果tp_dict中已经存在操作名,则放弃
if (PyDict_GetItem(dict, p->name_strobj))
continue;
if (*ptr == (void *)PyObject_HashNotImplemented) {
/* Classes may prevent the inheritance of the tp_hash
slot by storing PyObject_HashNotImplemented in it. Make it
visible as a None value for the __hash__ attribute. */
if (PyDict_SetItem(dict, p->name_strobj, Py_None) < 0)
return -1;
}
else {
//创建descriptor
descr = PyDescr_NewWrapper(type, p, *ptr);
if (descr == NULL)
return -1;
//将(操作名,descriptor)放入tp_dict中
if (PyDict_SetItem(dict, p->name_strobj, descr) < 0) {
Py_DECREF(descr);
return -1;
}
Py_DECREF(descr);
}
}
if (type->tp_new != NULL) {
if (add_tp_new_wrapper(type) < 0)
return -1;
}
return 0;
}
在add_operators中,首先调用前面剖析过的init_slotdefs对操作进行排序,然后遍历排序完成后的slotdefs结构体数组,对其中的每一个slot(slotdef),通过slotptr获得该slot对应的操作在PyTypeObject中的函数指针,并接着创建descriptor,在tp_dict中建立从操作名(slotdef.name_strobj)到操作(descriptor)的关联。
但是需要注意的是,在创建descriptor之前,python虚拟机会检查在tp_dict中操作名是否存在,如果存在了,则不会再次建立从操作名到操作的关联。不过也正是这种检查机制与排序机制相结合,python虚拟机在能在拥有相同操作名的多个操作中选择优先级最高的操作。
在add_operators中,上面的动作都很简单、直观,而最难的动作隐藏在slotptr这个函数当中。它的功能是完成从slot到slot对应操作的真实函数指针的转换。我们知道,在slot中存放着用来操作的offset,但不幸的是,这个offset是相对于PyHeapTypeObject的偏移,而操作的真实函数指针却是在PyTypeObject中指定的,而且PyTypeObject和PyHeapTypeObject不是同构的,因为PyHeapTypeObject中包含了PyNumberMethods结构体,但PyTypeObject只包含了PyNumberMethods *指针。所以slot中存储的关于操作的offset对PyTypeObject来说,不能直接用,必须通过转换。
举个栗子,假如说调用slotptr(&PyList_Type, offset(PyHeapTypeObject, mp_subscript)),首先判断这个偏移量大于offset(PyHeapTypeObject, as_mapping),所以会先从PyTypeObject对象中获得as_mapping指针p,然后在p的基础上进行偏移就可以得到实际的函数地址,所以偏移量delta为:
offset(PyHeapTypeObject, mp_subscript) - offset(PyHeapTypeObject, as_mapping)
而这个复杂的过程就在slotptr中完成
static void **
slotptr(PyTypeObject *type, int ioffset)
{
char *ptr;
long offset = ioffset;
/* Note: this depends on the order of the members of PyHeapTypeObject! */
assert(offset >= 0);
assert((size_t)offset < offsetof(PyHeapTypeObject, as_buffer));
//判断从PyHeapTypeObject中排在后面的PySequenceMethods开始,然后向前,依次判断PyMappingMethods和PyNumberMethods呢。
/*
为什么要这么做呢?假设我们首先从PyNumberMethods开始判断,如果一个操作的offset大于在PyHeapTypeObject中,as_numbers在PyNumberMethods的偏移量,那么我们还是没办法确认这个操作到底是属于谁的。只有从后往前进行判断,才能解决这个问题。
*/
if ((size_t)offset >= offsetof(PyHeapTypeObject, as_sequence)) {
ptr = (char *)type->tp_as_sequence;
offset -= offsetof(PyHeapTypeObject, as_sequence);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_mapping)) {
ptr = (char *)type->tp_as_mapping;
offset -= offsetof(PyHeapTypeObject, as_mapping);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_number)) {
ptr = (char *)type->tp_as_number;
offset -= offsetof(PyHeapTypeObject, as_number);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_async)) {
ptr = (char *)type->tp_as_async;
offset -= offsetof(PyHeapTypeObject, as_async);
}
else {
ptr = (char *)type;
}
if (ptr != NULL)
ptr += offset;
return (void **)ptr;
}
好了,我想到现在我们应该能够摸清楚Python在改造PyTypeObject对象时对tp_dict做了什么了,我们以PyList_Type举例说明:
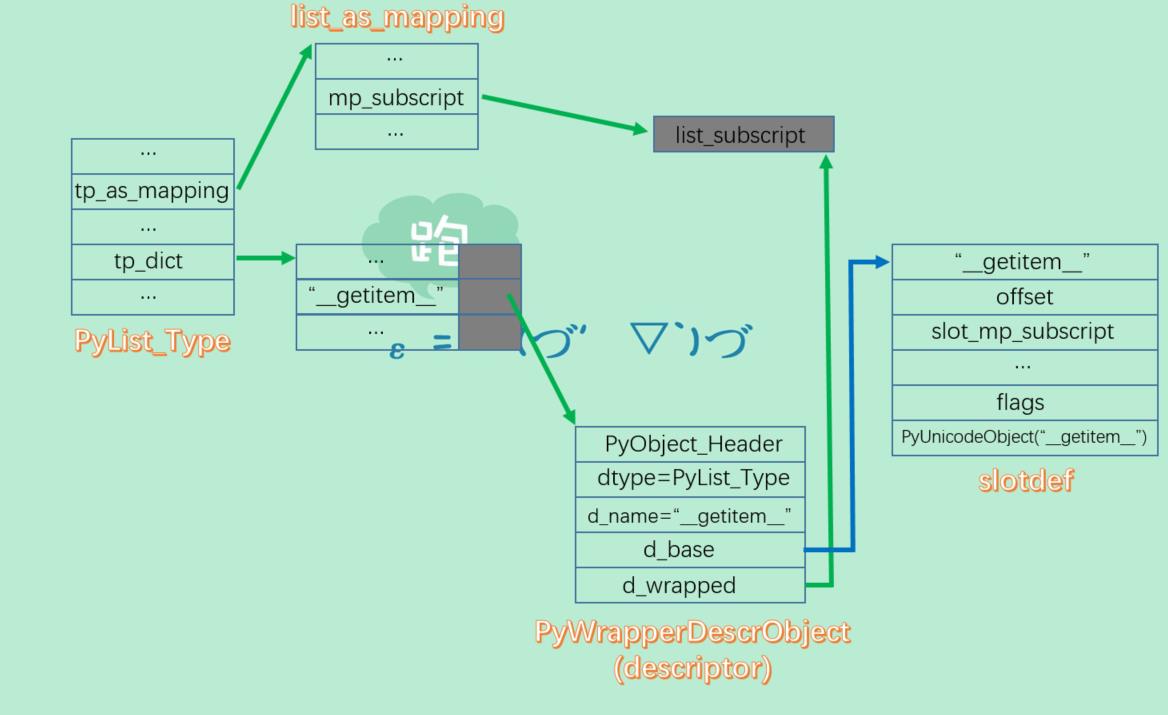
在add_operators完成之后,PyList_Type如图所示。从PyList_Type.tp_as_mapping中延伸出去的部分是在编译时就已经确定好了的,而从tp_dict中延伸出去的部分则是在python运行时环境初始化的时候才建立的。
PyType_Ready在通过add_operators添加了PyTypeObject对象中定义的一些operator后,还会通过add_methods、add_numbers和add_getsets添加在PyTypeObject中定义的tp_methods、tp_members和tp_getset函数集。这些add_xxx的过程和add_operators类似,不过最后添加到tp_dict中descriptor就不再是PyWrapperDescrObject,而分别是PyMethodDescrObject、PyMemberDescrObject、PyGetSetDescrObject。
从目前来看,基本上算是解析完了,但是还有一点:
class A(list):
def __repr__(self):
return "xxx"
a = A()
print(a) # xxx
显然当我们print(a)的时候,应该调用A.tp_repr函数,对照PyList_Type的布局,应该调用list_repr这个函数,然而事实却并非如此,python虚拟机调用的是我们在A中重写的__repr__方法。这意味着python在初始化A的时候,对tp_repr进行了特殊处理。为什么python虚拟机会知道要对tp_repr进行特殊处理呢?当然肯定有人会说:这是因为我们重写了__repr__方法啊,确实如此,但这是python层面上的,在底层的话,答案还是在slot身上。
在slotdefs中,存在:
//typeobject.c
static slotdef slotdefs[] = {
...
TPSLOT("__repr__", tp_repr, slot_tp_repr, wrap_unaryfunc,
"__repr__($self, /)\\n--\\n\\nReturn repr(self)."),
...
}
python虚拟机在初始化A时,会检查A的tp_dict中是否存在__repr__,在后面剖析自定义class对象的创建时会看到,因为在定义class A的时候,重写了__repr__这个操作,所以在A.tp_dict中,__repr__一开始就会存在,python虚拟机会检测到,然后会根据__repr__对应的slot顺藤摸瓜,找到tp_repr,并且将这个函数指针替换为slot中指定的&slot_tp_repr。所以当后来虚拟机找A.tp_repr的时候,实际上找的是slot_tp_repr。
//typeobject.c
static PyObject *
slot_tp_repr(PyObject *self)
{
PyObject *func, *res;
_Py_IDENTIFIER(__repr__);
int unbound;
//查找__repr__属性
func = lookup_maybe_method(self, &PyId___repr__, &unbound);
if (func != NULL) {
//调用__repr__对应的对象
res = call_unbound_noarg(unbound, func, self);
Py_DECREF(func);
return res;
}
PyErr_Clear();
return PyUnicode_FromFormat("<%s object at %p>",
Py_TYPE(self)->tp_name, self);
}
在slot_tp_repr中,会寻找__repr__属性对应的对象,正好就会找到在A中重写的函数,后面会看到,这个对象实际上就一个PyFunctionObject对象。这样一来,就完成了对默认的list的repr行为的替换。所以对于A来说,内存布局就是下面这样。
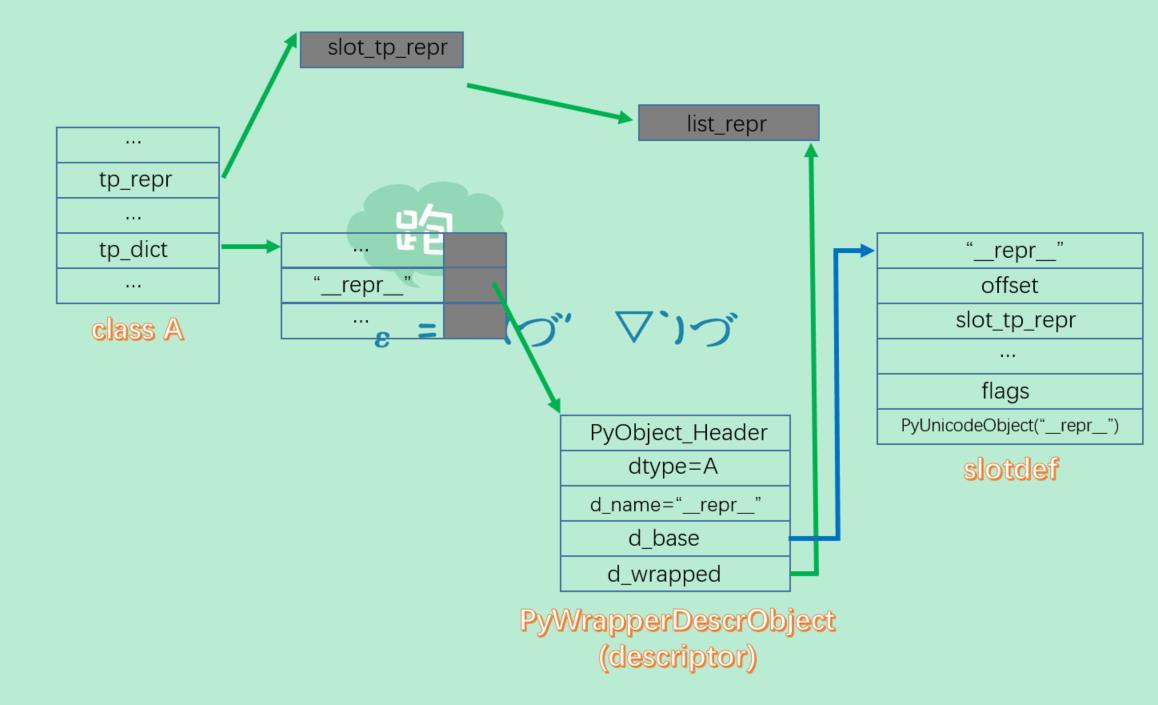
当然这仅仅是针对于__repr__,对于其他的操作还是会指向PyList_Type中指定的函数,比如tp_iter还是会指向list_iter
对于A来说,这个变化是在fixup_slot_dispatchers这个函数中完成的,对于内建对象则不会进行此操作。
static void
fixup_slot_dispatchers(PyTypeObject *type)
{
slotdef *p;
init_slotdefs();
for (p = slotdefs; p->name; )
//遍历、更新slot
p = update_one_slot(type, p);
}
13.2.3.4 确定MRO
MRO,即method resolve order,说白了就是类继承之后、属性或方法的查找顺序。如果python是单继承的话,那么这就不是问题了,但是python是支持多继承的,那么在多继承时,继承的顺序就成为了一个必须考虑的问题。
class A:
def foo(self):
print("A")
class B(A):
def foo(self):
print("B")
class C(A):
def foo(self):
print("C")
self.bar()
def bar(self):
print("bar C")
class D(C, B):
def bar(self):
print("bar D")
d = D()
d.foo()
"""
C
bar D
"""
首先我们看到,打印的是C,说明调用的是C的foo函数,这说明把C写在前面,会调用C的方法,但是下面打印了bar D,这是因为C里面的self,实际上是D的实例对象。D在找不到foo函数的时候,会到父类里面找,但是同时也会将self传递过去,所以调用self.bar的时候,会到D里面找,如果找不到再去父类里面找。
在底层则是先在PyType_Ready中通过mro_internal确定mro的顺序,python虚拟机将创建一个tuple对象,里面存放一组类对象,这些对象的顺序就是虚拟机确定的mro的顺序,最终这个tuple会被保存在PyTypeObject.tp_mro中。
由于mro_internal内部的实现机制相当复杂,所以我们将会只从python的代码层面来理解。首先我们说python早期有经典类和新式类两种类,现在则只存在新式类。而经典类的类搜索方式采用的是深度优先,而新式类则是广度优先(当然现在用的是新的算法,具体什么算法后面说,暂时理解为广度优先即可),举个例子:
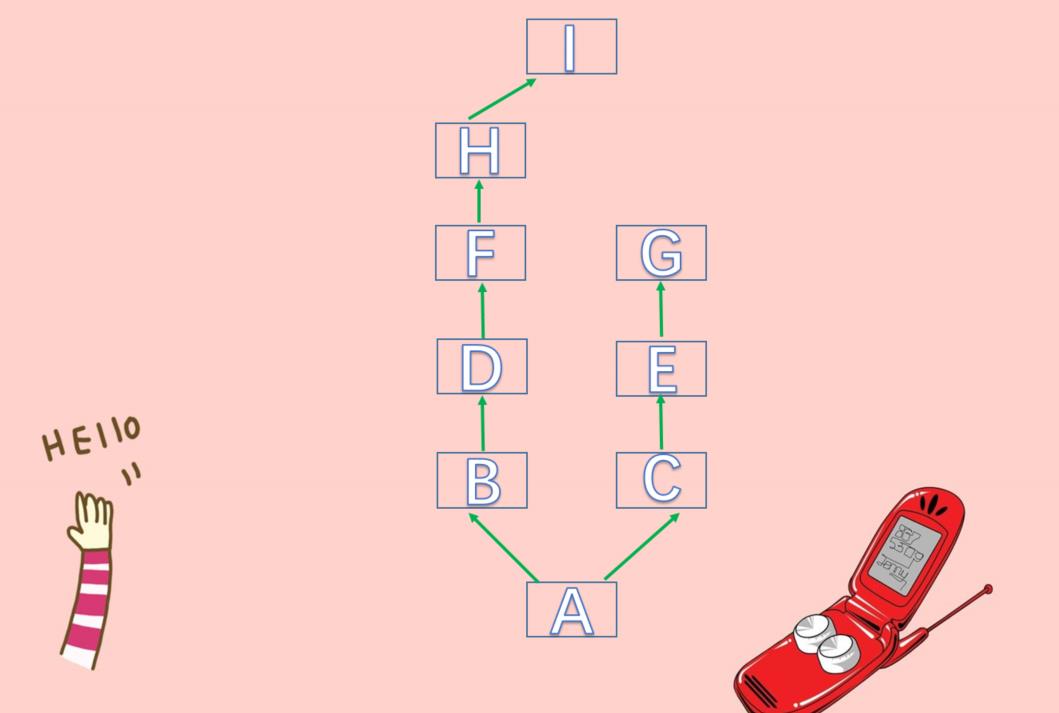
对于上图来说,如果是经典类:显然是属性查找是先从A找到I,再从C找到G。而对于新式类,也是同样的结果,对于上图这种继承结构,至于两边是否一样多则不重要,经典类和新式类是一样的。我们先看结论,我们下面显示的都只是新式类。
# 这里是python3.7 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (), {})
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class \'__main__.A\'>
<class \'__main__.B\'>
<class \'__main__.D\'>
<class \'__main__.F\'>
<class \'__main__.H\'>
<class \'__main__.I\'>
<class \'__main__.C\'>
<class \'__main__.E\'>
<class \'__main__.G\'>
<class \'object\'>
"""
对于A继承两个类,这个两个类分别继续继承,如果最终没有继承公共的类(暂时先忽略object),那么经典类和新式类是一样的,像这种泾渭分明、各自继承各自的,都是先一条路找到黑,然后再去另外一条路去找。
如果是下面这种,最终分久必合、两者最终又继承了同一个类,那么经典类还是跟以前一样,按照每一条路都走到黑的方式。但是对于新式类,则是先从A找到H,而I这个两边最终继承的类不找了,然后从C找到I,也就是在另一条路找到头。
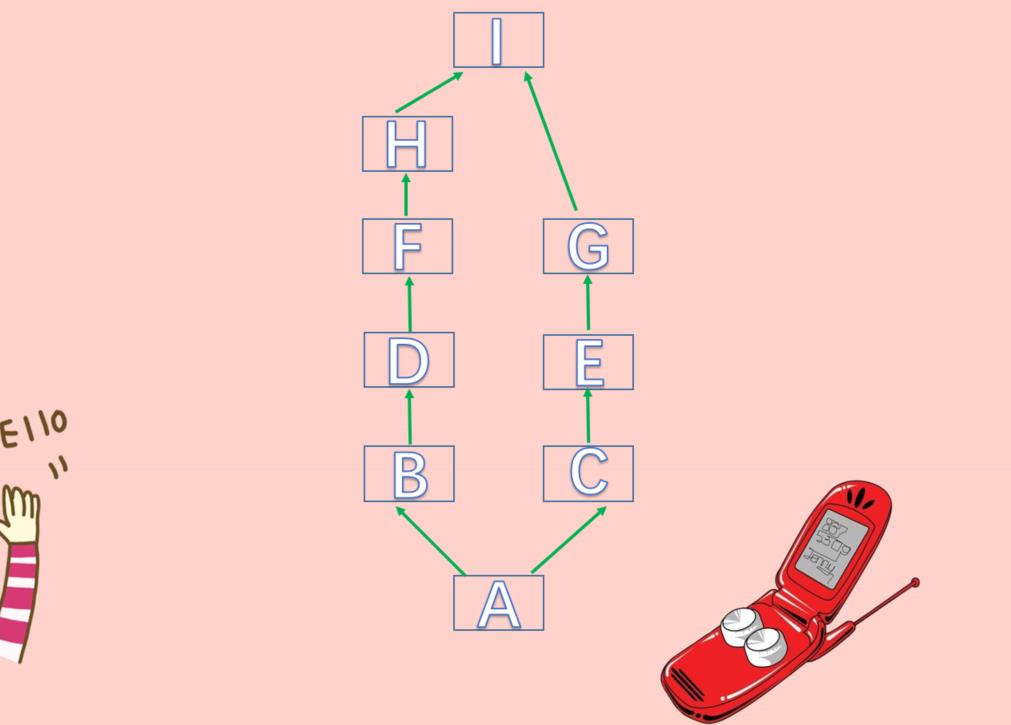
# 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (I,), {}) # 这里让G继承I
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class \'__main__.A\'>
<class \'__main__.B\'>
<class \'__main__.D\'>
<class \'__main__.F\'>
<class \'__main__.H\'>
<class \'__main__.C\'>
<class \'__main__.E\'>
<class \'__main__.G\'>
<class \'__main__.I\'>
<class \'object\'>
"""
因此对于最下面的类继承两个类,然后继承的两个类再次继承的时候,向上只继承一个类,对于这种模式,那么结论、也就是mro顺序就是我们上面分析的那样。不过对新式类来说,因为所有类默认都是继承object,所以第一张图中,即使我们没画完,但是也能想到,两条泾渭分明的继承链的上方最终应该都指向class object。那么我们依旧可以用刚才的理论来解释,在第一条继承链中找到object的前一个类不找了,然后在第二条继承链中一直找到object。
但是python的多继承远比我们想象的要复杂,原因就在于可以任意继承,如果B和C再分别继承两个类呢?那么我们这里的线路就又要多出两条了,不过既然要追求刺激,就贯彻到底喽。但是下面我们就只会介绍新式类了,经典类了解一下就可以了。
另外我们之前说新式类采用的是广度优先,但是实际上这样有一个问题:
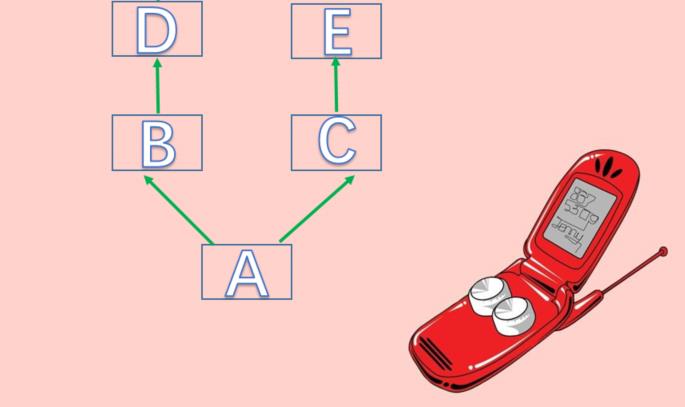
假设我们调用A的foo方法,但是A里面没有,那么理所应当会去B里面找,但是B里面也没有,而C和D里面有,那么这个时候是去C里面找还是去D里面找呢?根据我们之前的结论,显然是去D里面找,可如果按照广度优先的逻辑来说,那么应该是去C里面找啊。所以广度优先理论在这里就不适用了,因为B继承了D,而B和C并没有直接关系,我们应该把B和D看成一个整体。因此python中的广度优先实际上是采用了一种叫做C3的算法。
这个C3算法比较复杂,涉及到拓扑学,如果再去研究拓扑学就本末倒置了。因此,对于python的多继承来说,我只希望记住一句不是很好理解的话:当沿着一条继承链寻找类时,如果这个类出现在了另一条继承链当中,那么当前的继承链的搜索就会结束,然后在"最开始"出现分歧的地方转向下一条继承链的搜索。这是我个人总结的,或许比较难理解,但是通过例子就能明白了。
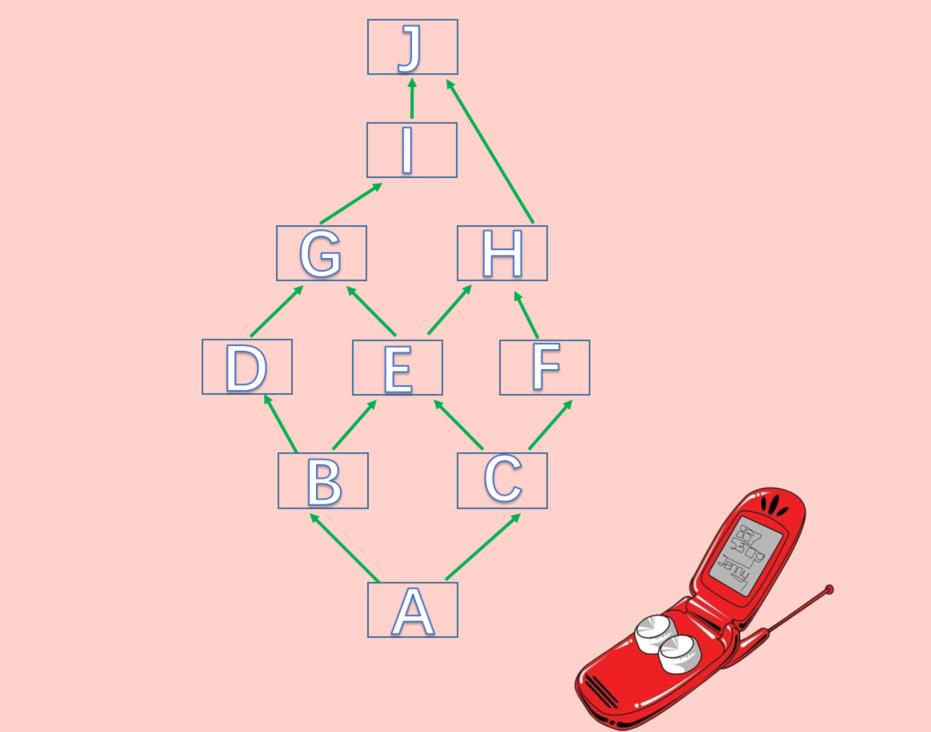
这个箭头表示继承关系,继承顺序是从左到右,比如这里的A就相当于class A(B, C),下面我们来从头到尾分析一下。
首先最开始的顺序是A,如果我们获取A的mro的话然后A继承B和C,由于是两条路,因此我们说A这里就是一个分歧点,但是由于B在前,所以接下来是B。现在mro的顺序是A B但是B这里也出现了分歧点,不过不用管,我们关注的是最开始出现分歧的地方。现在mro的顺序是A B D然后从D开始寻找,这里注意了,按理说会找G的,但是G不止被一个人继承,也就是意味着沿着当前的继承链查找G时,G还出现在了其它的继承链当中。怎么办?显然要回到最初的分歧点,转向下一条继承链的搜索最初的分歧点是A,那么该去找C了,现在mro的顺序就是A B D C注意C这里出现了分歧点,而A的分支已经结束了,所以现在C就是最初的分歧点了。而C继承自E和F,显然要搜索E,那么此时mro的顺序就是A B D C E然后从E开始搜索,显然要搜索G,此时mro顺序是A B D C E G从G要搜索I,注意这里I可没有被H继承哦。此时mro顺序是A B D C E G I从I开始搜索谁呢?J显然出现在了其它的继承链中,那么要回到最初分歧的地方,也就是C,那么下面显然要找F,此时mro顺序是A B D C E G I FF只继承了H,那么肯定要找H,此时mro顺序是 A B D C E G I F HH显然只能找J了,因此最终A的mro顺序就是A B D C E G I F H J object
J = type("J", (object, ), {})
I = type("I", (J, ), {})
H = type("H", (J, ), {})
G = type("G", (I, ), {})
F = type("F", (H, ), {})
E = type("E", (G, H), {})
D = type("D", (G, ), {})
C = type("C", (E, F), {})
B = type("B", (D, E), {})
A = type("A", (B, C), {})
# A B D C E G I F H J
for _ in A.__mro__:
print(_)
"""
<class \'__main__.A\'>
<class \'__main__.B\'>
<class \'__main__.D\'>
<class \'__main__.C\'>
<class \'__main__.E\'>
<class \'__main__.G\'>
<class \'__main__.I\'>
<class \'__main__.F\'>
<class \'__main__.H\'>
<class \'__main__.J\'>
<class \'object\'>
"""
我们再看一个例子
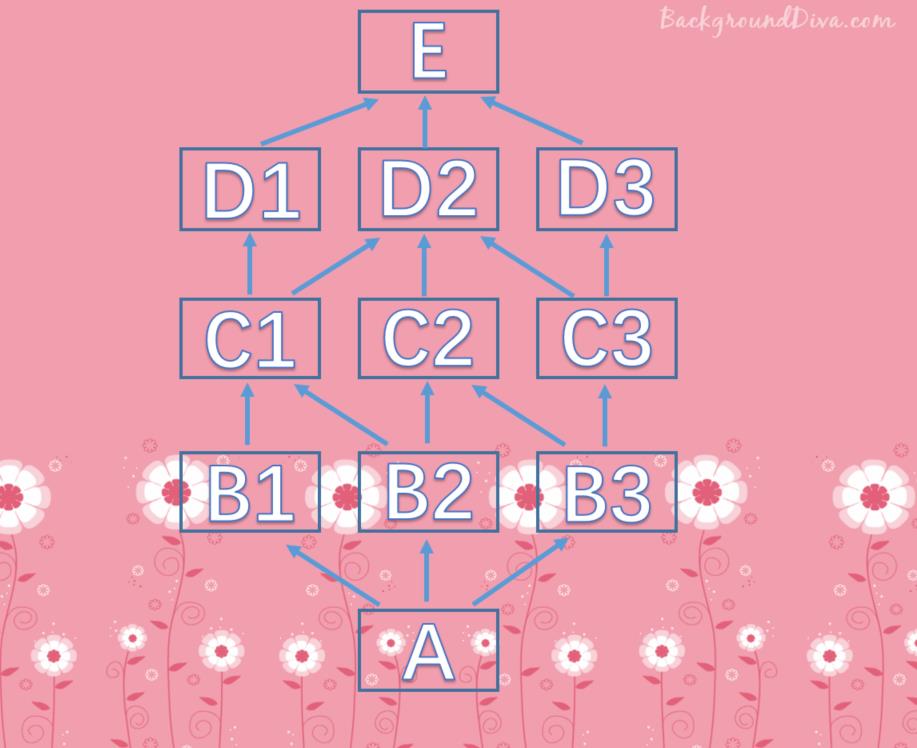
首先是A,A继承B1,B2,B3,会先走B1,此时mro是A B1,注意现在A是分歧点从B1本来该找C1,但是C1还被其他类继承,也就是出现在了其它的继承链当中,因此要回到最初分歧点A,从下一条继承链开始找,显然要找B2,此时mro就是A B1 B2从B2开始,显然要找C1,此时mro顺序就是A B1 B2 C1从C1开始,显然要找D1,因为D1只被C1继承,此时mro顺序是A B1 B2 C1 D1从D1显然不会找E的,咋办,回到最初的分歧点,注意这里显然还是A,因为A的分支还没有走完。显然此时要走B3,那么mro顺序就是A B1 B2 C1 D1 B3从B3开始找,显然要找C2,注意:A的分支已经走完,此时B3就成了新的最初分歧点。现在mro顺序是A B1 B2 C1 D1 B3 C2C2会找D2吗?显然不会,因为它还被C3继承,所以它出现在了其他的继承链中。所以要回到最初分歧点,这里是B3,显然下面要找C3,另外由于B3的分支也已经走完,所以现在C3就成了新的最初分歧点。此时mro顺序是A B1 B2 C1 D1 B3 C2 C3从C3开始,显然要找D2,此时mro顺序是A B1 B2 C1 D1 B3 C2 C3 D2但是D2不会找E,因此回到最初分歧点C3,下面就找D3,然后显然只能再找E了,显然最终mro顺序A B1 B2 C1 D1 B3 C2 C3 D2 D3 E object
E = type("E", (), {})
D1 = type("D1", (E,), {})
D2 = type("D2", (E,), {})
D3 = type("D3", (E,), {})
C1 = type("C1", (D1, D2), {})
C2 = type("C2", (D2,), {})
C3 = type("C3", (D2, D3), {})
B1 = type("B1", (C1,), {})
B2 = type("B2", (C1, C2), {})
B3 = type("B3", (C2, C3), {})
A = type("A", (B1, B2, B3), {})
for _ in A.__mro__:
print(_)
"""
<class \'__main__.A\'>
<class \'__main__.B1\'>
<class \'__main__.B2\'>
<class \'__main__.C1\'>
<class \'__main__.D1\'>
<class \'__main__.B3\'>
<class \'__main__.C2\'>
<class \'__main__.C3\'>
<class \'__main__.D2\'>
<class \'__main__.D3\'>
<class \'__main__.E\'>
<class \'object\'>
"""
底层源码我们就不再看了,个人觉得从目前这个层面来理解已经足够了。
13.2.3.5 继承基类操作
python虚拟机确定了mro顺序列表之后,就会遍历mro列表(第一个类对象会是其自身,比如A.__mro__的第一个元素就是A本身,所以遍历是从第二项开始的)。在mro列表中实际上存储的就是类对象的所有直接基类、间接基类,python虚拟机会将自身没有、但是基类(注意:包括间接基类,比如基类的基类)中存在的操作拷贝到该类当中,从而完成对基类操作的继承动作。
而这个继承操作的动作是发生在inherit_slots中
//typeobject.c
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
...
...
bases = type->tp_mro;
assert(bases != NULL);
assert(PyTuple_Check(bases));
n = PyTuple_GET_SIZE(bases);
for (i = 1; i < n; i++) {
PyObject *b = PyTuple_GET_ITEM(bases, i);
if (PyType_Check(b))
inherit_slots(type, (PyTypeObject *)b);
}
...
...
}
在inherit_slots中会拷贝相当多的操作,这里就拿nb_add(整型则对应long_add)来举个栗子
static void
inherit_slots(PyTypeObject *type, PyTypeObject *base)
{
PyTypeObject *basebase;
#undef SLOTDEFINED
#undef COPYSLOT
#undef COPYNUM
#undef COPYSEQ
#undef COPYMAP
#undef COPYBUF
#define SLOTDEFINED(SLOT) \\
(base->SLOT != 0 && \\
(basebase == NULL || base->SLOT != basebase->SLOT))
#define COPYSLOT(SLOT) \\
if (!type->SLOT && SLOTDEFINED(SLOT)) type->SLOT = base->SLOT
#define COPYASYNC(SLOT) COPYSLOT(tp_as_async->SLOT)
#define COPYNUM(SLOT) COPYSLOT(tp_as_number->SLOT)
#define COPYSEQ(SLOT) COPYSLOT(tp_as_sequence->SLOT)
#define COPYMAP(SLOT) COPYSLOT(tp_as_mapping->SLOT)
#define COPYBUF(SLOT) COPYSLOT(tp_as_buffer->SLOT)
/* This won\'t inherit indirect slots (from tp_as_number etc.)
if type doesn\'t provide the space. */
if (type->tp_as_number != NULL && base->tp_as_number != NULL) {
basebase = base->tp_base;
if (basebase->tp_as_number == NULL)
basebase = NULL;
COPYNUM(nb_add);
COPYNUM(nb_subtract);
COPYNUM(nb_multiply);
COPYNUM(nb_remainder);
COPYNUM(nb_divmod);
COPYNUM(nb_power);
COPYNUM(nb_negative);
COPYNUM(nb_positive);
COPYNUM(nb_absolute);
COPYNUM(nb_bool);
...
...
}
我们在里面看到很多熟悉的东西,如果你常用魔法方法的话。而且我们知道PyBool_Type中并没有设置nb_add,但是PyLong_Type中却设置了nb_add操作,而bool继承int。所以对布尔类型是可以直接进行运算的,当然和整型、浮点型运算也是可以的。所以在numpy中,判断一个数组中多少个满足条件的元素,可以使用numpy提供的机制进行比较,会得到一个同样长度的数组,里面的每一个元素为是否满足条件所对应的布尔值。然后直接通过sum运算即可,因为运算的时候,True会被解释成1,False会被解释成0。
import numpy as np
arr = np.array([2, 4, 7, 3, 5])
print(arr > 4) # [False False True False True]
print(sum(arr > 4)) # 2
print(2.2 + True) # 3.2
所以在python中,整型是可以和布尔类型进行运算的,看似不可思议,但又在情理之中。
不过下面有一个例子,想一想为什么是这个结果
d = {1: "aaa"}
d[True] = "bbb"
print(d) # {1: \'bbb\'}
我们说True在被当成int的时候会被解释成1,而原来的字典里面已经有1这个key了,所以此时True和1是等价的。原来的1还是1,d[True]等价于d[1],所以value被换成了"bbb"
d = {1: "aaa1", False: "bbb1"}
d[True] = "aaa2"
d[0] = "bbb2"
print(d) # {1: \'aaa2\', False: \'bbb2\'}
d[1.0] = "aaa3"
d[0.0] = "bbb3"
print(d) # {1: \'aaa3\', False: \'bbb3\'}
可见,对于字典的存储来说,True、1、1.0三者等价,False、0、0. 以上是关于《python解释器源码剖析》第13章--python虚拟机中的类机制的主要内容,如果未能解决你的问题,请参考以下文章