Python多进程爬虫东方财富盘口异动数据+Python读写Mysql与Pandas读写Mysql效率对比
Posted 麦小秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python多进程爬虫东方财富盘口异动数据+Python读写Mysql与Pandas读写Mysql效率对比相关的知识,希望对你有一定的参考价值。
1、先上个图看下网页版数据、mysql结构化数据
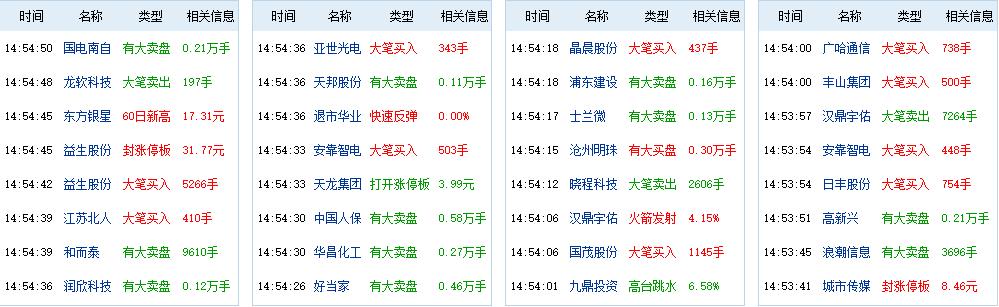
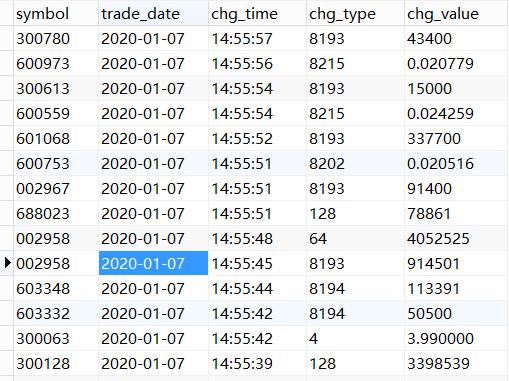
2、分析思路:
该网页主要采用动态加载来实现的,通过刷新页面查看URL,最终发现想要的数据,在js链接当中,进行头文件分析,构造URL,完成数据获取
数据存储方式上,尝试了Python单条读写mysql、利用Pandas构造DataFrame存储,2种方式,通过实验发现:通过Python读写mysql执行时间为:1477s,而通过Pandas读写
mysql执行时间为:47s,方法2速度几乎是方法1的30倍。在于IO读写上,Python多线程显得非常鸡肋,具体分析可参考:https://cuiqingcai.com/3325.html
具体代码及数据如下:
Python读写Mysql
# -*- coding: utf-8 -*-
import pandas as pd
import tushare as ts
import pymysql
import time
import requests
import json
from multiprocessing import Pool
import traceback
# ====================东方财富个股盘口异动数据抓取============================================================================================================
def EMydSpider(param_list):
# 抓取东财个股盘口异动数据:http://quote.eastmoney.com/changes
# 创建计数器
success, fail = 0, 0
# 获取当天日期
cur_date = time.strftime("%Y%m%d", time.localtime())
# 创建MySQL连接对象
conn_mysql = pymysql.connect(user=\'root\', password=\'123456\', database=\'stock\', charset=\'utf8\')
cursor = conn_mysql.cursor()
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.5.3738.400"}
url = "http://push2ex.eastmoney.com/getAllStockChanges?type=8201,8202,8193,4,32,64,8207,8209,8211,8213,8215,8204,8203,8194,8,16,128,8208,8210,8212,8214,8216"
session = requests.Session()
for param in param_list:
try:
html = json.loads(session.get(url=url, params=param, headers=header).text)
allstock = html[\'data\'][\'allstock\']
for stock in allstock:
stk_code = stock[\'c\'] # 股票代码,无后缀
stk_name = stock[\'n\'] # 股票名称
chg_time = stock[\'tm\'] # 异动时间
chg_type = stock[\'t\'] # 异动类型
chg_value = stock[\'i\'] # 异动值
try:
sql = \'\'\'insert into stock_yd_list(stk_code,trade_date,chg_time,chg_type,chg_value) values(\'%s\',\'%s\',\'%s\',\'%s\',\'%s\')\'\'\' % (stk_code, cur_date, chg_time, chg_type, chg_value)
cursor.execute(sql)
conn_mysql.commit()
success += 1
print("东方财富盘口异动,第%d条数据存储完成......" % success)
except:
conn_mysql.rollback()
fail += 1
traceback.print_exc()
print("东方财富盘口异动,第%d条数据存储失败......" % fail)
except:
traceback.print_exc()
exit()
cursor.close()
conn_mysql.close()
print(\'当天个股盘口异动数据获取完毕,新入库数据:%d条\' % success)
print(\'当天个股盘口异动数据获取完毕,入库失败数据:%d条\' % fail)
# ====================主函数====================================================================================================================================
if __name__==\'__main__\':
print("东财异动程序开始执行")
start = time.time()
# 定义空列表
param_list = []
for page in range(0,300):
param = {"pageindex": page, "pagesize": \'64\', "ut": \'7eea3edcaed734bea9cbfc24409ed989\', "dpt": \'wzchanges\'}
param_list.append(param)
# 创建多进程
pool = Pool(processes=4)
# 开启多进程爬取东财异动数据
try:
pool.map(EMydSpider, (param_list,))
except:
print("多进程执行error")
traceback.print_exc()
end = time.time()
print(\'东财异动程序共执行%0.2f秒.\' % ((end - start)))
执行时间:
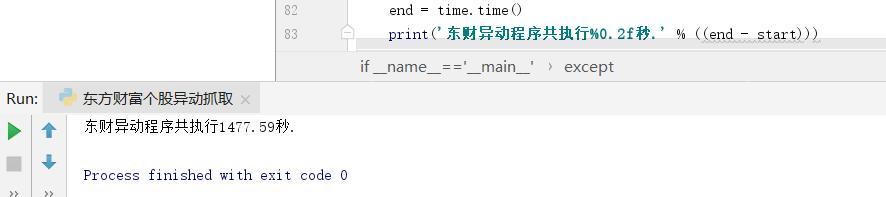
Pandas读写Mysql
# -*- coding: utf-8 -*- import pandas as pd import tushare as ts import time import requests import json from sqlalchemy import create_engine from multiprocessing import Pool from requests.packages.urllib3.exceptions import InsecureRequestWarning # ====================东方财富个股盘口异动数据抓取============================================================================================================ def EMydSpider(param_list): # 抓取东财个股盘口异动数据:http://quote.eastmoney.com/changes # 获取当天日期并创建数据库引擎 cur_date = time.strftime("%Y%m%d", time.localtime()); engine = create_engine(\'mysql://root:123456@127.0.0.1/quant?charset=utf8\') # 创建空列表、空DataFrame,分别用于存储html、异动数据 html_list = []; stock_yd = pd.DataFrame() # 分析找到真正能请求到数据的URL header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.5.3738.400"} url = "http://push2ex.eastmoney.com/getAllStockChanges?type=8201,8202,8193,4,32,64,8207,8209,8211,8213,8215,8204,8203,8194,8,16,128,8208,8210,8212,8214,8216" # 模拟发送get请求,并实例化session对象,维持会话 session = requests.Session() # 禁用安全请求警告 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) for param in param_list: try: html = json.loads(session.get(url=url, params=param, headers=header).text) html_list.append(html) print("第%s页东财个股异动数据已抓取" % (param_list.index(param) + 1)) except Exception as spider_error: print("html抓取过程报错,错误信息为:%s" % spider_error) print("--------------------------------------") print("开始抓取东方财富个股盘口异动网页数据解析") for html in html_list: try: allstock = html[\'data\'][\'allstock\'] for stock in allstock: code = stock[\'c\'] # 股票代码,无后缀 stk_name = stock[\'n\'] # 股票名称 chg_time = stock[\'tm\'] # 异动时间 chg_type = stock[\'t\'] # 异动类型 chg_value = stock[\'i\'] # 异动值 dict = {\'symbol\': code, \'trade_date\': cur_date, \'chg_time\': chg_time, \'chg_type\': chg_type, \'chg_value\': chg_value} stock_yd = stock_yd.append(dict, ignore_index=True) except Exception as parse_error: print("html解析过程报错,错误信息为:%s" % parse_error) stock_yd = stock_yd[[\'symbol\', \'trade_date\', \'chg_time\', \'chg_type\', \'chg_value\']] stock_yd.to_sql(\'disks_change\', engine, if_exists=\'append\', index = False) print(stock_yd) print("本次存储东方财富个股异动数据%s条" % stock_yd.shape[0]) # ====================主函数==================================================================================================================================== if __name__ == \'__main__\': print("东方财富个股异动爬虫程序开始执行") print("--------------------------------------") start = time.time() # 定义空列表 param_list = [] # 构建表单 for page in range(0, 300): param = {"pageindex": page, "pagesize": \'64\', "ut": \'7eea3edcaed734bea9cbfc24409ed989\', "dpt": \'wzchanges\'} param_list.append(param) # 创建线程池 pool = Pool(processes=4) # 开启多进程爬取东财异动数据 try: pool.map(EMydSpider, (param_list, )) except Exception as error: print("进程执行过程报错,错误信息为:%s"%error) end = time.time() print(\'东方财富个股异动爬虫程序共执行%0.2f秒.\' % ((end - start))) print("东方财富个股异动爬虫程序执行完成")
执行时间:
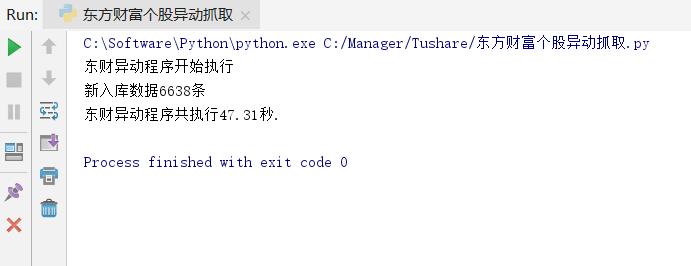
以上是关于Python多进程爬虫东方财富盘口异动数据+Python读写Mysql与Pandas读写Mysql效率对比的主要内容,如果未能解决你的问题,请参考以下文章