Python基础.md
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础.md相关的知识,希望对你有一定的参考价值。
数据结构
列表
访问
list1 = [‘java‘,‘C‘,‘C++‘,‘Python‘]
In [10]: list1[1]
Out[10]: ‘C‘
In [11]: list1[-1]
Out[11]: ‘Python‘
修改
In [13]: list1
Out[13]: [‘java‘, ‘C‘, ‘C++‘, ‘Python‘]
In [14]: list1[0]=‘PHP‘
In [15]: list1
Out[15]: [‘PHP‘, ‘C‘, ‘C++‘, ‘Python‘]
追加
In [22]: list1.append(‘java‘)
In [23]: list1
Out[23]: [‘PHP‘, ‘C‘, ‘C++‘, ‘Python‘, ‘java‘]
插入
In [24]: list1.insert(2,‘C#‘)
In [25]: list1
Out[25]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘Python‘, ‘java‘]
In [26]: list1.insert(22222,‘JavaScirpt‘)
In [27]: list1
Out[27]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘Python‘, ‘java‘, ‘JavaScirpt‘]
扩展
In [28]: list1.extend([‘Perl‘,‘Ruby‘])
In [29]: list1
Out[29]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘Python‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘, ‘Ruby‘]
删除
In [30]: list1.pop()
Out[30]: ‘Ruby‘
In [32]: list1
Out[32]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘Python‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘]
In [38]: list1.append(‘Python‘)
In [39]: list1
Out[39]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘Python‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘, ‘Python‘]
In [42]: list1.remove(‘Python‘)
In [43]: list1
Out[43]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘, ‘Python‘]
In [49]: del list1[-1]
In [50]: list1
Out[50]: [‘PHP‘, ‘C‘, ‘C#‘, ‘C++‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘]
In [54]: list.clear()
In [55]: list
Out[55]: []
下标/统计
In [33]: list
Out[33]: [‘PHP‘, ‘Python‘, ‘C‘, ‘C#‘, ‘C++‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘, ‘Python‘]
In [34]: list.index(‘Python‘)
Out[34]: 1
In [35]: list.index(‘Python‘,1)
Out[35]: 1
In [36]: list.index(‘Python‘,2)
Out[36]: 8
In [41]: list.index(‘Python‘,2,10)
Out[41]: 8
In [44]: list.count(‘Python‘)
Out[44]: 2
In [45]: list.count(‘C‘)
Out[45]: 1
In [46]: list.count(‘c‘)
Out[46]: 0
排序
In [49]: list
Out[49]: [‘PHP‘, ‘Python‘, ‘C‘, ‘C#‘, ‘C++‘, ‘java‘, ‘JavaScirpt‘, ‘Perl‘, ‘Python‘]
In [50]: list.sort()
In [51]: list
Out[51]: [‘C‘, ‘C#‘, ‘C++‘, ‘JavaScirpt‘, ‘PHP‘, ‘Perl‘, ‘Python‘, ‘Python‘, ‘java‘]
In [53]: list.sort(reverse=True)
In [54]: list
Out[54]: [‘java‘, ‘Python‘, ‘Python‘, ‘Perl‘, ‘PHP‘, ‘JavaScirpt‘, ‘C++‘, ‘C#‘, ‘C‘]
翻转
In [76]: list
Out[76]: [‘java‘, ‘Python‘, ‘Python‘, ‘Perl‘, ‘PHP‘, ‘JavaScirpt‘, ‘C++‘, ‘C#‘, ‘C‘]
In [77]: list.reverse()
In [78]: list
Out[78]: [‘C‘, ‘C#‘, ‘C++‘, ‘JavaScirpt‘, ‘PHP‘, ‘Perl‘, ‘Python‘, ‘Python‘, ‘java‘]
In [79]: list.reverse()
In [80]: list
Out[80]: [‘java‘, ‘Python‘, ‘Python‘, ‘Perl‘, ‘PHP‘, ‘JavaScirpt‘, ‘C++‘, ‘C#‘, ‘C‘]
复制
In [99]: lst
Out[99]: [4, 5, 2, 4, 5]
In [100]: lst3 = lst.copy()
In [101]: lst3
Out[101]: [4, 5, 2, 4, 5]
切片
In [2]: lst1
Out[2]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [3]: lst1[2:5]
Out[3]: [2, 3, 4]
In [4]: lst1[5:2]
Out[4]: []
In [5]: lst1[-4:-2]
Out[5]: [6, 7]
In [6]: lst1[-2:-4]
Out[6]: []
In [7]: lst1[4:2222]
Out[7]: [4, 5, 6, 7, 8, 9]
In [8]: lst1[-11111:2]
Out[8]: [0, 1]
In [9]: lst1[-11111:222222]
Out[9]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [10]: lst1[-11111:]
Out[10]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [11]: lst1[:22222]
Out[11]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [12]: lst1[:]
Out[12]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [13]: lst1[4:len(lst1)]
Out[13]: [4, 5, 6, 7, 8, 9]
In [15]: lst1[2:10:2]
Out[15]: [2, 4, 6, 8]
In [18]: lst1[-2:-10:-2]
Out[18]: [8, 6, 4, 2]
In [32]: lst1
Out[32]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [33]: lst1[::2]
Out[33]: [0, 2, 4, 6, 8]
In [34]: lst1[::-2]
Out[34]: [9, 7, 5, 3, 1]
In [36]: lst1[2::-2]
Out[36]: [2, 0]
In [37]: lst1[:2:-2]
Out[37]: [9, 7, 5, 3]
元组
访问
In [21]: tup1
Out[21]: (‘C‘, ‘java‘, ‘Python‘)
In [22]: tup1[0]
Out[22]: ‘C‘
In [23]: tup1[-1]
Out[23]: ‘Python‘
查询/统计
In [34]: tup6
Out[34]: (‘C‘, ‘java‘, ‘Python‘, ‘PHP‘, ‘C‘, ‘java‘, ‘Python‘, ‘PHP‘)
In [36]: tup6.index(‘C‘)
Out[36]: 0
In [37]: tup6.index(‘C‘,1)
Out[37]: 4
In [40]: tup6.index(‘C‘,1,5)
Out[40]: 4
In [41]: tup6.count(‘Python‘)
Out[41]: 2
字符串
方法
capitalize
把字符串的第一个字符大写。
In [88]: str2
Out[88]: ‘Defence of the Ancients is DOTA!‘
In [89]: str2.capitalize()
Out[89]: ‘Defence of the ancients is dota!‘
casefole
字符串大写全部变小写。
In [2]: str2 = ‘Defence of the Ancients is DOTA!‘
In [3]: str2.casefold()
Out[3]: ‘defence of the ancients is dota!‘
center
返回一个原字符串居中,并使用空格填充至长度width的新字符串。
In [111]: str2.center(88)
Out[111]: ‘ Defence of the Ancients is DOTA! ‘
In [113]: str2.center(88,‘#‘)
Out[113]: ‘############################Defence of the Ancients is DOTA!############################‘
count
返回str在string里面出现的次数,如果beg或者end指定则在指定的范围查找str出现的次数。
In [110]: str4=‘***** DOTA dota #####‘
In [111]: str4.count(‘*‘)
Out[111]: 5
In [112]: str4.count(‘**‘)
Out[112]: 2
In [113]: str4.count(‘**‘,3)
Out[113]: 1
In [114]: str4.count(‘**‘,2)
Out[114]: 1
encode
将字符串编码成bytes格式。
In [13]: str2
Out[13]: ‘Defence of the Ancients is DOTA!‘
In [14]: str2.encode()
Out[14]: b‘Defence of the Ancients is DOTA!‘
endswith
检查字符串是否是以obj结束,是则返回True,否则返回False。如果beg和end指定值,则在指定范围内检查。
In [59]: str1
Out[59]: ‘#### DOTA \\n \\t ###****‘
In [67]: len(str1)
Out[67]: 27
In [74]: str1.endswith(‘***‘,22)
Out[74]: True
In [75]: str1.endswith(‘***‘,21)
Out[75]: True
In [80]: str1.endswith(‘###‘,1,24)
Out[80]: False
In [81]: str1.endswith(‘###‘,1,23)
Out[81]: True
expandtabs
把字符串 string 中的 tab 符号转为空格.
In [24]: ‘Hello\\tWorld!‘.expandtabs()
Out[24]: ‘Hello World!‘
find
检测str是否包含在string中,如果beg和end指定了范围,则检测是否包含在指定范围内,如果是返回开始的索引值,否则返回-1。
In [115]: str4
Out[115]: ‘***** DOTA dota #####‘
In [116]: str4.find(‘dota‘)
Out[116]: 14
In [4]: str4.find(‘dotaer‘)
Out[4]: -1
In [117]: str4.lower().find(‘dota‘)
Out[117]: 8
format
In [55]: ‘{} {} {}‘.format(1,2,3)
Out[55]: ‘1 2 3‘
In [56]: ‘{} {} {name}‘.format(1,2,name=‘DOTA‘)
Out[56]: ‘1 2 DOTA‘
In [70]: ‘{} {name} {}‘.format(1,2,3,name=‘DOTA‘)
Out[70]: ‘1 DOTA 2‘
In [63]: ‘{1} {0} {name}‘.format(1,2,name=‘DOTA‘)
Out[63]: ‘2 1 DOTA‘
In [67]: ‘{name} {0} {2}‘.format(1,2,3,name=‘DOTA‘)
Out[67]: ‘DOTA 1 3‘
index
返回指定字符在字符串中的下标值。
In [9]: str4
Out[9]: ‘***** DOTA dota #####‘
In [10]: str4.index(‘dota‘)
Out[10]: 14
isalnum
如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
isalpha
如果 string 至少有一个字符并且所有字符都是字母则返回 True,
否则返回 False
isdecimal
如果 string 只包含十进制数字则返回 True 否则返回 False
isdigit
如果 string 只包含数字则返回 True 否则返回 False
isidentifier
检测一段字符串可否被当作标志符,即是否符合变量命名规则
islower
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
isnumeric
如果 string 中只包含数字字符,则返回 True,否则返回 False
isspace
如果 string 中只包含空格,则返回 True,否则返回 False
istitle
如果 string 是标题化的(见 title())则返回 True,否则返回 False
isupper
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
大小写转化通常用在做比较得时候,当我们需要忽略大小写比较时, 通常统一转化为全部大写或者全部小写再做比较:
In [108]: str2.lower().upper()
Out[108]: ‘DEFENCE OF THE ANCIENTS IS DOTA!‘
In [109]: str2.upper().lower()
Out[109]: ‘defence of the ancients is dota!‘
join
以string作为分隔符,将seq中所有的元素(字符串表示)合并成为一个新的字符串。
In [6]: str2=[‘Defence‘,‘of‘,‘the‘,‘Ancients‘]
In [7]: ‘ ‘.join(str2)
Out[7]: ‘Defence of the Ancients‘
ljust
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
In [117]: str2.ljust(88)
Out[117]: ‘Defence of the Ancients is DOTA! ‘
In [119]: str2.ljust(88,‘$‘)
Out[119]: ‘Defence of the Ancients is DOTA!$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$‘
lower
转换string中所有大写字符为小写。
lstrip
去除string中左边指定的字符,和strip格式一样,但是只是去除左边的。
In [34]: str1=‘\\f #### DOTA \\n \\t ###****‘
In [35]: str1.lstrip()
Out[35]: ‘#### DOTA \\n \\t ###****‘
In [36]: str1=‘#### DOTA \\n \\t ###****‘
In [37]: str1.lstrip(‘ #‘)
Out[37]: ‘DOTA \\n \\t ###****‘
maketrans
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
In [37]: intab = ‘aeiou‘
In [38]: outtab = ‘12345‘
In [39]: trantab = str.maketrans(intab, outtab)
In [40]: str3 = "this is string example....wow!!!"
In [41]: str3.translate(trantab)
Out[41]: ‘th3s 3s str3ng 2x1mpl2....w4w!!!‘
partition
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把字符串 string 分成一个3元素的元组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string
In [42]: str2.partition(‘is‘)
Out[42]: (‘Defence of the Ancients ‘, ‘is‘, ‘ DOTA!‘)
In [44]: str2.partition(‘DO‘)
Out[44]: (‘Defence of the Ancients is ‘, ‘DO‘, ‘TA!‘)
In [45]: str2.partition(‘DOTA‘)
Out[45]: (‘Defence of the Ancients is ‘, ‘DOTA‘, ‘!‘)
replace
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次
In [14]: str4
Out[14]: ‘***** DOTA dota #####‘
In [21]: str4.replace(‘#‘,‘*‘,1)
Out[21]: ‘***** DOTA dota *####‘
In [22]: str4.replace(‘#‘,‘*‘,2)
Out[22]: ‘***** DOTA dota **###‘
rfind
类是find()方法,不过是从右开始查找。
rindex
类似于 index(),不过是从右边开始
rjust
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
rpartition
类似于 partition()函数,不过是从右边开始查找
rsplit
以str为分隔符切片string,如果num有指定值,则仅分隔num个字符串。分隔从右边开始。
rstrip
去除string中右边指定的字符,和strip格式一样,但是只是去除右边的。
split
以str为分隔符切片string,如果num有指定值,则仅分隔num个字符串。分隔从左边开始。
In [32]: str2
Out[32]: ‘Defence of the Ancients is DOTA!‘
In [33]: str2.split()
Out[33]: [‘Defence‘, ‘of‘, ‘the‘, ‘Ancients‘, ‘is‘, ‘DOTA!‘]
In [35]: str2.split(‘is‘,1)
Out[35]: [‘Defence of the Ancients ‘, ‘ DOTA!‘]
In [36]: str2.split(‘is‘,2)
Out[36]: [‘Defence of the Ancients ‘, ‘ DOTA!‘]
In [46]: str2.split(‘ ‘,-1)
Out[46]: [‘Defence‘, ‘of‘, ‘the‘, ‘Ancients‘, ‘is‘, ‘DOTA!‘]
In [47]: str2.split(‘ ‘,1)
Out[47]: [‘Defence‘, ‘of the Ancients is DOTA!‘]
In [48]: str2.split(‘ ‘,2)
Out[48]: [‘Defence‘, ‘of‘, ‘the Ancients is DOTA!‘]
In [49]: str2.split(‘ ‘,-2)
Out[49]: [‘Defence‘, ‘of‘, ‘the‘, ‘Ancients‘, ‘is‘, ‘DOTA!‘]
splitlines
按照行分隔,返回一个包含各行作为元素的列表,如果num指定则仅切片num行。
In [58]: str3
Out[58]: ‘Defence of the\\nAncients is\\nDOTA!‘
In [59]: str3.splitlines()
Out[59]: [‘Defence of the‘, ‘Ancients is‘, ‘DOTA!‘]
startswith
检查字符串是否是以obj开头,是则返回True,否则返回False。如果beg和end指定值,则在指定范围内检查。
In [42]: str1
Out[42]: ‘#### DOTA \\n \\t ###****‘
In [43]: str1.startswith(‘#‘)
Out[43]: True
In [44]: str1.startswith(‘####‘)
Out[44]: True
In [45]: str1.startswith(‘#####‘)
Out[45]: False
In [52]: str1.startswith(‘DOTA‘,6)
Out[52]: True
strip
出去string字符串中最左边和最右边chars字符,不写chars则清楚空格、\\n、\\r、\\r\\n、\\v or \\x0b、\\f or \\x0c、\\x1c、\\x1d、\\x1e、\\x85、\\u2028、\\u2029,若填写字符则清楚指定的字符,填写字符可以为多个。
In [28]: str1=‘\\f \\x1e #### DOTA ## **** \\n \\t \\r \\x1c ‘
In [29]: str1.strip()
Out[29]: ‘#### DOTA ## ****‘
In [21]: str1=‘#### DOTA \\n \\t ###****‘
In [22]: str1.strip(‘*#‘)
Out[22]: ‘ DOTA \\n \\t ‘
In [31]: str1.strip(‘*#D‘)
Out[31]: ‘ DOTA \\n \\t ‘
In [32]: str1.strip(‘*# ‘)
Out[32]: ‘DOTA \\n \\t‘
swapcase
翻转string中的大小写字母。
In [110]: str2.swapcase()
Out[110]: ‘dEFENCE OF THE aNCIENTS IS dota!‘
title
返回“标题化”的string,就是说所有单词都是以大写开始,其余字母均为小写。
In [90]: str2.title()
Out[90]: ‘Defence Of The Ancients Is Dota!‘
translate
根据 str 给出的表(包含 256 个字符)转换 string 的字符,
要过滤掉的字符放到 del 参数中
upper
转换string中的小写字母为大写。
zfill
返回长度为width的字符串,原字符串string右对齐,前面填充0
In [126]: str2.zfill(88)
Out[126]: ‘00000000000000000000000000000000000000000000000000000000Defence of the Ancients is DOTA!‘
字典
增加/修改
In [12]: d
Out[12]: {‘a‘: 11, ‘b‘: 2}
In [15]: d[‘c‘]=3
In [16]: d
Out[16]: {‘a‘: 11, ‘b‘: 2, ‘c‘: 3}
In [18]: d.update({‘d‘:4,‘e‘:5})
In [19]: d
Out[19]: {‘a‘: 11, ‘b‘: 2, ‘c‘: 3, ‘d‘: 4, ‘e‘: 5}
In [20]: d.update([(‘f‘,6),(‘g‘,7)])
In [21]: d
Out[21]: {‘a‘: 11, ‘b‘: 2, ‘c‘: 3, ‘d‘: 4, ‘e‘: 5, ‘f‘: 6, ‘g‘: 7}
In [22]: d.update(h=8)
In [23]: d
Out[23]: {‘a‘: 11, ‘b‘: 2, ‘c‘: 3, ‘d‘: 4, ‘e‘: 5, ‘f‘: 6, ‘g‘: 7, ‘h‘: 8}
In [24]: d.update(b=22)
In [25]: d
Out[25]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 3, ‘d‘: 4, ‘e‘: 5, ‘f‘: 6, ‘g‘: 7, ‘h‘: 8}
In [27]: d.update([(‘c‘,33),(‘d‘,44)])
In [28]: d
Out[28]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 5, ‘f‘: 6, ‘g‘: 7, ‘h‘: 8}
In [30]: d.update({‘e‘:55,‘f‘:66})
In [31]: d
Out[31]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7, ‘h‘: 8}
删除
In [31]: d
Out[31]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7, ‘h‘: 8}
In [32]: d.pop(‘h‘) ## 标准删除
Out[32]: 8
In [33]: d
Out[33]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7}
In [36]: d.pop(‘i‘,-1) ## 指定删除报错的返回值
Out[36]: -1
In [38]: d.popitem() ## 随机删除
Out[38]: (‘d‘, 44)
In [39]: d
Out[39]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7}
In [40]: d.clear() ## 情况字典
In [41]: d
Out[41]: {}
访问
In [43]: d
Out[43]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7}
In [44]: d[‘b‘]
Out[44]: 22
In [46]: d.get(‘a‘)
Out[46]: 11
In [48]: d.get(‘i‘,-1) ## 如果访问的不存在则指定返回值
Out[48]: -1
In [65]: d.setdefault(‘i‘,-1)## 如果访问的键不存在则赋值
Out[65]: -1
In [66]: d
Out[66]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7, ‘i‘: -1}
In [67]: d.setdefault(‘a‘,-1) ## 如访问的键存在则返回其值
Out[67]: 11
In [68]: d
Out[68]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33, ‘d‘: 44, ‘e‘: 55, ‘f‘: 66, ‘g‘: 7, ‘i‘: -1}
遍历
In [20]: d={‘a‘: 11, ‘b‘: 22, ‘c‘: 33}
In [21]: d.keys() ## 返回一个包含字典中键的列表
Out[21]: dict_keys([‘a‘, ‘b‘, ‘c‘])
In [25]: for i in d.keys():
....: print(‘{} => {}‘.format(i,d[i]))
....:
a => 11
b => 22
c => 33
In [35]: d.items() ## 返回一个包含字典中键、值对元组的列表。
Out[35]: dict_items([(‘a‘, 11), (‘b‘, 22), (‘c‘, 33)])
In [36]: for k,v in d.items():
....: print(‘{} => {}‘.format(k,v))
....:
a => 11
b => 22
c => 33
In [38]: d
Out[38]: {‘a‘: 11, ‘b‘: 22, ‘c‘: 33}
In [39]: for k in d:
....: print(k)
....:
a
b
c
## 遍历序列中的元素以及它们的下标
In [41]: for k,v in enumerate(d):
....: print(‘{} => {}‘.format(k,v))
....:
0 => a
1 => b
2 => c
集合
访问
In [16]: s = set(‘dota‘)
In [17]: s
Out[17]: {‘a‘, ‘d‘, ‘o‘, ‘t‘}
In [18]: ‘a‘ in s
Out[18]: True
In [19]: for i in s:
....: print(i)
t
d
a
o
更改
In [7]: s = set(‘dota‘)
In [8]: s
Out[8]: {‘a‘, ‘d‘, ‘o‘, ‘t‘}
In [9]: t = frozenset(‘dota‘)
In [10]: t ## 不可变集合
Out[10]: frozenset({‘a‘, ‘d‘, ‘o‘, ‘t‘})
In [11]: type(s)
Out[11]: set
In [12]: type(t)
Out[12]: frozenset
In [13]: s.add(‘er‘)
In [14]: s
Out[14]: {‘a‘, ‘d‘, ‘er‘, ‘o‘, ‘t‘}
In [15]: t.
t.copy t.difference t.intersection t.isdisjoint t.issubset t.issuperset t.symmetric_difference t.union
In [23]: s.add(‘er‘)
In [24]: s
Out[24]: {‘a‘, ‘d‘, ‘er‘, ‘o‘, ‘t‘}
In [5]: s.add(‘a‘)
In [6]: s
Out[6]: {‘a‘, ‘d‘, ‘er‘, ‘o‘, ‘t‘}
In [7]: s.update((‘e‘,‘r‘)) ## 只能添加一个元素,并且添加的元素是无序的
In [8]: s
Out[8]: {‘a‘, ‘d‘, ‘e‘, ‘er‘, ‘o‘, ‘r‘, ‘t‘}
In [9]: s.update([‘i‘,‘b‘]) ## 添加一组元素,这组元素可以是任意个
In [10]: s
Out[10]: {‘a‘, ‘b‘, ‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘o‘, ‘r‘, ‘t‘}
In [11]: s.update({‘d‘,‘z‘}) ## 元素一旦元素已经存在,集合不会发生任何改变。
In [12]: s
Out[12]: {‘a‘, ‘b‘, ‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘o‘, ‘r‘, ‘t‘, ‘z‘}
删除
In [18]: s
Out[18]: {‘a‘, ‘b‘, ‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘o‘, ‘r‘, ‘t‘, ‘z‘}
In [19]: s.remove(‘a‘) ## 删除指定元素如果元素没有会报错
In [20]: s
Out[20]: {‘b‘, ‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘o‘, ‘r‘, ‘t‘, ‘z‘}
In [22]: s.discard(‘g‘) ## 删除指定元素如果元素没有不会报错
In [23]: s.discard(‘o‘)
In [24]: s
Out[24]: {‘b‘, ‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘r‘, ‘t‘, ‘z‘}
In [25]: s.pop() ## 删除任意的元素
Out[25]: ‘b‘
In [26]: s
Out[26]: {‘d‘, ‘e‘, ‘er‘, ‘i‘, ‘r‘, ‘t‘, ‘z‘}
In [28]: s.clear() ## 清除
In [29]: s
Out[29]: set()
集合运算
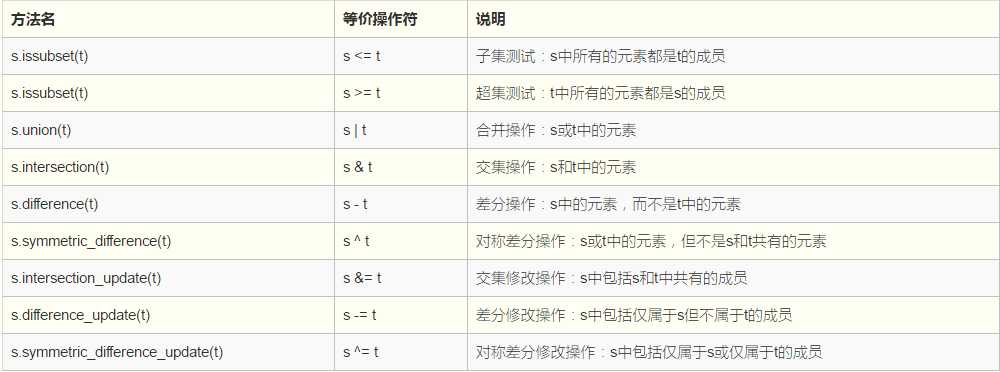
文件操作
打开模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
方法
| 方法 | 描述 |
|---|---|
| fp.read([size]) | size为读取的长度,以byte为单位 |
| fp.readline([size]) | 读一行,如果定义了size,有可能返回的只是一行的一部分 |
| fp.readlines([size]) | 把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 |
| fp.write(str) | 把str写到文件中,write()并不会在str后加上一个换行符 |
| fp.writelines(seq) | 把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。 |
| fp.close() | 关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError |
| fp.closed | 表示文件已经被关闭,否则为False |
| fp.mode | 文件打开时使用的访问模式 |
| fp.encoding | 文件所使用的编码 |
| fp.name | 文件名 |
| fp.flush() | 把缓冲区的内容写入硬盘 |
| fp.fileno() | 返回一个长整型的"文件标签" |
| fp.isatty() | 文件是否是一个终端设备文件(unix系统中的) |
| fp.tell() | 返回文件操作标记的当前位置,以文件的开头为原点 |
| fp.next() | 返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。 |
| fp.seek(offset[,whence]) | 将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。 |
| fp.truncate([size]) | 把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。 |
with语法
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open(‘log‘,‘r‘) as f:
...
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open(‘log1‘) as obj1, open(‘log2‘) as obj2:
pass
函数
函数参数
- 形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
- 实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
位置参数
位置参数必须以在被调用函数中定义的准确顺序来传递。另外,没有任何默认参数的话,传入函数(调用)参数的准确数目必须和声明的数字一致。
In [1]: def less(x,y):
...: return(x-y)
In [2]: less(2,3)
Out[2]: -1
In [3]: less(3,2)
Out[3]: 1
默认参数
如果在函数调用时没有为参数提供值则使用预先定义的默认值这就是默认参数。默认参数定义在函数声明时在标题行中给出,语法:参数名等号默认值。定义之后说明如果没有值传递给那个位置参数,那么这个参数将取默认值。
Python中用声明变默认参数语法是:所有的位置参数必须出现在任何一个默认参数之前。
In [4]: def net_conn(user,host,port=12345,passwd=‘qwert‘):
...: pass
In [5]: net_conn(‘root‘,‘192.168.2.3‘)
In [7]: net_conn(‘root‘,‘192.168.2.3‘,3456)
In [8]: net_conn(‘root‘,‘192.168.2.3‘,‘adadad‘)
In [9]: net_conn(‘root‘,‘192.168.2.3‘,30000,‘adadada‘)
上面的例子进行传递参数有正确也有错误的,第一个进行传参是正确的,后面没有填写的port和passwd会使用默认参数。第二个也是正确的,这种会更改默认的12345端口。第三个是错误的,这种本身是想更改密码,由于参数是按顺序传递的则会把密码的参数传递给port中。第四个是正确的,这种会将端口和密码都会更改。同时在上面的例子中由于user和host是没有默认值的所以必须要填写参数。
关键字参数
关键字参数仅仅针对函数的调用。他是让调用者通过函数调用中的参数名字来区分参数。这样操作就允许参数缺失或者不按顺序,因为解释器能通过给出的关键字来匹配参数的值。
In [39]: def net_conn(user,host=‘192.168.0.23‘,port=45678,passwd=‘qwert‘):
....: pass
In [40]: net_conn(‘root‘)
In [41]: net_conn(‘root‘,port=3456)
In [42]: net_conn(‘root‘,passwd=‘qazwsx‘,host=‘192.168.0.24‘)
可变位置参数(元组)
当函数被调用的时候,所有的形参(必须的和默认的)都将值赋给了在函数声明中想对应的局部变量。剩下的非关键字参数按顺序插入到一个元组中便于访问。
可变位置参数是一个元组,其必须放在位置和默认参数之后,其语法如下:
def function_name([formal_args,] *vargs_tuple):
‘function_documentation_string‘
function_body_suite
*号操作符之后的形参将做为元组传递给函数。元组保存了所有传递给函数的“额外”参数(匹配了所有位置和关键字参数后剩余的)。如果没有给出额外的参数,元组为空。
In [1]: def fn(arg1,arg2=‘a‘,*arg3):
...: print(‘arg1= ‘,arg1)
...: print(‘arg2= ‘,arg2)
...: for x in arg3:
...: print(‘arg3= ‘,x)
In [3]: fn(‘a‘)
arg1= a
arg2= a
In [4]: fn(‘a‘,‘b‘)
arg1= a
arg2= b
In [10]: fn(‘a‘,‘b‘,‘c‘,‘d‘,‘e‘)
arg1= a
arg2= b
arg3= c
arg3= d
arg3= e
可变关键字参数
可变关键字参数使用**定义,在函数体内,可变关键字参数是一个字典。可变关键字参数的key都是字符串,并且符合标示符定义规范。
In [17]: def fn1(arg1,arg2=‘a‘,**arg3):
....: print(arg1)
....: print(arg2)
....: print(arg3)
In [19]: fn1(1,2,arg3=4,arg4=5)
1
2
{‘arg3‘: 4, ‘arg4‘: 5}
In [20]: fn1(1,arg3=4,arg4=5)
1
a
{‘arg3‘: 4, ‘arg4‘: 5}
注意
- 可变位置参数只能以位置参数的形式调用
- 可变关键字参数只能以关键字参数的形式调用
同时两者是可以结合在一块使用的,下面就两者结合使用举例:
In [27]: def fn2(x,y=4,*arg1,**arg2):
print(x)
print(y)
print(arg1)
print(arg2)
In [28]: fn2(1,2,3,4,5,a=1,b=3)
1
2
(3, 4, 5)
{‘b‘: 3, ‘a‘: 1}
In [29]: fn2(1,a=1,b=3)
1
4
()
{‘b‘: 3, ‘a‘: 1}
在函数定义时可以有位置参数、默认参数、可变位置参数和可变关键字参数,这四个可以混合使用,但是为了避免出错和提高代码的可读性一般会遵循以下要求:
- 可变参数后置
- 可变参数不和默认参数一起出现
- 可变位置参数必须在可变关键字参数之前
参数解构
在函数的调用时除了可以用关键字参数还可以使用参数的解构,而参数解构发生在函数调用时。传参的顺序:位置参数,线性结构解构,关键字参数,字典解构。解构的时候, 线性结构的结构是位置参数,字典解构是关键字参数。
*可以把线性结构解包成位置参数
In [43]: def fn5(a,b,c,*arg):
....: print(a,b,c)
In [44]: lst2=[1,2,3,4,5,6]
In [45]: fn5(*lst2)
1 2 3
**可以把字典解构成关键字参数
In [49]: def fn(a, b, c, *args, **kwargs):
....: print(a,b,c)
In [50]: d
Out[50]: {‘a‘: 1, ‘b‘: 2, ‘c‘: 3, ‘d‘: 4}
In [51]: fn(**d)
1 2 3
生成器
生成器函数是一个带yield语句的函数。一个函数或者子程序只能返回一次,但一个生成器能暂停执行并返回一个中间的结果,这就是yield的功能,返回一个值给调用者并暂停执行。当生成器被next()方法调用的时候,它会准确的从离开地方继续。
In [54]: def fn1():
ret =1
index=1
while True:
yield ret
index += 1
ret *= index
In [55]: g1=fn1()
In [56]: next(g1)
Out[56]: 1
In [57]: next(g1)
Out[57]: 2
In [58]: next(g1)
Out[58]: 6
In [59]: next(g1)
Out[59]: 24
In [60]: next(g1)
Out[60]: 120
def g(n):
def factorial():
ret = 1
idx = 1
while True:
yield ret
idx += 1
ret *= idx
gen = factorial()
for _ in range(n-1):
next(gen)
return next(gen)
In [63]: fn2(5)
Out[63]: 120
In [64]: fn2(6)
Out[64]: 720
列表传参
在Python3 中使用:
In [1]: lst = [1,2,3,4,5,7,9]
In [5]: def gen1(lst):
...: yield from lst
In [6]: g1=gen1(lst)
In [7]: for j in g1:
...: print(j)
1
2
3
4
5
7
9
装饰器
有点复杂这里不做介绍。
解析式
列表解析
列表解析式是将一个列表(实际上适用于任何可迭代对象(iterable))转换成另一个列表的工具。在转换过程中,可以指定元素必须符合一定的条件,才能添加至新的列表中,这样每个元素都可以按需要进行转换。
- 列表解析返回的是列表, 列表的内容是表达式执行的结果
- 列表解析的精髓就在第一个的for循环,所以第一个必须是for循环语句
- 解析式速度更快
- 代码更简洁
- 可读性
说明
列表解析的一般形式和其等价形式
[expr for item in itratorable] ==>
ret = []
for item in itratorable
ret.append(item)
使用
In [2]: [ x ** 0.5 for x in range(5)]
Out[2]: [0.0, 1.0, 1.4142135623730951, 1.7320508075688772, 2.0]
In [8]: lst = []
In [9]: for x in range(5):
...: lst.append(x ** 0.5)
In [10]: lst
Out[10]: [0.0, 1.0, 1.4142135623730951, 1.7320508075688772, 2.0]
带if语句的列表解析:
[expr for item in iterable if cond] =>
ret = []
for item in iterable:
if cond:
ret.append(expr)
实际使用:
In [11]: [ x ** 0.5 for x in range(10) if x % 2 == 0]
Out[11]: [0.0, 1.4142135623730951, 2.0, 2.449489742783178, 2.8284271247461903]
In [12]: lst = []
In [13]: for i in range(10):
....: if i % 2 == 0:
....: lst.append(i ** 0.5)
In [14]: lst
Out[14]: [0.0, 1.4142135623730951, 2.0, 2.449489742783178, 2.8284271247461903]
带两个if语句的使用:
[expr for item in iterable if cond1 if cond2] =>
ret = []
for item in iterable:
if cond1:
if cond2:
ret.append(expr)
实际使用:
In [15]: [ x for x in range(20) if x % 2 ==1 if x < 10 ]
Out[15]: [1, 3, 5, 7, 9]
In [16]: lst = []
In [17]: for x in range(20):
....: if x % 2 ==1:
....: if x < 10:
....: lst.append(x)
In [18]: lst
Out[18]: [1, 3, 5, 7, 9]
两个for语句的列表解析:
[expr for item1 in iterable1 for item2 in iterable2] =>
ret = []
for item1 in iterable1:
for item2 in iterable2:
ret.append(expr)
实际使用:
In [19]: [(x,y) for x in range(3) for y in range(2)]
Out[19]: [(0, 0), (0, 1), (1, 0), (1, 1), (2, 0), (2, 1)]
In [20]: lst = []
In [25]: for x in range(3):
....: for y in range(2):
....: lst.append((x,y))
....:
In [26]: lst
Out[26]: [(0, 0), (0, 1), (1, 0), (1, 1), (2, 0), (2, 1)]
在上面的使用中我们可以看到只要第一个是for语句剩下的语句可以是一个或多个if语句也可以是一个或多个for语句。总之合理的使用列表解析能够很好的提高代码的可读性,同时也能提高性能。
In [27]: [(x,y) for x in range(3) if x % 2 == 1 for y in range(2)]
Out[27]: [(1, 0), (1, 1)]
In [28]: lst = []
In [29]: for x in range(3):
....: if x % 2 == 1:
....: for y in range(2):
....: lst.append((x,y))
....:
In [30]: lst
Out[30]: [(1, 0), (1, 1)]
以上是关于Python基础.md的主要内容,如果未能解决你的问题,请参考以下文章