- Insert line
“export JMX_PORT=${JMX_PORT:-9998}”before last line in$KAFKA_HOME/bin/zookeeper-server-start.shfile. - Restart the Zookeeper server.
- Repeat steps 1 and 2 for all zookeeper nodes in the cluster.
- Insert line
“export JMX_PORT=${JMX_PORT:-9999}”before last line in$KAFKA_HOME/bin/kafka-server-start.shfile. - Restart the Kafka Broker.
- Repeat steps 4 and 5 for all brokers in the cluster.
使用 Python 监控 Kafka Consumer LAG
Posted 吱吱吱 (piperck) XD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Python 监控 Kafka Consumer LAG相关的知识,希望对你有一定的参考价值。
我在要完成这个需求的时候大概有两个思路。
第一种方法:
我们直接使用 Kafka 提供的 bin 工具,去把我们关心的 lag 值 show 出来然后通过代码处理一下报出来。例如:
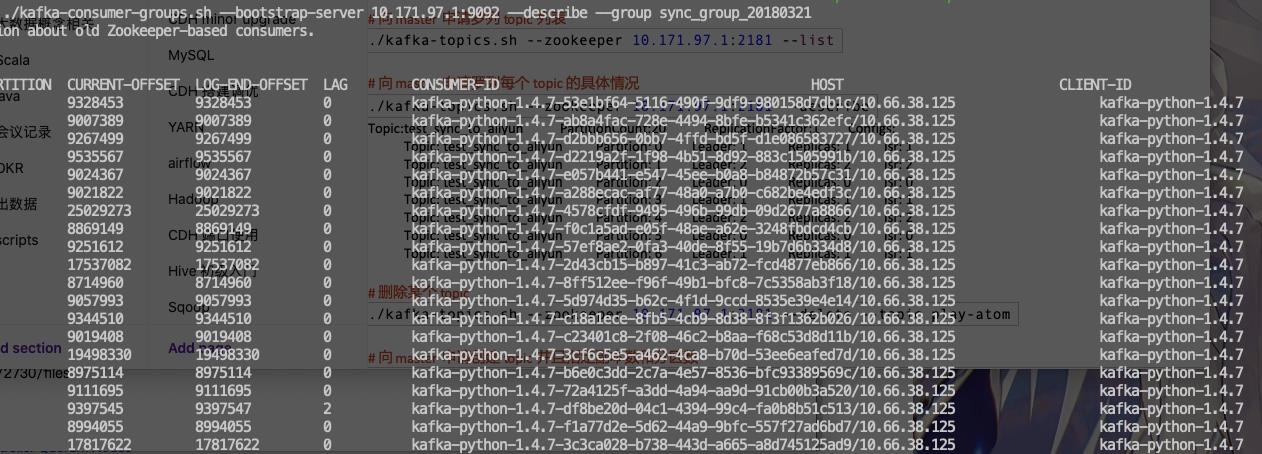
我们可以起个远程的 cmd 脚本,定期去执行 kafka-consumer-groups.sh 工具然后通过 awk \'{print $1,$2,$5}\' 拿到对应的 consumer paritions 和 lag 值,然后使用脚本稍微处理一下该报警的报警,该忽略的忽略。
这个办法很 ok 但是有个不太好的地方是他依赖去连接物理主机。很多情况下我们其实并不能访问 kafka 所在的物理主机,而只能访问到其服务。并且通过 ssh 的方法还会受各种权限的影响,所以这个方法可能对于权限很高的同学来说还不错,但是并不是很朴实的做法。
第二种方法:
思路是我们使用 Kafka 客户端库提供的 KafkaAdmin 工具来取得 Kafka 当前 topic 的高水位,然后使用当前 Topic 的高水位来减去当前消费者消费到的位置。
我其实也蛮奇怪的, Kafka-python 里面的 KafkaAdmin 工具并没有提供现成的可以直接取得 lag 的方法,而是要自己撸一个,甚至连获取高水位的方法都没有提供。。。还是去 datadog 的库里找的,并且最新的 1.4.7 版本还无法直接使用 = = 不知道其他语言的客户端是否也是这样。。
class MonitorKafkaInfra(object): """Reference: https://github.com/DataDog/integrations-core/pull/2730/files https://github.com/dpkp/kafka-python/issues/1673 https://github.com/dpkp/kafka-python/issues/1501 """ kafka_admin_client = KafkaAdminClient().kafka @classmethod def get_highwater_offsets(cls, kafka_admin_client, topics=None): """Fetch highwater offsets for topic_partitions in the Kafka cluster. Do this for all partitions in the cluster because even if it has no consumers, we may want to measure whether producers are successfully producing. No need to limit this for performance because fetching broker offsets from Kafka is a relatively inexpensive operation. Internal Kafka topics like __consumer_offsets are excluded. Sends one OffsetRequest per broker to get offsets for all partitions where that broker is the leader: https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol#AGuideToTheKafkaProtocol-OffsetAPI(AKAListOffset) Arguments: topics (set): The set of topics (as strings) for which to fetch highwater offsets. If set to None, will fetch highwater offsets for all topics in the cluster. """ highwater_offsets = {} topic_partitions_without_a_leader = set() # No sense fetching highwatever offsets for internal topics internal_topics = { \'__consumer_offsets\', \'__transaction_state\', \'_schema\', # Confluent registry topic } for broker in kafka_admin_client._client.cluster.brokers(): broker_led_partitions = kafka_admin_client._client.cluster.partitions_for_broker(broker.nodeId) # Take the partitions for which this broker is the leader and group # them by topic in order to construct the OffsetRequest. # Any partitions that don\'t currently have a leader will be skipped. partitions_grouped_by_topic = defaultdict(list) if broker_led_partitions is None: continue for topic, partition in broker_led_partitions: if topic in internal_topics or (topics is not None and topic not in topics): continue partitions_grouped_by_topic[topic].append(partition) # Construct the OffsetRequest max_offsets = 1 request = OffsetRequest[0]( replica_id=-1, topics=[ (topic, [(partition, OffsetResetStrategy.LATEST, max_offsets) for partition in partitions]) for topic, partitions in iteritems(partitions_grouped_by_topic)]) # For version >= 1.4.7, I find the ver 1.4.7 _send_request_to_node was changed future = kafka_admin_client._send_request_to_node(node_id=broker.nodeId, request=request) kafka_admin_client._client.poll(future=future) response = future.value offsets, unled = cls._process_highwater_offsets(response) highwater_offsets.update(offsets) topic_partitions_without_a_leader.update(unled) return highwater_offsets, topic_partitions_without_a_leader @classmethod def _process_highwater_offsets(cls, response): """Convert OffsetFetchResponse to a dictionary of offsets. Returns: A dictionary with TopicPartition keys and integer offsets: {TopicPartition: offset}. Also returns a set of TopicPartitions without a leader. """ highwater_offsets = {} topic_partitions_without_a_leader = set() assert isinstance(response, OffsetResponse[0]) for topic, partitions_data in response.topics: for partition, error_code, offsets in partitions_data: topic_partition = TopicPartition(topic, partition) error_type = kafka_errors.for_code(error_code) if error_type is kafka_errors.NoError: highwater_offsets[topic_partition] = offsets[0] # Valid error codes: # https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol#AGuideToTheKafkaProtocol-PossibleErrorCodes.2 elif error_type is kafka_errors.NotLeaderForPartitionError: topic_partitions_without_a_leader.add(topic_partition) elif error_type is kafka_errors.UnknownTopicOrPartitionError: pass else: raise error_type("Unexpected error encountered while " "attempting to fetch the highwater offsets for topic: " "%s, partition: %s." % (topic, partition)) assert topic_partitions_without_a_leader.isdisjoint(highwater_offsets) return highwater_offsets, topic_partitions_without_a_leader @classmethod def get_kafka_consumer_offsets(cls, kafka_admin_client, consumer_groups=None): """Fetch Consumer Group offsets from Kafka. Also fetch consumer_groups, topics, and partitions if not already specified in consumer_groups. Arguments: consumer_groups (dict): The consumer groups, topics, and partitions for which you want to fetch offsets. If consumer_groups is None, will fetch offsets for all consumer_groups. For examples of what this dict can look like, see _validate_explicit_consumer_groups(). Returns: dict: {(consumer_group, topic, partition): consumer_offset} where consumer_offset is an integer. """ consumer_offsets = {} old_broker = kafka_admin_client.config[\'api_version\'] < (0, 10, 2) if consumer_groups is None: # None signals to fetch all from Kafka if old_broker: raise BadKafkaConsumerConfiguration(WARNING_BROKER_LESS_THAN_0_10_2) for broker in kafka_admin_client._client.cluster.brokers(): for consumer_group, group_type in kafka_admin_client.list_consumer_groups(broker_ids=[broker.nodeId]): # consumer groups from Kafka < 0.9 that store their offset # in Kafka don\'t use Kafka for group-coordination so # group_type is empty if group_type in (\'consumer\', \'\'): # Typically the consumer group offset fetch sequence is: # 1. For each broker in the cluster, send a ListGroupsRequest # 2. For each consumer group, send a FindGroupCoordinatorRequest # 3. Query the group coordinator for the consumer\'s offsets. # However, since Kafka brokers only include consumer # groups in their ListGroupsResponse when they are the # coordinator for that group, we can skip the # FindGroupCoordinatorRequest. this_group_offsets = kafka_admin_client.list_consumer_group_offsets( group_id=consumer_group, group_coordinator_id=broker.nodeId) for (topic, partition), (offset, metadata) in iteritems(this_group_offsets): key = (consumer_group, topic, partition) consumer_offsets[key] = offset else: for consumer_group, topics in iteritems(consumer_groups): if topics is None: if old_broker: raise BadKafkaConsumerConfiguration(WARNING_BROKER_LESS_THAN_0_10_2) topic_partitions = None else: topic_partitions = [] # transform from [("t1", [1, 2])] to [TopicPartition("t1", 1), TopicPartition("t1", 2)] for topic, partitions in iteritems(topics): if partitions is None: # If partitions aren\'t specified, fetch all # partitions in the topic from Kafka partitions = kafka_admin_client._client.cluster.partitions_for_topic(topic) topic_partitions.extend([TopicPartition(topic, p) for p in partitions]) this_group_offsets = kafka_admin_client.list_consumer_group_offsets(consumer_group, partitions=topic_partitions) for (topic, partition), (offset, metadata) in iteritems(this_group_offsets): # when we are explicitly specifying partitions, the offset # could returned as -1, meaning there is no recorded offset # for that partition... for example, if the partition # doesn\'t exist in the cluster. So ignore it. if offset != -1: key = (consumer_group, topic, partition) consumer_offsets[key] = offset return consumer_offsets
下面我还实现了一个直接过滤关注 Topics 和 Consumer 的函数,有异常直接报给 dingding 大概是
def monitor_lag_to_dingding_client(cls, topics, consumers, warning_offsets, dingding_client): msg = \'\' warning_msg = [] # {TopicPartition(topic=u\'online-events\', partition=49): (314735, u\'illidan-c\')} consumer_offsets_dict = {} # {TopicPartition(topic=u\'online-events\', partition=48): 314061} highwater_offsets_dict, _ = MonitorKafkaInfra.get_highwater_offsets(MonitorKafkaInfra.kafka_admin_client, topics) [consumer_offsets_dict.update({TopicPartition(i[0][1], i[0][2]): (i[1], i[0][0])}) for i in MonitorKafkaInfra.get_kafka_consumer_offsets(MonitorKafkaInfra.kafka_admin_client).items() if i[0][0] in consumers] for i in highwater_offsets_dict.items(): key, offsets = i[0], i[1] if offsets - consumer_offsets_dict[key][0] > warning_offsets: # WARNING warning_msg.append(u"Consumer: {} \\n" u"Topic: {} \\n" u"Partition {} \\n" u"OVER WARNING OFFSETS {} \\n" u"If it not expected. Please check「KAFKA MANAGER」right now\\n\\n ".format( consumer_offsets_dict[key][1], key.topic, key.partition, offsets - consumer_offsets_dict[key][0])) for i in warning_msg: msg += i dingding_client.request_to_text(msg)
这两段代码值得注意的一个地方就是第一段代码里面的
# For version >= 1.4.7, I find the ver 1.4.7 _send_request_to_node was changed future = kafka_admin_client._send_request_to_node(node_id=broker.nodeId, request=request) kafka_admin_client._client.poll(future=future) response = future.value
_send_request_to_node 方法在最新版的客户端中有改动,需要注意一下。
另外为 kafka 开启 jmx port 可以让我们从 kafka jmx 端口中获得更多关注的信息
SettingJMX_PORTinsidebin/kafka-run-class.shwill clash with Zookeeper, if you are running Zookeeper on the same node. Best is to setJMXport individually inside correspondingserver-startscripts:
通过上述方法打开 kafka jmx 端口之后可以直接从 kafka manager 中获取更多 kafka 的运行状态和状况。 包括每秒流入流量和流出流量等,以 topic 为单位。可以帮助我们更方便的了解 kafka 目前的运行情况,评估性能,以及进行 benchmark。
Refenrece:
https://github.com/DataDog/integrations-core/pull/2730/files
https://github.com/dpkp/kafka-python/issues/1673
https://github.com/dpkp/kafka-python/issues/1501
https://stackoverflow.com/questions/36708384/how-to-enable-remote-jmx-on-kafka-brokers-for-jmxtool
https://github.com/DataDog/integrations-core/blob/master/kafka_consumer/datadog_checks/kafka_consumer/kafka_consumer.py the newest how to check offsets
以上是关于使用 Python 监控 Kafka Consumer LAG的主要内容,如果未能解决你的问题,请参考以下文章