Selenium + Python3 爬虫
准备工作
Chrome驱动下载地址(可正常访问并下载),根据自己chrome的版本下载
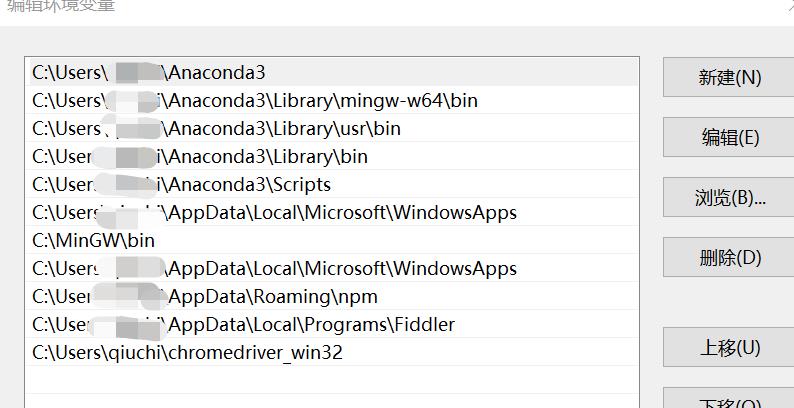
下载后解压并配置环境变量到path中,配置环境变量后建议重启系统以便生效。
安装Selenium库
如果你用的pip,执行
pip install Selenium
但是我用的是Anconda
conda install Selenium
开始爬虫
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
driver = webdriver.Chrome()
driver.get("https://www.jianshu.com")
try:
titles = driver.find_elements_by_class_name(\'title\')
for ti in titles:
print(ti.text)
print(\'\\n-----------------\')
except NoSuchElementException as e:
print(e)
finally:
driver.close()